NLP(自然语言处理)中的一个常见任务是标记化。“令牌”通常是单个词(至少在像英语这样的语言中),“标记化”是将文本或一组文本分解成单个词。然后将这些令牌用作其他类型分析或任务的输入,如解析(自动标记单词之间的语法关系)。
在本教程中,您将学习如何:
-
将文本读入R
-
只选择某些行
-
使用tidytext软件包对文本进行标记
-
计算令牌频率(每个令牌在数据集中出现的频率)
-
编写可重复使用的功能来完成上述所有操作,并使您的工作具有可重复性
在本教程中,我们将使用双语儿童英语口语的转录语音。您可以在此数据集中找到更多信息并在此处下载。
这个孩子的演讲数据集非常酷,但它有点怪异的文件格式。这些文件是由CLAN制作的, CLAN是一个录制儿童言语的专门程序。然而,它们只是带有一些额外格式的文本文件。通过一些文本处理,我们可以将它们视为纯文本文件。
让我们这样做,并找出不同的孩子多长时间使用不同的流利程度(像“呃”或“呃”这样的词)和他们接触英语的时间之间是否存在关系。
|
1
2
3
4
五
6
7
8
9
|
# load in libraries we'll needlibrary(tidyverse) #keepin' things tidylibrary(tidytext) #package for tidy text analysis (Check out Julia Silge's fab book!)library(glue) #for pasting stringslibrary(data.table) #for rbindlist, a faster version of rbind# now let's read in some data & put it in a tibble (a special type of tidy dataframe)file_info <- as_data_frame(read.csv("../input/guide_to_files.csv"))head(file_info) |

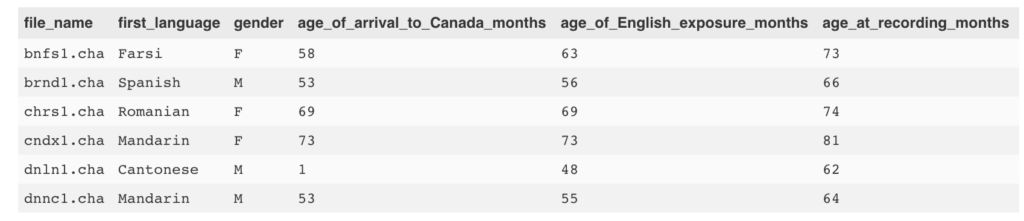
好吧,这一切看起来不错。现在,让我们以该.csv中的文件名称并将其中一个读入R.
|
1
2
3
4
五
6
7
8
9
10
|
# stick together the path to the file & 1st file name from the information filefileName <- glue("../input/", as.character(file_info$file_name[1]), sep = "")# get rid of any sneaky trailing spacesfileName <- trimws(fileName)# read in the new filefileText <- paste(readLines(fileName))# and take a peek!head(fileText)# what's the structure?str(fileText) |
 哎呀,真是一团糟!我们已经将它作为向量读入,每行都是一个单独的元素。这对于我们感兴趣的内容(实际单词的数量)并不理想。但是,它确实给了我们一个我们可以使用的快速的小骗子。我们只关注孩子正在使用的单词,而不是实验者。看看这些文档,我们可以看到,孩子的演讲只是以“* CHI:儿童演讲”开头。所以我们可以使用正则表达式来查看以该字符串开头的行。
哎呀,真是一团糟!我们已经将它作为向量读入,每行都是一个单独的元素。这对于我们感兴趣的内容(实际单词的数量)并不理想。但是,它确实给了我们一个我们可以使用的快速的小骗子。我们只关注孩子正在使用的单词,而不是实验者。看看这些文档,我们可以看到,孩子的演讲只是以“* CHI:儿童演讲”开头。所以我们可以使用正则表达式来查看以该字符串开头的行。
|
1
2
3
4
五
6
|
# "grep" finds the elements in the vector that contain the exact string *CHI:.# (You need to use the double slashes becuase I actually want to match the character# *, and usually that means "match any character"). We then select those indexes from# the vector "fileText".childsSpeech <- as_data_frame(fileText[grep("\\*CHI:",fileText)])head(childsSpeech) |
好吧,现在我们有一个孩子说的句子。这仍然不能让我们更接近回答我们这个孩子多少次说“这个”(这里转录为“&-um”)的问题。
首先让我们的数据整洁。 整洁的数据有三个特点:
|
1
2
3
4
五
|
1. Each variable forms a column.2. Each observation forms a row.3. Each type of observational unit forms a table. |
幸运的是,我们不必从头开始整理,我们可以使用tidytext软件包!
