Forecasting Competition
预测比赛代写 1 OutlineThe aim of this competition is to motivate each of you to practice basic forecasting methods in time series analysis,
1 Outline
The aim of this competition is to motivate each of you to practice basic forecasting methods in time series analysis, and to perhaps research and implement your own, more novel, methods in order to claim the distinction of STAT 443 Forecasting Champion!! You will be asked to provide forecasts/predictions in five different scenarios. Individual performance in each scenario will be ranked across competitors, and your final competition score will be your average rank in the four scenarios. As such each scenario is equally important in determining the winner. By the due date April 23rd, 11:59 pm, you must complete and turn in via Crowdmark and LEARN the following:
1. 预测比赛代写
Five comma separated files (.csv), containing your forecasts for each scenario.Detailed instructions on how to construct each file are given below. The file names for the four files should be of the form “lastname Scenario1.csv” to “lastname Scenario5.csv”, where “lastname” is replaced by your last name. These are to be submitted on LEARN (instructions on this to follow and will be posted on LEARN).
2.A report containing:
(a) A description of your models/how you produced your forecasts.
(b) Plots of the data along with your forecasts, as well as basic diagnostic ofyour model that support their effectivness/goodness of fit. In some cases I may ask specifically for certain plots to be displayed , e.g. plots of your forecasts with 95% confidence intervals. In the case of Scenario 2 you must only show plots of your forecasts for no more than 2 stocks. This is to be submitted on Crowdmark.
3. 预测比赛代写
Supporting code that is well commented and may be easily run to reproduceyour forecasts. This is to be submitted on Crowdmark.
Your report should be short (no more than 2 pages per scenario, excluding plots), and should be written as if the audience is someone with basic time series knowledge, i.e. you do not have to introduce basic time series models. It should not contain many typos, and should be easily readable. The code can be in Python, R, or MatLab. If you wish to use another language please consult with me ASAP.
Note: The data used in each scenario has been obtained from publicly available sources, but has been privitized/transformed by me to increase the difficulty of finding the source. Nonetheless, I assume that it is possible to invert my transformation and find the source data. THIS IS NOT ALLOWED! In any case, you must also submit the supporting code to reproduce your forecasts, and if this is found to include knowledge of the source data, you will be disqualified, and receive a zero for this assessment. If your method involves any randomized procedure, you must use some version of a set.seed() function so that your results are reproducible.
2 Scenario 1: Hydrological Forecast 预测比赛代写
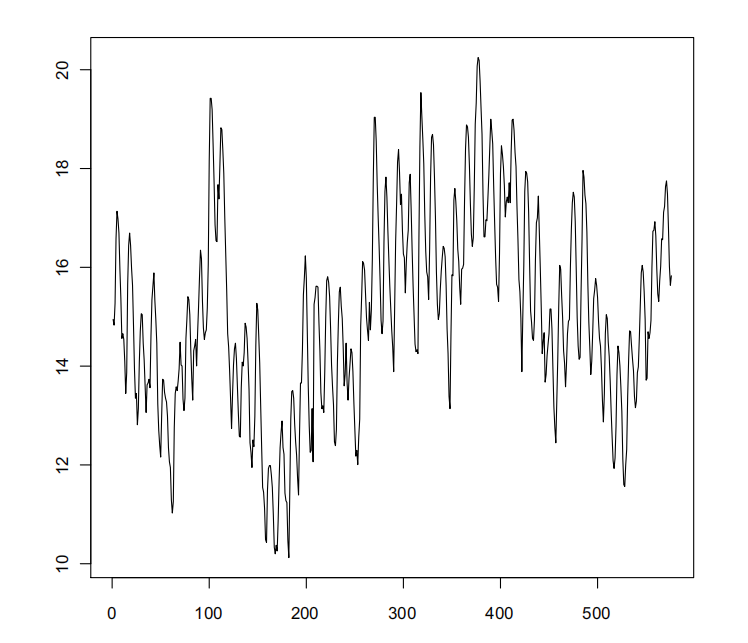
hyd post.txt contains 576 observations at a monthly resolution of the level of a body of water. Your task in this scenario is to produce 1-month to 24-month ahead forecasts of the series, as well as a 95% prediction intervals for the forecasts. If ˆxi i = 1,…24 denotes your forecast of the true levels xi i = 1,…,24, your error in this scenario will be measured by
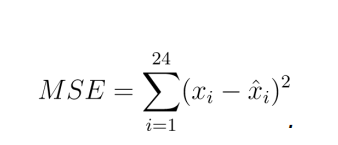
Ranking among competitors will be determined according to lowest MSE. The .csv file in this case should contain one COLUMN of length 24 containing the forecasts.
3 Scenario 2: Financial Risk Forecast 预测比赛代写
The files stock1.txt to stock40.txt each contain 150 days of daily resolution logdifferenced price data from several different stocks listed on the New York stock exchange. Your task in this scenario is to forecast (lower) 15% quantiles 10 steps ahead for each series (in other words, forcasts for Value-at-Risk). Your error will be measured as follows. Let Xi,j denote the j’th observation from the ith log-differencedseries. Letting ˆqi ,1,…,qˆi ,10 denote your quantile forecasts for the ith series, i = 1,…,20, we define
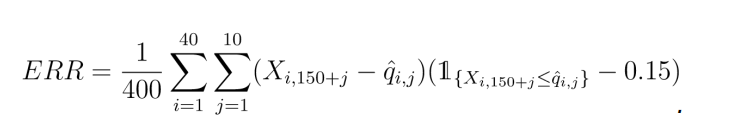
For more information on this error measure/scoring rule for quantile prediction, see Gneiting and Raftery (2007), page 370. The .csv file in this case should contain 40 COLUMNS of length 10, the ith column containing the 10 quantile forecasts for stock i.
