期末课题推荐选题C
2020年春《统计计算》
面向电影推荐算法的矩阵填充问题研究
Statistics统计学 本选题要求你使用MovieLens数据集与矩阵填充(Matrix completion)技术[1] 构建电影推荐系统. MovieLens数据集是一组由MovieLens 用户提供的电影评分数据.数据包括电影评分、电影元数据(风格类型和年代)
问题 Statistics统计学
本选题要求你使用MovieLens数据集与矩阵填充(Matrix completion)技术[1] 构建电影推荐系统. MovieLens数据集是一组由MovieLens 用户提供的电影评分数据. 数据包括电影评分、电影元数据(风格类型和年代)以及关于用户的人口统计学数据(年龄、邮编、性别和职业等)。原始数据可从grouplens.org/datasets/movielens下载, 根据包含的数据量与评分年份的不同, 提供了不同的版本.
其中,MovieLens lastest small是最小的一组数据, 数据集包括600余名用户对9000余部电影的 1,000,000余个评分(1~5). 你可以安装R附加包dslabs在R中直接读取已清洗的该数据.
# install.packages('dslabs') # 首次运行需安装
library(dslabs)
data('movielens')
head(movielens, 3)
## movieId title year genres userId
## 1 31 Dangerous Minds 1995 Drama 1
## 2 1029 Dumbo 1941 Animation|Children|Drama|Musical 1
## 3 1061 Sleepers 1996 Thriller 1
## rating timestamp
## 1 2.5 1260759144
## 2 3.0 1260759179
## 3 3.0 1260759182
简要分析上述数据, 3~4分的评分约占总数的60%以上. Statistics统计学
round(table(movielens$rating)/length(movielens$rating),3)
## ## 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 ## 0.011 0.033 0.017 0.073 0.044 0.201 0.105 0.287 0.077 0.151
可使用R附加包reshape的cast()函数将上述数据表转换为评分矩阵, 该矩阵的第行第列表示用户对电影的评分.
# install.packages('reshape') # 首次运行需安装
library(reshape)
Z <- cast(movielens, userId~movieId, value="rating")
dim(Z)
## [1] 671 9067
该评分矩阵一般是具有强“稀疏性”(sparsity)的大矩阵. 下图空白位置对应矩阵的数据缺失.
Z <- as.matrix(Z) image(Z, col=grey.colors(10))
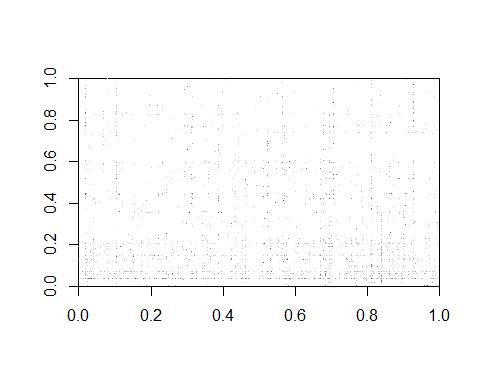
协同过滤(collaborative filtering) 对推荐系统非常有用, 它可以视为经典的低秩矩阵填充问题. 我们的目标是找到评分填充值的合理计算方法, 并将每行最高评分所对应的电影推荐给用户.

迭代SVD Statistics统计学
具体来说, 对于, 令表示中观测到的元素的索引的集合, 给定这些观测值, 一个自然的思路是可对应寻找的最低秩矩阵, 即
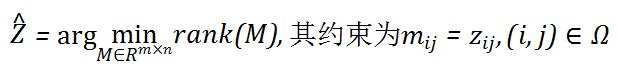
但含缺失数据的最低秩问题计算非常困难, 一般无法求解.
因此, 更常见的求解方法是允许所得到
的矩阵与观测值之间有一定误差, 即
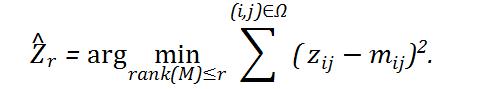
该问题是非凸优化, 通常得不到最优解, 但可以采用迭代算法来得到局部最优解[2]. 例如
- 通过对进行随机填充, 初始化;
- 通过计算的r秩SVD求解:
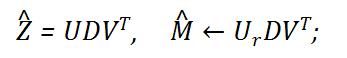
3.基于对的缺失部分进行填充:
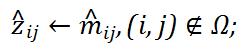
4.重复第2-3步, 直至算法收敛.
思考建议
- 将MovieLens lastest small数据集抽取75%左右的评分为训练集, 25%为测试集 (可按时间顺序; 或随机抽取).
- 利用上述迭代SVD算法, 在MovieLens lastest small数据集上实现评分填充, 分别报告该评分填充在训练集与测试集上的RMSE.
- 讨论选取不同的秩, RMSE的变化情况.
- 讨论对用于训练的数据矩阵的行和列都进行中心化或正则化, 是否会改进预测效果.
- 考虑其他的矩阵填充方法? 如, R包softImpute[3].
- 在其他MovieLens数据集上, 算法表现是否一致?
参考文献 Statistics统计学
[1] Laurent, M. (2001), Matrix completion problems, in The Encyclopedia of Optimization, Kluwer Academic, pp. 221–229. [2] Mazumder, R., Hastie, T. and Tibshirani, R. (2010), Spectral regularization algorithms for learning large incomplete matrices, Journal of Machine Learning Research 11, 2287–2322. [3] Hastie, T., Mazumder, R.. softImpute: matrix completion via iterative soft-thresholded svd, 2013. URL http://CRAN.R-project.org/ package=softImpute. R package version 1.0.——— The End ———
Ask me if anything is unclear!
Good luck! Chengcheng

更多代写:haskhell代写 Calculus代考 dissertation学术论文代写 Essay Proofreading代写机构 Finance金融论文代写 环境学论文代写