|
1
2
3
|
# use the unnest_tokens function to get the words from the "value" column of "childchildsTokens <- childsSpeech %>% unnest_tokens(word, value)head(childsTokens) |
 啊,好多了!你会注意到unnest_tokens函数也为我们做了大量的预处理工作。标点符号已被删除,并且所有内容都已变为小写。你并不总是想要这样做,但是对于这个用例来说它是非常实际的:我们不希望“树”和“树”被视为两个不同的单词。
啊,好多了!你会注意到unnest_tokens函数也为我们做了大量的预处理工作。标点符号已被删除,并且所有内容都已变为小写。你并不总是想要这样做,但是对于这个用例来说它是非常实际的:我们不希望“树”和“树”被视为两个不同的单词。
现在,我们来看看词频,或者我们看到每个词的频率。
|
1
2
|
# look at just the head of the sorted word frequencieschildsTokens %>% count(word, sort = T) %>% head |
嗯,我立即发现问题。最常见的单词实际上并不是孩子所说的:它是孩子说话的注释,或“chi”!我们将需要摆脱这一点。让我们通过使用dplyr中的“anti_join”来做到这一点。
|
1
2
3
4
五
|
# anti_join removes any rows that are in the both dataframes, so I make a data_frame# of 1 row that contins "chi" in the "word" column.sortedTokens <- childsSpeech %>% unnest_tokens(word, value) %>% anti_join(data_frame(word = "chi")) %>% count(word, sort = T)head(sortedTokens) |

大!这是我们想要的,但只适用于一个文件。我们希望能够在所有文件中进行比较。为此,让我们简化我们的工作流程。(奖金:这将使以后更容易复制。)
|
1
2
3
4
五
6
7
8
9
10
11
12
13
|
