我们知道mysql的数据库查询和表有储放在mysql的data文件目录中。一个数据库查询相匹配一个文件目录,一个数据分析表相匹配一个或好几个文档。
Myisam模块的主键数据库索引
Myisam的表相匹配三个文档:frm、MYD和MYI,各自储存着表结构,表数据信息和表数据库索引
下边是以主键为数据库索引搭建的myisam表的B 树:
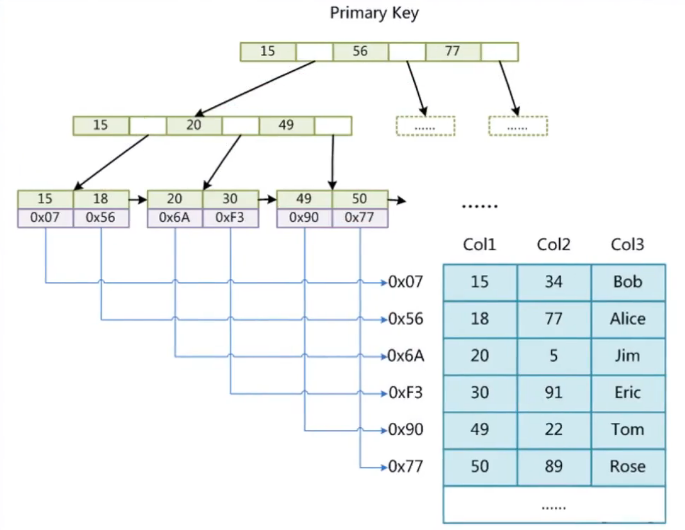
图中中,左上方是一个B Tree , 存有MYI文档中。右下方是全部表数据信息,存有MYD文档中。
当我们查看 select * from t where col1 = 30;
它会先分辨col1是不是为数据库索引字段名,是则先去MYI文档中,依照B 树的查找算法寻找 30这一数据库索引的vlaue,在myisam中value存的是数据库索引所属行的室内空间详细地址。
因此mysql会拿着这一详细地址在MYD文档中寻找硬盘详细地址相匹配的部位的行(MYD文档在物理学上主要表现为硬盘的某一个地区),载入这一部位的行数据信息(这一全过程称为回表)。
针对myisam应用数据库索引搜索行数据信息会跨2个文档。因此 myisam的数据库索引是是非非聚集索引。
Innodb模块的主键数据库索引
Innodb的表相匹配frm和idb2个文档,frm是表结构,idb是数据信息 数据库索引。
下边是以主键为数据库索引搭建的innodb表的B 树:
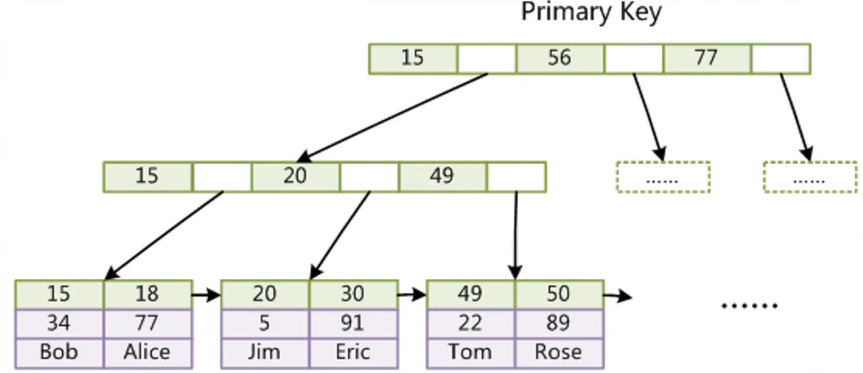
innodb表的主键数据库索引和别的字段名的数据信息一起储放在以B 树的算法设计储存起來的。
Idb文档中的B 树的非叶子节点也是储放好几个key但不储放data/value。叶子节点的key是好几个(主键)数据库索引字段名值,而value是(主键)数据库索引字段名所属行的别的列的数据信息內容。
由于innodb的(主键)数据库索引和数据信息是放进一个文档中,放到一个叶连接点中,因此 这类数据库索引称为聚集索引。
聚集索引的高效率实际上比非聚集索引的高效率,因为它仅用搜索1个文档。
二级数据库索引
上边详细介绍了myisam和innodb的主键数据库索引的B 树,下边详细介绍myisam和innodb的非主键数据库索引(二级数据库索引)的B 树。
最先要搞清楚的一件事是:不论是myisam還是innodb,在我们为一个表多建立一个数据库索引的情况下,最底层便会多搭建出一颗B 树。
