副标题#e#
要害字 :
Pentium,处理惩罚器,单指令大都据流扩展指令,SSE,指令集
提要 :
跟着Intel Pentium III处理惩罚器的宣布,给措施设计人员又带来了很多新的特性。操作这些新特性,措施员可觉得用户缔造出更好的产物. Pentium III和Pentium III Xeon(至强处理惩罚器)的很多新特性,可以使她可以或许比Pentium II和Pentium II Xeon处理惩罚器有更快的运行速度,这些新特性包罗一个处理惩罚器序列号(unique processor ID)和新增SSE处理惩罚器指令集,这些新的指令集就像Pentium II在经典Pentium的基本上添加的MMX指令集.
在这篇文章里,我们将向你展示Pentium III处理惩罚器和她的这些新特性,而且将着重报告Pentium III处理惩罚器的新指令集.
1.Pentium III处理惩罚器提要
1999年2月,Intel宣布了她的最新款处理惩罚器Pentium III处理惩罚器,和以往的新处理惩罚器推出一样,速度的提高是最主要的机能改进.Intel在宣布她的新处理惩罚器时一贯遵循着摩尔定律,即每过18个月处理惩罚器的速度将提高一倍(the processor speed doubles every 18 months),可是Pentium III处理惩罚器的并没有比Pentium II的速度提高一倍,在Pentium II和Pentium II Xeon处理惩罚器运行在333MHz~400MHz时,Pentium III也只不外运行 在450MHz~550MHz罢了,处理惩罚器的速度并没有多大的提高,可是机能的晋升确是很明明的.
从本质上说,Pentium III处理惩罚器只不外是一个运行在更高速度的Pentium II处理惩罚器,别的再增加了一些新的指令集:Streaming SIMD Extensions(单指令大都据流扩展指令集,可能称为SSE).这些新指令集的增加并不会影响本来的措施运行,因为Pentium III处理惩罚器回收的是完全兼容于本来Pentium II处理惩罚器的IA-32构架.
假如Pentium III处理惩罚器的速度并没有比Pentium II有倍速的提高,那我们为什么还要去选购她呢?
2.Pentium III处理惩罚器的新特性
Pentium III处理惩罚器添加了两个有趣也是很有用的新特性:处理惩罚器序列号(processor serial number)和SSE指令集.由于Pentium III处理惩罚器的序列号涉及到用户隐私的争议,为了制止这种争议,在这里我们将把留意力放在Pentium III处理惩罚器的SIMD新指令集上.
SSE包括一个SIMD的首字母,SIMD是Single Instruction Multiple Data(单指令大都据)的首字母的缩写.凡是,处理惩罚器在一个指令周期只能处理惩罚一个数据,这叫做Single Instruction Single Data(单指令单数据),缩写为SIDI.和SIDI差异的是,假如处理惩罚器具有SIMD本领,那么她就可以在一个CPU指令周期同时处理惩罚多个数据.
3.MMX vs SSE
MMX和SSE都是在本来的处理惩罚器指令集的基本上添加的扩展指令集,都是SIMD(单指令大都据)指令,差异的是他们处理惩罚的数据范例差异. MMX只能在整数上支持SIMD,而SSE指令增加了单精度浮点数的SIMD支持.MMX可以举办同时对2个32位的整数操纵,而SSE可以同时对4个32位的浮点数操纵.
MMX和SSE的一个主要的区别是MMX并没有界说新的寄存器,而SSE界说了8个全新的128位寄存器,每个寄存器可以同时存放4个单精度浮点数(每个32位长),他们在寄存器中分列顺序见下图1.