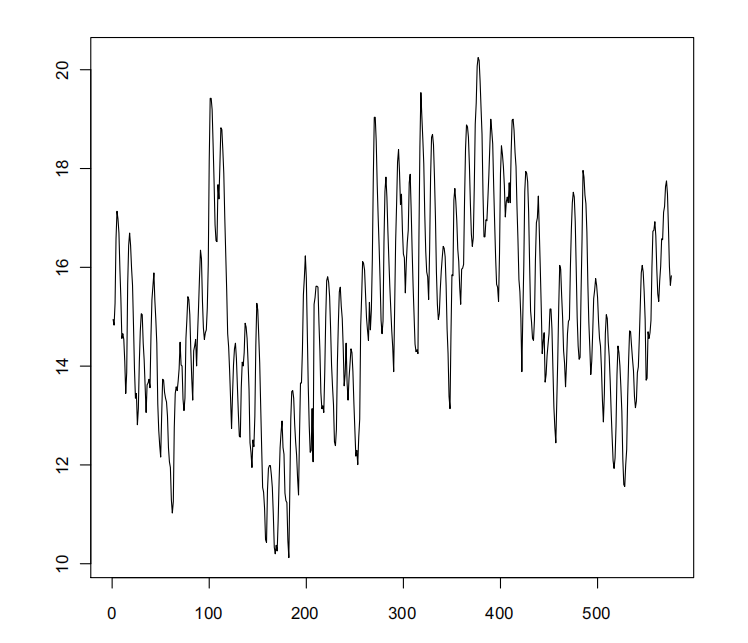
Figure 1: Hydrological time series.
4 Scenarios 3 and 4: Imputation and Multivariate 预测比赛代写
Time Series Forecasting
The file prod target.txt contains a monthly resolution time series of the amount of beer produced in Australia. 30 observations in the middle of the times series have been removed and replaced with “NA” values. Your task for these scenarios is to: 1) Impute (predict) the missing values, and 2) Forecast the series prod _target.txt 24 steps ahead. Your report should contain graphs with 95% prediction intervals (no confidence bands required in this case) for your imputations/forecasts.
You may use the series in prod _1.txt on car production, prod _2.txt on steel production, eng 1.txt on gas consumption, eng 2.txt on electricity consumption and temp.txt describing the monthly mean high temperatures, all from Australia, to improve your predictions. You may not use any additional information other than these given series. Letting ˆx1,…,xˆ30 denote the predictions of the missing values x1,…,x30, and yˆ1,…,yˆ24 the forecasts of the future 24 values of the series y1,…,y24, error will be measured in this case by
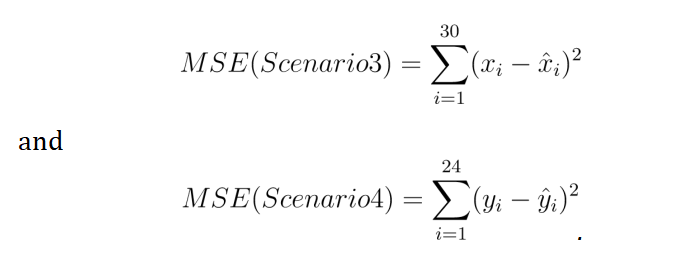
You should provide 2 .csv files for these scenarios, which should each contain respectively 1 COLUMN of length 30 and 24, in which the 30 imputed values ˆx1,…,xˆ30 are given in the file for Scenario 3, and the 24 forecasts ˆy1,…,yˆ24 are given in the file for Scenario 4. In your report also produce and plot 95% prediction intervals for each of these imputations/forecasts.
5 Scenarios 5: Long Horizon Pollution Forecasting
The files pollutionCity1.txt, pollutionCity2.txt, and pollutionCity3.txt contain standardized half hourly resolution measurements of the concentration of an air pollutant in three different cities over 53 days (time series of length 2544 for each city). Your task in this scenario is to forecast each series forward 1 to 336 half-hourly steps ahead, which corresponds to forecasting each series one week ahead, and produce 95% prediction intervals for these forecasts. If ˆxi,1,…,xˆi,366 denote your forecasts of pollution levels xi,1,…,xi,366 in City i, i = 1,2,3, then your error in this scenario will be measured by
The .csv file in this case should contain 3 COLUMNS, each with 336 rows, containing your forecasts for City i in column i. In your report also produce and plot 95% prediction intervals for each of these forecasts.
6 Grading 预测比赛代写
Your grade on this assessment will largely be determined by your report, which will be graded as follows:
- 40 % Methods implemented are clearly explained and reasonable to use in each case
- 40 % Figures and model diagnostics are clear and reasonable.
- 20 % The report is readable and contains few typos
References
[1] T. Gneiting, and A. Raftery (2007). Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association , 102, 359–377.
Figure 3: Plot of pollutionCity1 time series.

更多代写:php程序代写 北美Accountant会计quiz代考 英国财务管理论文代写 波士顿留学生essay论文代写 北美Engineering Thesis代写 贝叶斯作业代写