针对一个表A,大家一般会新建表的情况下,给A建立一个主键数据库索引(id)。这时最底层便会为这一主键数据库索引搭建一棵B 树并存有idb或myi文档中。
可是假如我觉得给A的此外一个字段名搭建一个一般数据库索引,或是我觉得给A的此外几个字段搭建一个联合索引,这时最底层会多搭建出一棵B 树。像这类非主键的数据库索引(一般数据库索引或联合索引或是非主键的唯一索引),大家把它称为二级数据库索引。
每一次新创建一个二级数据库索引,都是会在搭建一棵新的B 树。因此 假如数据库索引建的过多,還是挺耗硬盘储存空间的。
那麼下面我想分离详细介绍innodb和myisam这二种模块的二级数据库索引的B 树,由于她们是各有不同的。
Myisam的二级数据库索引的B 树和myisam的主键数据库索引的B 树沒有一切差别,二级数据库索引的B 树的叶子节点中的value也是储放着数据信息行所属的硬盘详细地址。不管应用一般数据库索引還是主键来搜索数据信息行都必须寻找行的硬盘详细地址开展回表。
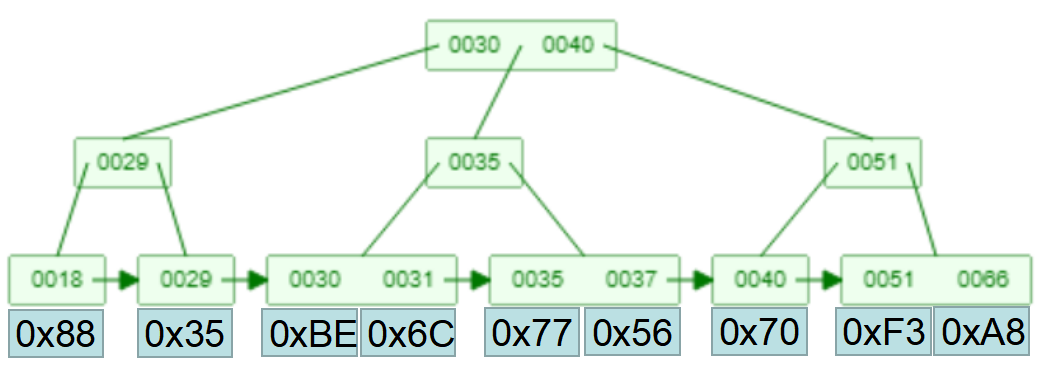
(Myisam的二级数据库索引)
Innodb的二级数据库索引和innodb的主键数据库索引不一样,innodb的主键数据库索引的B 树叶子连接点的value储放着行数据信息,可是他的二级数据库索引叶子节点存的并不是行数据信息的详细地址也不是行数据信息自身,只是这一一般数据库索引相匹配的主键值(id)
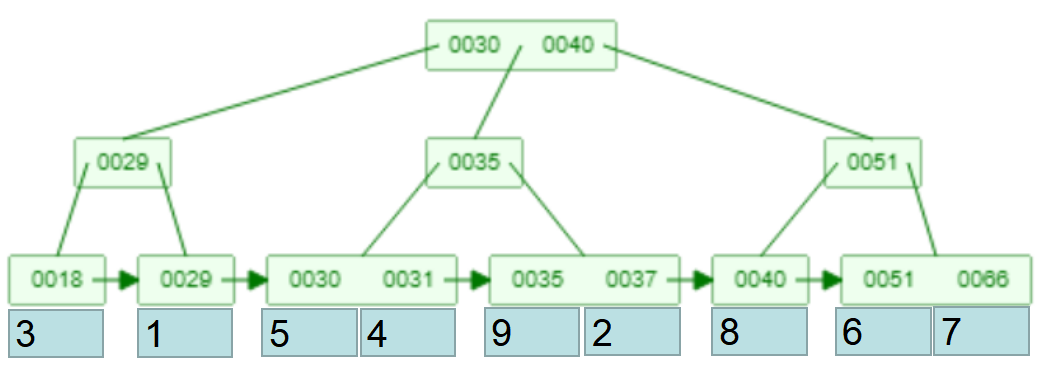
(Innodb的二级数据库索引)
假如应用innodb的一般数据库索引或是联合索引搜索一条行纪录,会先在二级数据库索引的B 树寻找这一数据库索引相匹配的主键值,再依据主键值在主键数据库索引B 树的根节点向下寻找叶连接点的行数据信息。
较为myisam和innodb的二级数据库索引:
1.假如应用innodb的二级数据库索引(一般数据库索引、非主键唯一索引或联合索引)查看行,必须走两棵树,倘若每株树全是3层,便会产生3 3=6次io实际操作。假如myisam得话,只需走一棵树,总是产生3次io取得行详细地址,可是myisam也要依据行详细地址到数据分析表中寻找行数据信息,innodb立即在B 树中就取得了行数据信息。
2.Innodb的二级数据库索引的叶子节点存的是主键值,myisam的二级数据库索引存的是行详细地址,后面一种更节约储存空间。
