副标题#e#
1.先从一个问题说开去
C++数据范例转换的问题
#include <iostream.h>
void main()
{
int i=0xb62;
char c;
c=i;
cout<<c<<endl;
}
这里为什么输出的是b?
2.先检测一下我们所利用的电脑的CPU的字节序
版本一(有问题,功效无论如何都是34,不能说明34是高地点的照旧低地点的)
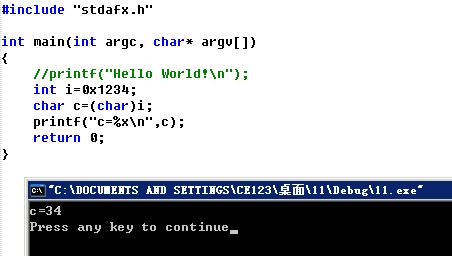
版本二(按照 shineyan1991的留言修改后获得的,在此感谢 shineyan1991的发起)

从上图可知,CPU的字节序是小端模式。
#p#副标题#e#
常识点
小端模式(Little-Endian)
数据范例中的高位数据存放于高地点部门,低位数据存放于低地点部门。简而言之:高位在后,低位在前。
大端模式(Big-Endian)
数据范例中的高位数据存放于低地点部门,低位数据存放于高地点部门。简而言之:高位在前,低位在后。
3.劈头阐明
0xb62是十六进制,因为char是一个字节的,所以我们只取低8位(扬弃了高字节,而保存了低字节),这是和语言有关,和CPU的架构无关,一个十六进制位转换为4个二进制位,所以,低8位就是62转换的,就是01100010,通报给char后,char的值就是98,按照ASCII,就会输出b。
4.强制数据范例转化
强制范例转换是通过范例转换运算来实现的。其一般形式为:(范例说明符)(表达式)其成果是把表达式的运算功效强制转换成范例说明符所暗示的范例。自动转换是在源范例和方针范例兼容以及方针范例广于源范例时产生一个范例到另一类的转换。
当操纵数的范例差异,并且不属于根基数据范例时,常常需要强制范例转换,将操纵数转化为所需要的范例。强制范例转换具有两种形式,称为显式强制转换和隐式强制范例转换。
4.1.显式强制范例转换
显式强制范例转换需要利用强制范例转换运算符,名目如下:
type(<expression>)
或
(type)<expression>
个中,type为范例描写符,如int,float等。<expression>为表达式。经强制范例转换运算符运算后,返回一个具有type范例的数值,这种强制范例转换操纵并不改变操纵数自己,运算后操纵数自己未改变,譬喻:
int nVar=0xab65; char cChar=char (nVar);
上述强制范例转换的功效是将整型值0xab65的高端两个字节删掉,将低端两个字节的内容作为char型数值赋值给变量cChar,而颠末范例转换后nVar的值并未改变。
4.2.隐式强制范例转换
隐式范例转换产生在赋值表达式和有返回值的函数挪用表达式中。在赋值表达式中,假如赋值符阁下两侧的操纵数范例差异,则将赋值符右边操纵数强制转换为赋值符左侧的范例数值后,赋值给赋值符左侧的变量。在函数挪用时,假如return后头表达式的范例与函数返回值范例差异,则在返回值时将return后头表达式的数值强制转换为函数返回值范例后,再将值返回,如:
int nVar; double dVar=3.88; nVar=dVar;//执行本句后,nVar的值为3,而dVar的值仍是3.88
4.3.在利用强制转换时应留意以下问题:
1.范例说明符和表达式都必需加括号(单个变量可以不加括号),如把(int)(x+y)写成(int)x+y则成了把x转换成int型之后再与y相加了。
2.无论是强制转换或是自动转换,都只是为了本次运算的需要而对变量的数据长度举办的姑且性转换,而不改变数听说明时对该变量界说的范例。
3.假如一个运算符双方的运算数范例差异,先要将其转换为沟通的范例,即较低范例转换为较高范例,然后再介入运算,转换法则如下图所示。
double ←── float 高
↑
long
↑
unsigned
↑
int ←── char,short 低
图中横向箭头暗示必需的转换,如两个float型数介入运算,固然它们范例沟通,但仍要先转成double型再举办运算,功效亦为double型。 纵向箭头暗示当运算符双方的运算数为差异范例时的转换,如一个long 型数据与一个int型数据一起运算,需要先将int型数据转换为long型, 然后两者再举办运算,功效为long型。所有这些转换都是由系统自动举办的, 利用时你只需从中相识功效的范例即可。这些转换可以说是自动的,但然,C语言也提供了以显式的形式强制转换范例的机制。
4.当较低范例的数据转换为较高范例时,一般只是形式上有所改变, 而不影响数据的实质内容, 而较高范例的数据转换为较低范例时则大概有些数据丢失。
#p#分页标题#e#
5.当赋值运算符双方的运算工具范例差异时,将要产生范例转换, 转换的法则是:把赋值运算符右侧表达式的范例转换为左侧变量的范例。 C语言赋值时的范例转换形式大概会使人感想不紧密和不严格,因为不管表达式的值奈何,系统都自动将其转为赋值运算符左部变量的范例。而转变后数据大概有所差异,在不加留意时就大概带来错误。 这确实是个缺点,也遭到很多人们品评。但不该健忘的是:c面言最初是为了替代汇编语言而设计的,所以范例调动较量随意。虽然, 用强制范例转换是一个好习惯,这样,至少从措施上可以看出想干什么。
5.int —–>char范例转化时的内存操纵
当我们把一个int型强制转化为byte时,由于byte只有1个字节,而int型是4个字节,这样就会发生截断,int把它最低的内存空间里的值放到了byte所对应的内存空间里。如图所示:
char int
********** **********
* 1 Byte * <———–* 1 Byte * 低位
********** ********** |
* 1 Byte * 高位
********** |
6.深入阐明开始的问题
内存地点是由上到下有从左至右依次递增的,小端字节序指低字节位数据存放在内存低地点处, 高字节位数据存放在内存高地点处; 大端字节序是高字节数据存放在低地点处,低字节数据存放在高地点处。x86的CPU体系布局中,就是利用小端字节序,即低字节数据存放在低地点处,高字节数据存放在高地点处。将int型的数据转化成char型的数据时,我们只取低8位;假如我们的CPU是小端模式,则我们在举办强制范例转换时不需要调解字节内容,很是的利便;假如我们的CPU是大端模式,则我们,需要将高字节地点的数据存入低字节地点,也就是需要调解字节内容。
7.总结
小端模式 :强制转换数据不需要调解字节内容,因为1、2、4字节的存储方法的字节的位置是一样。