# let's make a function that takes in a file and exactly replicates what we just didfileToTokens <- function(filename){ # read in data fileText <- paste(readLines(filename)) # get child's speech childsSpeech <- as_data_frame(fileText[grep("\\*CHI:",fileText)]) # tokens sorted by frequency sortedTokens <- childsSpeech %>% unnest_tokens(word, value) %>% anti_join(data_frame(word = "chi")) %>% count(word, sort = T) # and return that to the user return(sortedTokens)} |
现在我们有了我们的功能,让我们通过一个文件来检查它是否正常工作。
|
1
2
3
4
五
6
|
# we still have this fileName variable we assigned at the beginning of the tutorialfileName# so let's use that...head(fileToTokens(fileName))# and compare it to the data we analyzed step-by-stephead(sortedTokens) |

好极了,我们函数的输出和我们一步一步分析的输出完全一样!现在让我们在整个文件集上进行操作。
我们需要做的一件事就是指出哪个孩子说了哪些单词。为了做到这一点,我们将在每次运行它时使用我们正在运行的文件来为此函数的输出添加一个coulmn。
|
1
2
3
4
五
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
三十
31
32
33
34
|
# let's write another function to clean up file names. (If we can avoid # writing/copy pasting the same codew we probably should)prepFileName <- function(name){ # get the filename fileName <- glue("../input/", as.character(name), sep = "") # get rid of any sneaky trailing spaces fileName <- trimws(fileName) # can't