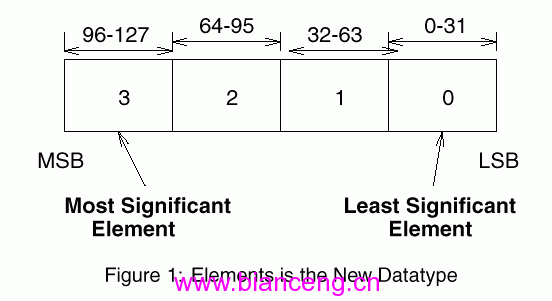
图一:新数据范例分列
这里有一个问题,既然MMX没有界说新的寄存器,那么她又有什么寄存器可操纵呢?事实上,MMX是和本来的浮点寄存器共享的.一个浮点寄存器是80位长的,她的低端64位被用做MMX的寄存器.这样,一个应用措施就不能在执行MMX指令的同时举办浮点操纵了.同时,处理惩罚器还要花掉大量的时钟周期去维护寄存器状态从MMX操纵和浮点操纵之间的切换.SSE指令集就没有这些限制了.由于她界说了全新的寄存器,应用措施可以在举办整数SIMD操纵(MMX)的同时举办浮点数的SIMD操纵(SSE),同样,SSE还可以在执行浮点数的非SIMD操纵的同时举办SIMD操纵.
MMX和SSE的寄存器分列见下图2.图2(a)是MMX和浮点数共享一个寄存器的环境,图2(b)是SSE的独立寄存器分列.

图二:MMX和SSE的寄存器
MMX和SSE寄存器有一个配合点,那就是都有8个寄存器.MMX的寄存器被定名为mm0~mm7,SSE的寄存器名字是xmm0~xmm7.
#p#副标题#e#
4.措施中的应用
Pentium III的SSE指令集是为SIMD设计的,她可以同时操纵4个单精度浮点值.因此,操作这些增强的浮点计较本领,对3D应用措施的细节表示是有实质性的提高的.事实上,SSE就是为3D应用建设的.游戏和其他的利用后端3D来显示2D和2.5D图象的措施,和利用矢量图形的应用措施一样都能分享到这种长处.
4.1 3D运算
计较机暗示的3D图形是用大量的暗示图形极点的浮点数构成的,通过操纵这些极点数据就可以改变3D图形的外观.通过利用SSE指令集,应用措施可以得到更多的辅佐,处理惩罚器可以在一个时钟周期内处理惩罚更多的数据,大大加速了3D图形的极点计较速度,可以给用户带来更深刻的3D体验.
同样,应用措施开拓者还可以用更多的极点数据和更巨大的算法来缔造出更为活跃的3D图象结果来.
#p#分页标题#e#
利用SSE指令集可以显著的改进一些在3D操纵中常常用到的计较,像矩阵乘法、矩阵调动以及矩阵之间的加、减、乘、向量矩阵相乘、矢量化、 矢量点相乘和光照计较等等.
5.单指令大都据流指令集
SSE增加了70条新的指令,同时也添加了一个状态/节制字(status/control word).SSE指令集必需要获得操纵系统的支持,支持她的操纵系统必需可以或许生存和规复这个处理惩罚器的状态字.今朝,只有Microsoft的Windows98和Windows2000支持SSE指令集.SSE界说了新的指令、新的数据范例和指令领域.
这些新添加的指令不是全部用来浮点数SIMD操纵的,在这70条新指令中,有50条是浮点数的SIMD操纵的,12条是针对整数的SIMD操纵的,尚有8条是cache操纵(cacheability )指令.在这篇文章里,我们将着重接头这50条浮点数的SIMD操纵指令.
5.1 分类
Pentium III的SIMD新指令集可以凭据差异的分类尺度获得差异的分类要领.
假如我们凭据指令的操纵数分别,可以获得"数据包装"(Data Packing)的分类要领.
假如凭据指令的行动特征分别,可以获得"指令领域"(Instruction Categories)分类要领.
假如凭据指令的计较特征分别,可以获得"指令分组"(Instruction Groups)分类要领.
5.1.1 数据包装分类
假如我们凭据指令的操纵数分别浮点数的SIMD部门,我们可以获得两个明明的分类:操纵包裹数据(packed data)的指令和操纵标量数据(scalar data)的指令.因此,我们可以获得包裹指令(packed instructions )和标量指令(scalar instructions)这两个种类.
