OneR算法简介
OneR又称1-R,是1993呈现的一种极为简朴的分类算法模子,它可以发生一个单层的决定树。
OneR算法是一个简朴、便宜的要领,可是经常可以或许得到一个很是好的功效,用于描写数据中的布局。
OneR算法的利用很是遍及,可以简朴的获得一个对数据的归纳综合性相识,有时候甚至可以直接得到功效。
OneR算法实现
OneR的思路很简朴,成立一个只针对付单个属性举办测试的法则,并举办差异的分支。每个分支对应的差异属性值。
分支的类就是原始数据(练习数据)在这个分支上呈现最多的类。
每一个属性城市发生一个差异的法则集,每条法则对应这个属性的每个值。对每个属性值的法则集的误差率举办评估,选择结果较好的一个即可。
伪代码表述:
对付每个属性
对付这个属性的每个属性值,成立如下法则
计较每个种别呈现的频率
找出呈现最频繁的种别
成立法则,将这个种别赋予这个属性值
计较法则的误差率
选择误差率最小的法则
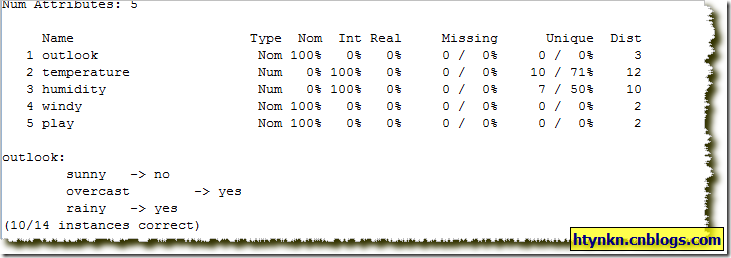
一个简朴的例子,数据利用weka自带的weather数据集。
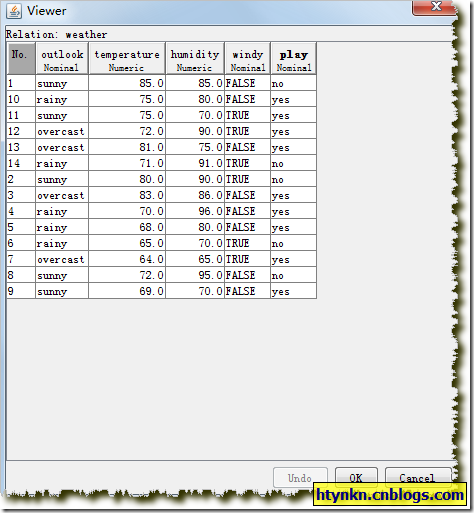
针对每个属性,一共有5个,个中最后一个是我们但愿输出的功效,所以只有4个属性值。即outlook、temperature、humidity、windy。
我们先计较outlook属性,它有3个属性值,sunny、rainy、overcast。
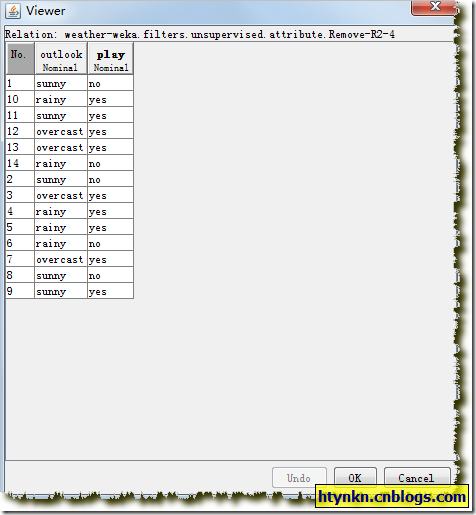
针对属性值sunny而言,一共有5条数据。
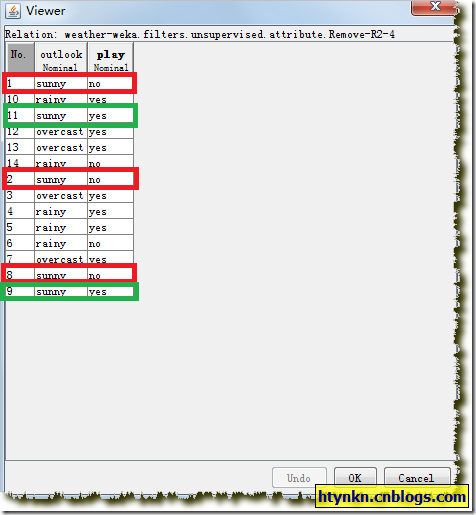
个中对应play为no的有3条、对应play为yes的有2条,为no的最频繁,所以给sunny赋值为no。
同理对付rainy而言,有5笔记录。
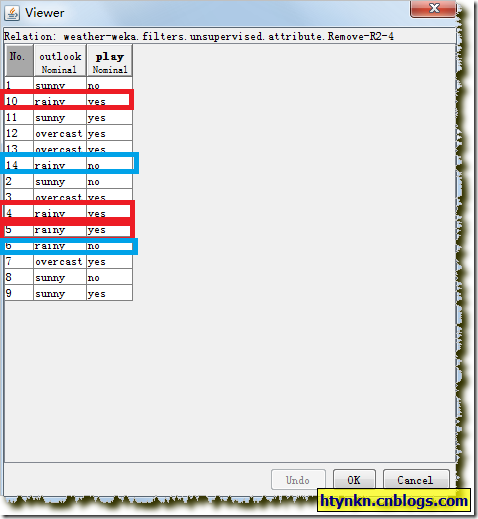
个中对应play为yes的有3条、对应play为no的有2条,为yes的最频繁,所以给rainy赋值为yes。
同理计较overcast属性值,赋值为yes。
然后计较误差率
sunny—>no 中有3个分类正确,2个分类错误,误差0.4
rainy—>yes 误差为0.4
overcast—>yes 误差为0
outlook总误差4/14
然后依次计较temperature、humidity、windy属性,并计较误差和总误差。然后选择误差最小的(沟通则随意取可能取不变度高的)。
最后功效为
sunny—>no rainy—>yes overcast—>yes
利用Weka实现OneR算法
weka自身已经实现了OneR算法,位于weka.classifiers.rules包中。
OneR可以传入一个参数,假如是一个持续值,并且你但愿离散化它们的话可以指定一个桶巨细。
Instances instances = DataSource.read(“data/weather.arff”); instances.setClassIndex(instances.numAttributes() – 1); System.out.println(instances.toSummaryString()); OneR oneR = new OneR(); oneR.setDebug(false); oneR.setMinBucketSize(6); oneR.buildClassifier(instances); System.out.println(oneR.toString());
结果:
假如将桶巨细设为1,功效将会有很大差异。
很明明前一个功效的用处要大许多。
相关参考
关于OneR的相关,较好的参考自然是1993年R.C. Holte所著相关文章Very simple classification rules perform well on most commonly used datasets,页码是63-91页。
附上下载地点:http://www.ctdisk.com/file/6000694