forget to return our filename! return(fileName)}# make an empty dataset to store our results intokenFreqByChild <- NULL# becuase this isn't a very big dataset, we should be ok using a for loop# (these can be slow for really big datasets, though)for(name in file_info$file_name){ # get the name of a specific child child <- name # use our custom functions we just made! tokens <- prepFileName(child) %>% fileToTokens() # and add the name of the current child tokensCurrentChild <- cbind(tokens, child)# add the current child's data to the rest of it # I'm using rbindlist here becuase it's much more efficent (in terms of memory # usage) than rbind tokenFreqByChild <- rbindlist(list(tokensCurrentChild,tokenFreqByChild))}# make sure our resulting dataframe looks reasonablesummary(tokenFreqByChild)head(tokenFreqByChild) |
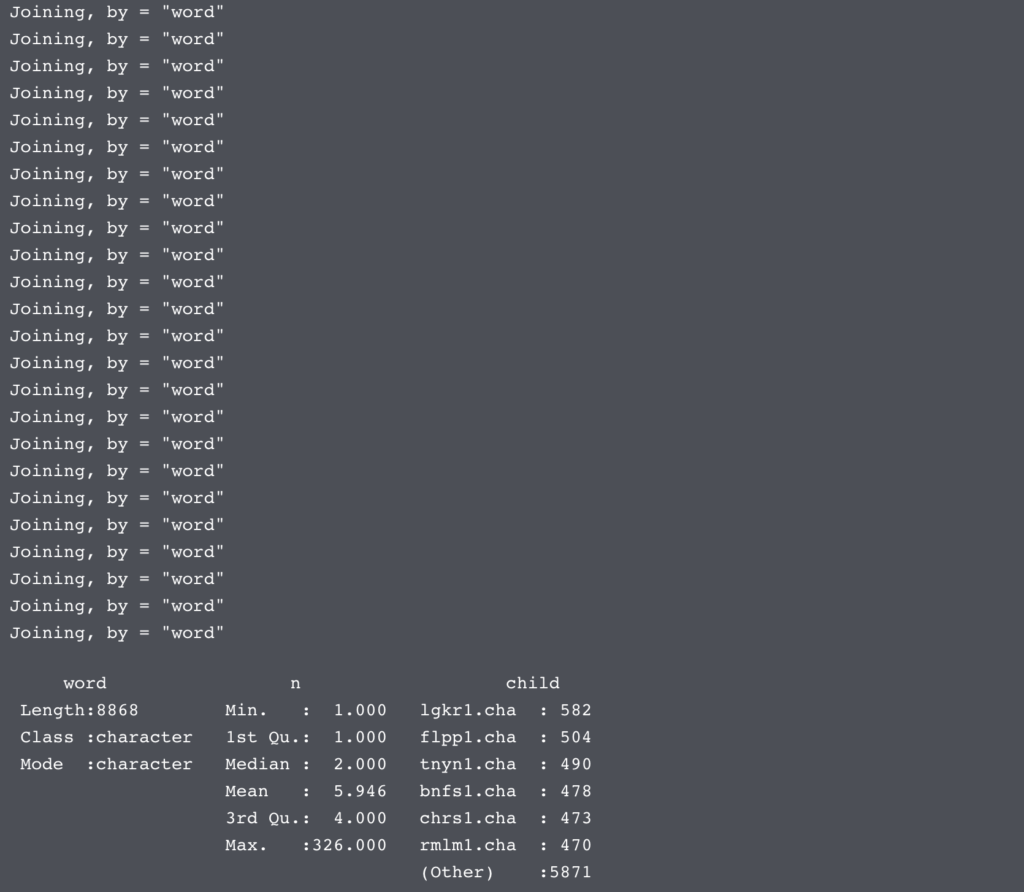

好的,现在我们已经获得了一个数据框中所有孩子的数据。让我们做一些visualizatoin!
|
1
2
|
# let's plot the how many words get used each number of times ggplot(tokenFreqByChild, aes(n)) + geom_histogram() |

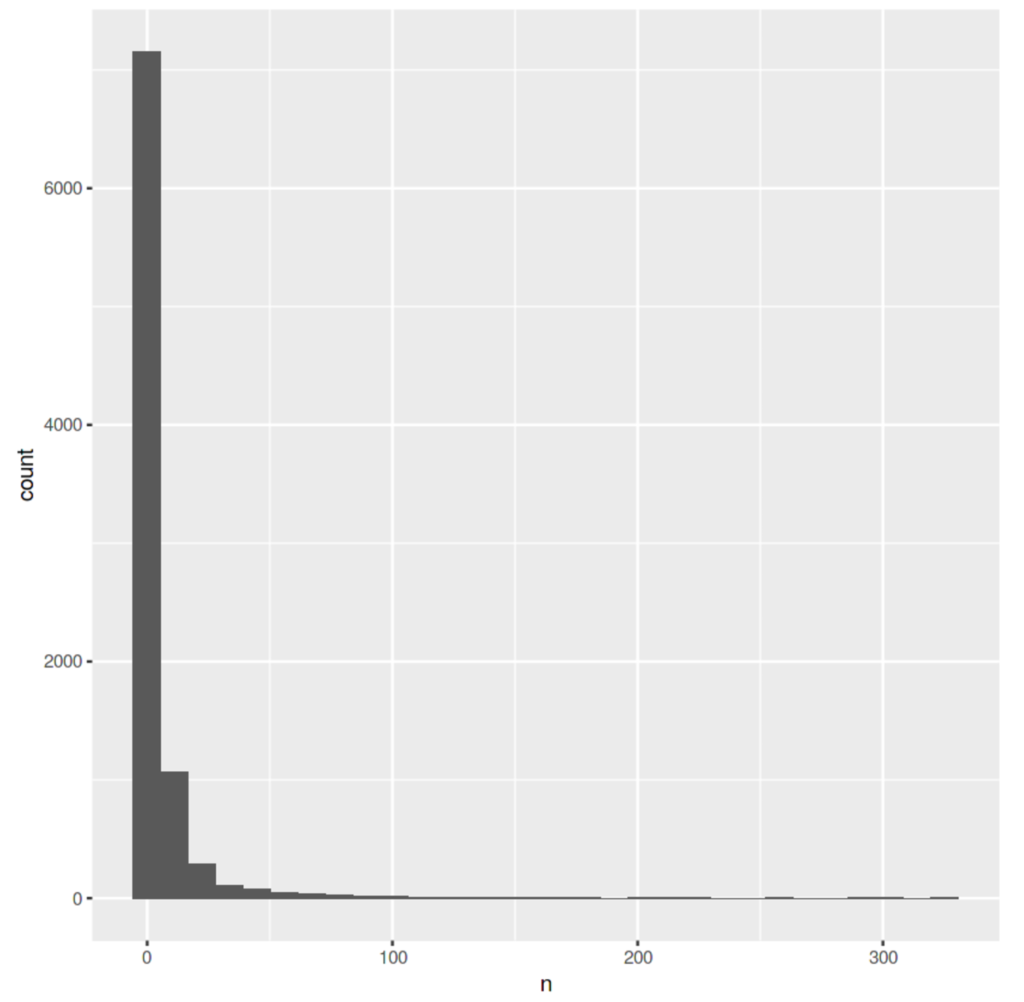
这种可视化告诉我们,大多数单词只使用一次,并且使用的单词越少。这是一种非常强大的人类语言模式(它被称为 “齐夫定律”),所以我们在这里看到它并不奇怪!