3.当增加或是删掉行的情况下,或是改动行中的数据库索引字段名的值的情况下,myisam的主键数据库索引和全部的二级数据库索引的B 树会产生连接点均衡(技术专业的称呼称为页瓦解),更新改造树的结构。而innodb仅有主键数据库索引会产生连接点均衡,二级数据库索引不用均衡。因此 innodb的写和改动数据信息的速率会比myisam快。
稀少数据库索引和较密数据库索引
稀少数据库索引便是数据库索引列和别的列 的数据信息不放到一棵B 树中的数据库索引,较密数据库索引便是数据库索引列和别的列的数据信息放到同一棵B 树的数据库索引。
Innodb的主键数据库索引(聚集索引)是较密数据库索引,innodb的二级数据库索引是稀少数据库索引。
Myisam的主键数据库索引(非聚集索引) 是稀少数据库索引,myisam的二级数据库索引也是稀少数据库索引。
InnoDB与MyISAM储存模块中间的较为
下边大家下列好多个层面来较为一下这两个储存模块的不一样。
事务管理的适用
InnoDB适用ACID的事务管理,MyISAM并不兼容事务管理
数据库索引与主键解决
InnoDB储存模块应用的是聚集索引,InnoDB主键的叶子节点是这家银行的数据信息,而别的数据库索引则偏向主键,而MyISAM储存模块应用的是是非非聚集索引,主键与别的数据库索引的叶子节点都储存了偏向数据信息的表针。
此外一个是MyISAM数据分析表容许沒有主键和别的数据库索引,而InnoDB数据分析表要是没有主键得话,而会转化成一个客户不由此可见6字节数的主键。
外键约束
MyISAM不兼容外键约束,而Innodb则适用创建数据分析表中间的外键约束关系。
储存文档的不一样
Innodb储存文档有frm、ibd,而MyISAM是frm、MYD、MYI,Innodb储存文档中frm是数据分析表构造界定文档,ibd是数据库文件,MyISAM中frm是数据分析表构造界定文档,MYD是数据信息的文档,MYI则是储存数据库索引的文档。
select count(*)
应用MyISAM储存模块的数据分析表会纪录一个数据分析表的总公司数,因此 对应用MyISAM储存模块的数据分析表开展select count(*),能够迅速获得一个数据分析表的总公司数,而针对InnoDB储存模块的数据分析表,要想查看总公司数必须开展全表扫描仪才可以获得。
锁的等级
InnoDB适用行级锁,而MyISAM只适用表级锁,因而InnoDB更能适用分布式系统。
================================================
为何Innodb表务必有主键,而且强烈推荐用整形的自增主键?
