Data mining
数据挖掘课业代写 1.(20%)(Model selection) according to the following table, draw the ROC charts for M1 and M2. Then, based on the AUCs of these two charts,
1.(20%)
(Model selection) according to the following table, draw the ROC charts for M1 and M2. Then, based on the AUCs of these two charts, point out which model performs better for this dataset.
| Instance | True Class | P(+|M1) | P(+|M2) |
| 1. | + | 0.50 | 0.61 |
| 2. | + | 0.69 | 0.23 |
| 3. | + | 0.44 | 0.68 |
| 4. | – | 0.55 | 0.31 |
| 5. | – | 0.67 | 0.45 |
A little help: TPR=TP/(TP+FN); FPR=FP/(TN+FP)
2.(20%)
Determine the principal components Y1and Y2for the covariance matrix
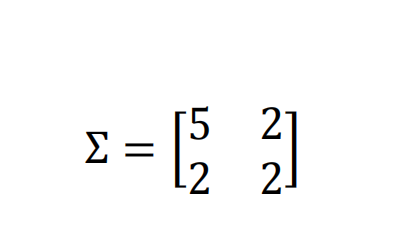
Also, calculate the proportion of the total variance explained by the first principal component. Note that the original dataset has two attributes, X1 and X2.
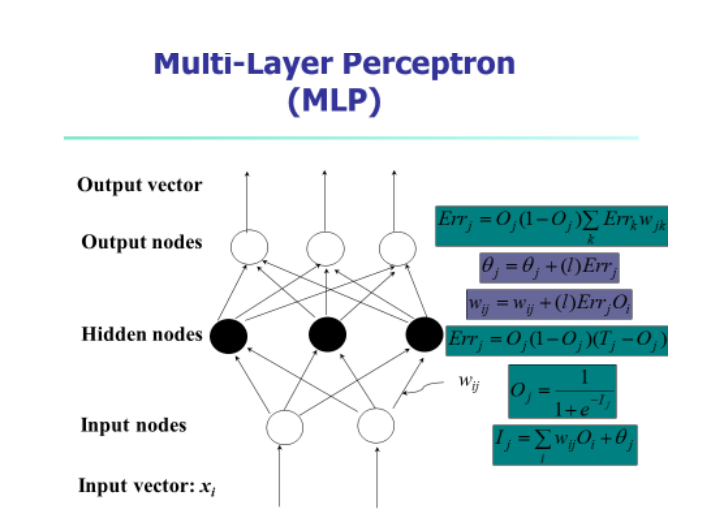
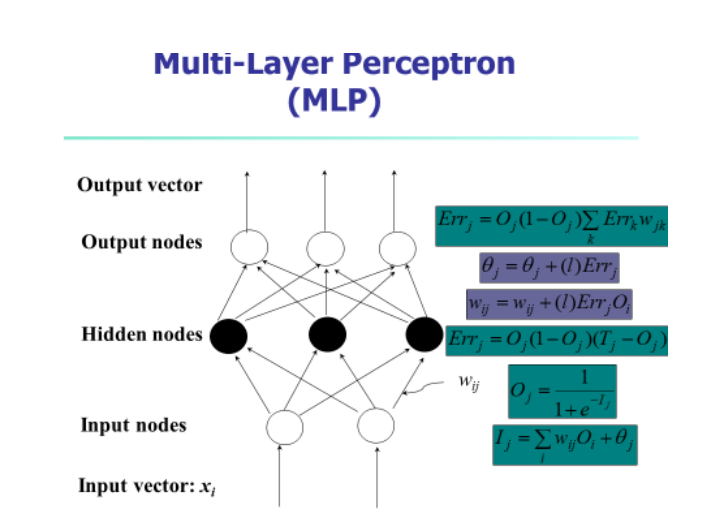
3.(30%, Backward propagation) 数据挖掘课业代写
Consider a two-layer ANN with two inputs a and b,one hidden unit c, and one output unit d. This network has three weights wac, wbc, wcd,, where wacis the weight on the link from a to c, and so on. Answer the following two questions:
(a) Draw this ANN. (10%)
(b) Describe how to train a neural network. (10%)
(c) Given initial values 0.1, 0.2, 0.1 for weights wac, wbc, wcd, respectively, a training sample (1, 1, 1) for (a, b, d) and the learning rate l = 0.3, find the value of wcd , after performing one iteration of the backpropagation training algorithm. (10%)
Some help: e-0.2 =0.8187; e-0.3=0.741; try to calculate all the others by referencing the attached formula. List your computing steps to get some credits when you have a wrong answer.
4.(10%, NLP)
A document-term frequency matrix (DTM) is shown in the following:
| Document/term | t1 | t2 | t3 | t4 | t5 | t6 | T7 |
| d1 | 0 | 4 | 10 | 8 | 0 | 5 | 0 |
| d2 | 5 | 19 | 7 | 16 | 0 | 0 | 32 |
| d3 | 15 | 20 | 10 | 4 | 9 | 0 | 17 |
| d4 | 22 | 3 | 12 | 0 | 5 | 15 | 0 |
| d5 | 0 | 7 | 0 | 9 | 2 | 4 | 12 |
Please find the top-3 most important terms for document d3 based on the TF-IDF measure.

5.(20%) (Regression Tree) 数据挖掘课业代写
The following dataset contains two columns, X and Y. Please build a regression tree with X as the input variable and Y as the output variable (10%). Then, fill in the predicted value for each X using the regression tree. (10%)
Note: Set the minimum number of samples in a node to three to allow splitting the node in building the regression tree. In other words, if the number of samples in a node is less than or equal to two (£2), no splitting of this node is allowed.
| X | Y | Predicted |
| 1 | 1 | |
| 2 | 1.2 | |
| 3 | 1.4 | |
| 6 | 5.5 | |
| 7 | 6.1 |
6.(20%, Gradient Boosting, SIMPLE!) 数据挖掘课业代写
With the same dataset of problem 1, use gradient boosting to construct a model for predicting Y. To reduce the required computation, use only one one-level regression tree. That is, use F0 = 3.04 as the first prediction for all Y’s; construct a one-level regression tree h1 to predict the residuals. Then, compute the predicted values for all Y’s. Note, the learning rate is set to 1.

更多代写:代码代写 线上雅思 英国社会心理学作业代写 商科essay论文代写 商科文书写作 澳洲assignment代写