现在回到我们原来的问题。让我们来看看这个词的这个频率与这个孩子学习语言的时间有多长时间有关系。
|
1
2
3
4
五
6
|
#first, let's look at only the rows in our dataframe where the word is "um"ums <- tokenFreqByChild[tokenFreqByChild$word == "um",]# now let's merge our ums dataframe with our information fileumsWithInfo <- merge(ums, file_info, by.y = "file_name", by.x = "child")head(umsWithInfo) |
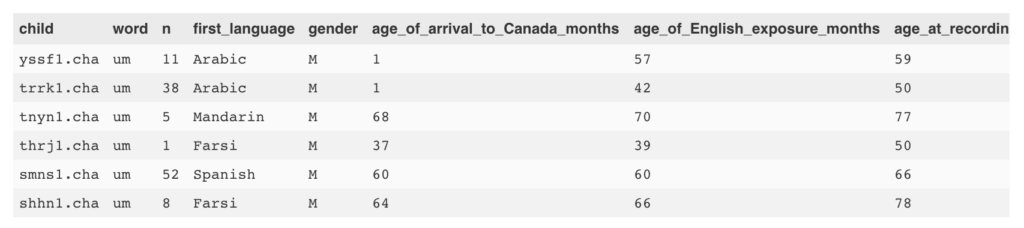
看起来不错。现在让我们看看孩子说“呃”的次数与他们有多少个英语曝光之间有关系。
|
1
2
3
4
五
6
|
# see if there's a significant correlationcor.test(umsWithInfo$n, umsWithInfo$months_of_english)# and check the plotggplot(umsWithInfo, aes(x = n, y = months_of_english)) + geom_point() + geom_smooth(method = "lm") |
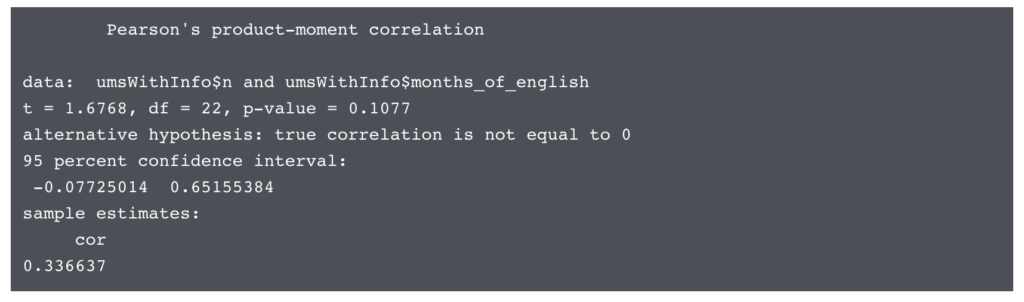
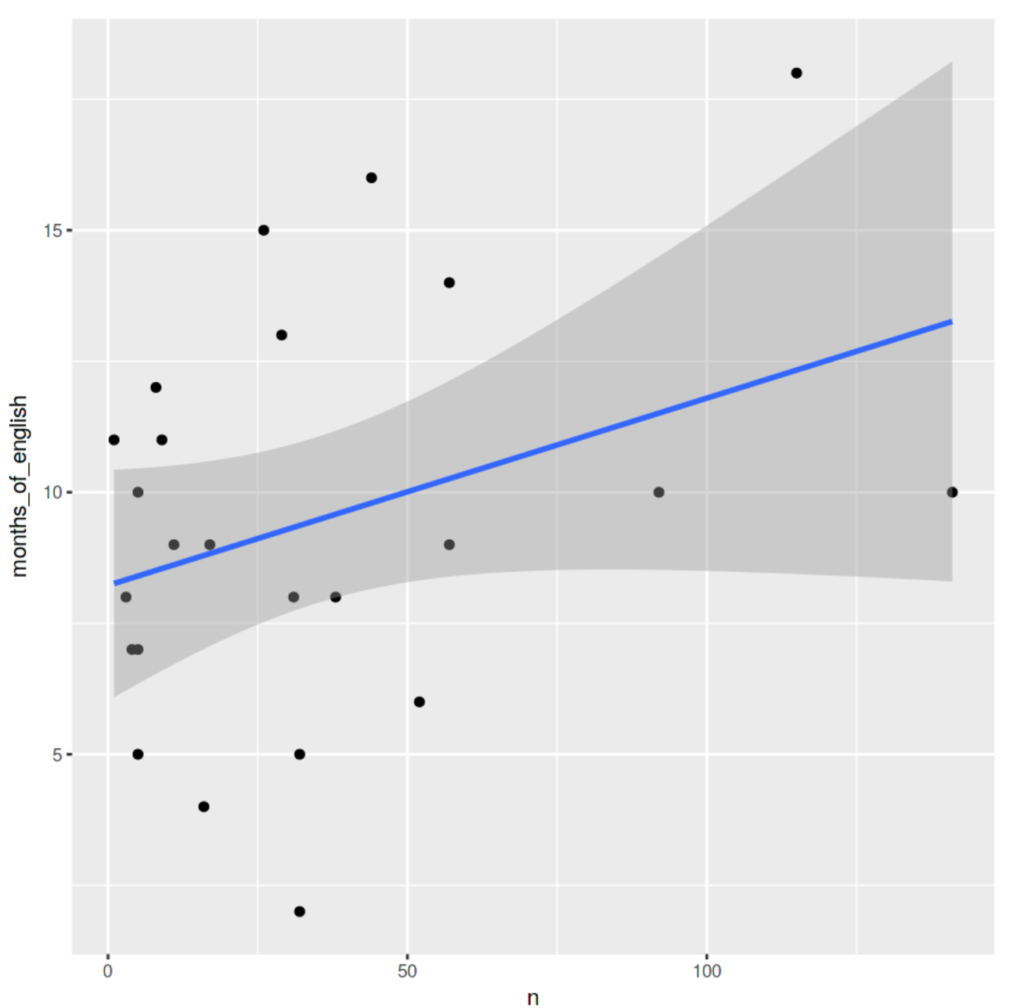
这是一个响亮的“不”。这个语料库中的一个孩子接触英语的月数与他们在数据启发期间说“这个”的次数绝对没有关系。
有些事情可以做得更好地进行分析:
-
看看相对频率(小孩说的所有单词中,“呃”是多少),而不仅仅是原始频率
-
看看所有的不良因素(“呃”,“呃”,“呃”等),而不仅仅是“嗯”
-
看看无法理解的演讲(“xxx”)
然而,我将以旧式数学教科书的风格,将这些作为练习留给读者(就是你!),因为我已经涵盖了一开始就承诺的一切。你现在应该知道如何:
-
将文本读入R
-
只选择某些行
-
使用tidytext软件包对文本进行标记
-
计算令牌频率(每个令牌在数据集中出现的频率)
-
编写可重复使用的功能来完成上述所有操作,并使您的工作具有可重复性
现在您已经掌握了标记化的基础知识,下面是一些您可以用来练习这些技能的其他语料库:
