
BUFN 650 – Problem Set 1
Python notebook代写 Important: Please submit your homework using Canvas. Your submission needs to in- clude two files: a PDF (or Word)
Due on Tuesday, November 26 at 11:59 pm
Important: Please submit your homework using Canvas. Your submission needs to in- clude two files: a PDF (or Word) document with all your responses AND a copy of your Python notebook (.ipynb Jupyter notebook file). To produce the latter, please click File → Download .ipynb in Google Colab, then save and upload the file on Canvas.Python notebook代写
Each student has to submit his/her individual assignment and show all work. Legibly handwritten and scanned submissions are allowed, but they need to be submitted as a single document. Please do not submit photographs of pages in separate files.
Part I: Short-answer questions (80 points)Python notebook代写
Please provide a concise answer for each of the questions below. Usually one or two short sentences should suffice. Do not write novels.
- (12 points) For each of parts (a) through (d), indicate whether we would generally expectthe performance of a flexible statistical learning method to be better or worse than an inflexible method. Justify your answer.
(a)The sample size n is extremely large, and the number of predictors p is small.
(b)Thenumber of predictors p is extremely large, and the number of observations n is small.
(c)The relationship between the predictors and response is highlynon-linear.
(d)The variance of the error terms, i.e. σ2= var(ε), is extremely high.Python assignment代写

2.(9points) Explain whether each scenario is a classification or regression problem,
and indicate whether we are most interested in inference or Finally, provide n and p.
(a)We collect a set of data on the top 500 firms in the US. For each firm werecord profit, number of employees, industry and the CEO We are interested in understanding which factors affect CEO salary.Python notebook代写
(b)Weare considering launching a new product and wish to know whether it will be a success or a We collect data on 20 similar products that were previously launched. For each product we have recorded whether it was a success or failure, price charged for the product, marketing budget, competition price, and ten other variables.
(c)Weare interested in predicting the % change in the USD/Euro exchange rate in relation to the weekly changes in the world stock Hence we collect weekly data for all of 2019. For each week we record the % change in the USD/Euro, the % change in the US market, the % change in the British market, and the % change in the German market.
3(12points) I collect a set of data (n = 100 observations) containing a single predictor and a quantitative I then fit a linear regression model to the data, as well as a separate cubic regression, i.e.,
Y = β0 + β1X + β2X2 + β3X3 + s.Python notebook代写
(a)Supposethat the true relationship between X and Y is linear, e.
Y = β0 + β1X + s.
Consider the training residual sum of squares (RSS) for the linear regression, and also the training RSS for the cubic regression. Would we expect one to be lower than the other, would we expect them to be the same, or is there not enough information to tell? Justify your answer.
(b)Answer(a) using test rather than training
(c)Suppose that the true relationship between X and Y is not linear, but we don’t knowhow far it is from Consider the training RSS for the linear regression, and also the training RSS for the cubic regression. Would we expect one to be lower than the other, would we expect them to be the same, or is there not enough information to tell? Justify your answer.Python notebook代写
(d)Answer(c) using test rather than training
4.(6 points) Consider the k-foldcross-validation.Python notebook代写
(a)Briefly explain how k-fold cross-validation is implemented.
(b)Whatare the advantages and disadvantages of k-fold cross-validation relative to the validation set approach?
- (3points) Suppose that we use some statistical learning method to make a prediction for the response Y for a particular value of the predictor X. Carefully describe how we might estimate the standard deviation of our
- (11points) We perform best subset, forward stepwise, and backward stepwise selection on a single data For each approach,
we obtain p + 1 models, containing 0, 1, 2, …, p predictors. Explain your answers:Python notebook代写
(a)Which of the three models with k predictors has the smallest trainingRSS?
(b)Whichof the three models with k predictors has the smallest test RSS?
(c)True or False (no explanation necessary; 1 pointeach):
i.Thepredictors in the k-variable model identified by forward stepwise are a subset of the predictors in the (k + 1)-variable model identified by forward stepwise selection.
ii.Thepredictors in the k-variable model identified by backward stepwise are a subset of the predictors in the (k + 1)-variable model identified by backward stepwise selection.
iii.Thepredictors in the k-variable model identified by backward stepwise are a subset of the predictors in the (k + 1)-variable model identified by forward stepwise selection.Python notebook代写
iv.Thepredictors in the k-variable model identified by forward stepwise are a subset of the predictors in the (k + 1)-variable model identified by backward stepwise selection.
v.Thepredictors in the k-variable model identified by best subset are a subset of the predictors in the (k +1)-variable model identified by best subset selection.
7.(12points) The lasso, relative to least squares, is:
(a)Moreflexible and hence will give improved prediction accuracy when its increase in bias is less than its decrease in variance.
(b)Moreflexible and hence will give improved prediction accuracy when its increase in variance is less than its decrease in bias.
(c)Lessflexible and hence will give improved prediction accuracy when its increase in bias is less than its decrease in variance.Python notebook代写
(d)Lessflexible and hence will give improved prediction accuracy when its increase in variance is less than its decrease in bias.
- (15 points) Suppose we estimate the regression coefficients in a linear regression model byminimizing
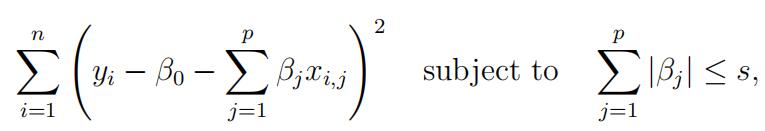
for a particular value of s. For parts (a) through (e), indicate which of i. through v. is correct. Justify your answer.
(a)As we increase s from 0, the training RSSwill:
i.Increaseinitially, and then eventually start decreasing in an inverted U shape.
ii.Decrease initially, and then eventually start increasing in a U shape.
iii.Steadily increase.
iv.Steadily decrease.
v.Remain constant.
(b)Repeat (a) for test RSS.
(c)Repeat (a) for variance.
(d)Repeat (a) for (squared) bias.
(e)Repeat (a) for the irreducible error.Python notebook代写
Part II: Predict the number of applications received by colleges (120 points)Python notebook代写
This exercise relates to the College data set, which can be found in the file College. It contains a number of variables for 777 different universities and colleges in the US. The variables are
- Private: Public/privateindicator
- Apps:Number of applications received
- Accept: Number of applicantsaccepted
- Enroll: Number of new students enrolled
- Top10perc: New students from top10
- Top25perc: New students from top25
- Undergrad: Number of full-timeundergraduates
- Undergrad: Number of part-timeundergraduates Python notebook代写
- Outstate: Out-of-statetuition
- Board: Room and boardcosts
- Books: Estimated bookcosts
- Personal: Estimated personalspending
- PhD: Percent of faculty withD.s
- Terminal: Percent of faculty with terminaldegree
- F.Ratio: Student/facultyratio
- alumni: Percent of alumni whodonate
- Expend: Instructional expenditure perstudent
- Rate: Graduationrate
Before reading the data into Python, it can be viewed in Excel or a text editor.
1.(20 points) Exploring thedata:
(a)Use the read csv(’http://faculty.marshall.usc.edu/gareth-james/ISL/College.csv’)function to read the data into Python. Call the loaded data college. Look at the data using the college.head() function. You should notice that the first column is just the name of each university. We don’t really want Python to treat this as data. However, it may be handy to have these names for later. Set is as an index by passing an index col=0 parameter to the read csv() call above. Alternatively, you may use the college.set index() command. In the future, you can extract college names using college.index.Python notebook代写
(b)Usethe describe() function to produce a numerical summary of the vari- ables in the data set.
(c)Import the seaborn package and alias it as sns. Use the pairplot() function toproduce a scatterplot matrix of the first five columns or variables of the data. Recall that you can reference the first five columns using college.iloc[,:5].
(d)Use the boxplot(x=college[’Private’], y=college[’Outstate’]) function to pro- duceside-by-side boxplots of Outstate versus Private (two plots side-by-side; one for each Yes/No value of Private).
(e)Createa new qualitative variable, called Elite, by binning the Top10perc We are going to divide universities into two groups based on whether or not the proportion of students coming from the top 10% of their high school classes exceeds 50%.Python notebook代写
Use the sum() function to see how many elite universities there are. Now use the sns.boxplot() function to produce side-by-side boxplots of Outstate versus Elite.
(f) Use the college.hist() function to produce some histograms for a few of the quan-titative variables. You may find parameters bins=20,figsize=(15,10) useful.
(g) Continue exploring the data, and provide a brief summary of what you discover.
2.(100 points) Now, let’s predict the number of applications received (variable Apps) using the other variables in the College dataset:
(a)(5points) Replace any text variables with numeric You may use pd.get dummies(college, drop first=True) to achieve this.Python notebook代写
(b)(5 points) Construct response y (Apps) and predictors X (the rest of variables). You are worried that non-linearities in X could be important and decide toadd all second-order terms to your predictors (i.e., x1, x2, x1x2, x2, x2 etc.). Add these terms to your X. Hint: you can use PolynomialFeatures().fit transform(X) func- tion from sklearn.preprocessing package. If you did everything correctly, the set of variables in X should now be expanded from 18 to 190 features (all second-order terms, including interactions and a vector of ones).
(c)(5 points) Split the data set into a training set and a test set. Never use the test setfor anything but reporting the test error when asked below.
(d)(5 points) Standardize all explanatory variables (subtract their time-series means and divide by standard deviation). Verify that all variables now have zeromean and unitary standard deviation.Python notebook代写
(e)(10 points) Fit a linear model using least squares on the training set, and report the test error obtained. Warning: if you used PolynomialFeatures().fit transform(X) anda vector of ones was added to predictors, set fit intercept=False.
(f)(15 points) Fit a ridge regression model on the training set, with λ chosen by cross-validation. Cross-validation should be performed using only the training set portionof the data in (a). Plot cross-validated MSE as a function of λ. Plot paths of coefficients as a function of λ. Report the test error obtained. Hint: I showed how to perform many of these steps in class in the Chapter 6.ipynb notebook.
(g)(15points) Repeat (f) using lasso You will likely receive convergence warnings or experience slowness.
Use the original characteristics (with no second- order terms) if you do. Report the number of non-zero coefficients.Python notebook代写
(h)(15points) Repeat (f) using random Recall that random forests and regres- sion trees allow for interactions and non-linearities in X by design. Therefore, use the original set of characteristics here (with no second-order terms). Experiment with the max depth parameter.
(i)(15 points) Fit an elastic net model on the training set, with λ chosen by cross- validation.Use the original Report the test error obtained. Hint: Use ElasticNetCV() estimator from sklearn.linear model to cross-validate and fit a model. You can read more here. Elastic net needs to cross-validate two param- eters. You can do this automatically by adding l1 ratio=np.linspace(.05, 1, 20) as a parameter.
(j)(10points) Comment on the results How accurately can we predict the number of college applications received? Is there much difference among the test errors resulting from these five approaches?

其他代写:java代写 function代写 web代写 编程代写 report代写 数学代写 algorithm代写 python代写 java代写 code代写 project代写 dataset代写 analysis代写 C++代写 代写CS 金融经济统计代写 essay代写 assembly代写 program代写