在Pentium III指令会合,包裹指令和标量指令可以很利便的被区分出来.包裹指令的都带有"ps"前缀,而标量指令有一个"ss"前缀. SSE还界说了一个新的数据范例(data type),可以用来储存4个单精度浮点数,这个新的数据范例可以用下面的图3来暗示.图中的元素"A"包括了4 个单精度浮点数a0,a1,a2,a3.
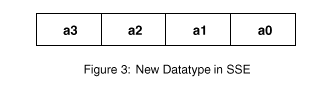
图三:SSE的新数据范例
上面的图三可以辅佐我们领略包裹指令和标量指令之间的区别.SSE的包裹指令同时操纵这个新数据范例的4个元素,而标量指令只操纵这个新数据范例的最后一个元素,其他三个元素的内容将在指令执行前后保持稳定.
图4说明白包裹指令的操纵要领.如图所示,有两个操纵数A和B,都是SSE界说的新数据范例.操纵功效将被生存在数据C.C和A、B是一样的数据范例.操纵数A有四个构成元素a0,a1,a2,a3,同样操纵数B也有四个元素b0,b1,b2,b3.下图中的op是要举办的操纵指令.
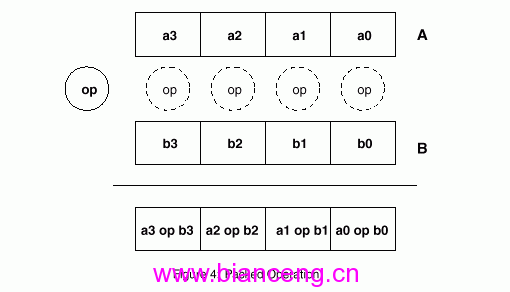
图四:包裹操纵
操纵指令是被别离浸染于A和B的四个元素的,操纵功效将被放在C的相应元素中.指令op是在同一个时间对这四个元素操纵的,并在同一个计较单位中举办计较.
一个标量指令利用和上面一样的操纵指令op,操纵数A和B,如下图5示例说明.在这里操纵指令只浸染于操纵数A和B的最后一个元素.同样,功效只储存在C的相应最后一个元素中.尚有,在这里固然只有一个元素被改变,操纵指令op仍然同时操纵所有的4个元素,而且也是在一个计较单位中举办的.
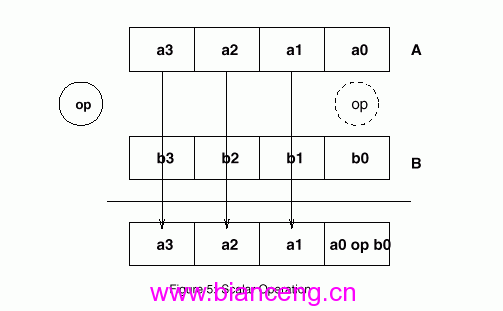
图五:标量操纵
5.1.2 指令领域分类(凭据指令行动范例分别)
SSE指令会合险些所有的包裹指令都有一个标量指令和她对应.SSE指令也可以不按操纵数分类,而是把她分成下面的几个类:
· 计较指令(computation instructions)
· 分支指令(branching instructions)
· Cache指令(cacheability instructions)
· 数据移动和排序指令(data movement and ordering instructions)
5.1.3 指令组分类(凭据指令计较特征分类)
SSE指令还可以被分成下面的几类:
· 算术指令(arithmetic instructions)
· 较量指令(comparison instructions)
· 逻辑指令(logical instructions)
· 清洗指令(shuffle instructions)
· 转换指令(conversion instructions)
· 状态操纵指令(state management instructions)
· Cache指令(cacheability instructions)
· 数据操纵指令(data management instructions)
· 附加整数指令(additional integer instructions)
5.2 利益
SSE最主要的利益是可以大大减小数据计较的指令操纵数目.假如不利用SIMD和SSE,要举办一个400次的浮点数乘法计较,需要轮回利用400次的乘法指令.而假如利用了SIMD和SSE,则只要举办100次的乘法指令就可以完成沟通的任务了,因为这里每次的乘法操纵都可以同时对4个浮点数举办计较.