如果你是innodb的表,B 树务必用一个列的值做为连接点中每一个数据库索引的key。如果不建立主键,innodb也会从数据分析表选中一列沒有重复值的列的值做为连接点的key,目地便是为了更好地把B 树这一构造给机构起來。假如表格中全部的列都是有重复值,mysql会维护保养一个沒有重复值的掩藏列(row_id) 做为这一B 树连接点的数据库索引的key,可是这会提升mysql的压力,因此 還是自身建一个主键。
为何强烈推荐用自增整形主键,大家以前说过再用B 树开展搜索一个数据库索引A的情况下,会多次把树的连接点载入到运行内存,将这一连接点内全部的key与数据库索引A开展核对寻找数据库索引A所属的范畴。整形毫无疑问比字符串数组核对高效率。并且数据占有的储存空间毫无疑问比字符串数组小,促使一棵叠加层数同样的B 树能储存大量的数据库索引。
为什么要自增的?由于如果是自增的数据库索引,在insert数据信息的情况下,数据库索引会立即加上在B 树最右侧的叶子节点中,防止了繁杂的页瓦解。要不是自增的数据库索引,只是一个唯一字符串数组(uuid),插进那样的数据库索引到B 树的叶子节点时很有可能让B 树做数次均衡(页瓦解),而均衡的全过程必须开展一系列测算。因此 应用自增数据做为主键对比于应用非自增的字符串数组uuid做为主键对比,数据库索引添加到B 树的这一实际操作的特性会高些(数据信息的插进的速率更快)。
因此 不管从時间還是室内空间而言,自增整形当家做主键全是更强的。
================================================
范畴搜索(> < between and)和in搜索在B 树中的完成:
状况1:> <
例如我觉得搜索id>30的数据信息(假定这儿id是主键数据库索引),那麼mysql会先从根节点往下一层连接点寻找30所属的叶子节点,随后根据叶子节点的双重连接找右侧邻近的连接点,这种右侧邻近的叶子节点逐一载入到运行内存中。
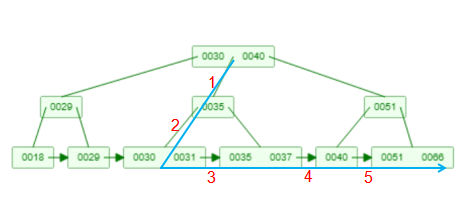
如下图所示,它的一个搜索运动轨迹是深蓝色线框所显示,一共历经了5个表针,发生了5次硬盘IO。
假如 范畴搜索 的范畴标准过大,那麼在B 树中的IO实际操作频次会太多,这时mysql会觉得还比不上立即全表扫描仪快,便会舍弃应用数据库索引改成用全表扫描仪。
状况2:in搜索
例如我想查 where id in (18, 30, 31,37,51),它的全过程以下如所显示:
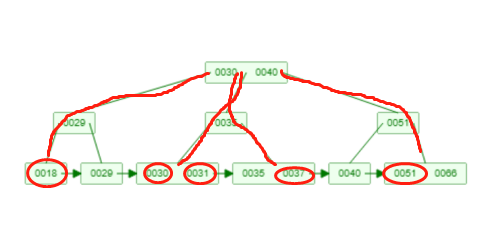
每搜索一个id都是会从根节点往下来寻找这一id相匹配的叶子节点。因此 上边的 where in查看共发生了8次io。
In搜索有时会被mysql觉得是范畴搜索,有时被觉得是好几个精确查找。
状况3:
如今假定views字段名是一个一般数据库索引而不是一个主键,假如我觉得搜索 views > 100(假定考虑>100的views有103,234,177,302这4个数据,这4个数据放到了2个叶连接点上,二级数据库索引共3层连接点)。那麼会先在二级数据库索引根据范畴搜索寻找103,234,177,302这4个数据相匹配的主键id(假定相匹配的id分别是57,11,90,33),这一全过程发生了3次io实际操作。随后依据这4个主键id到主键数据库索引的B 树中从根节点向下找这4个id相匹配的行纪录(有4个id就需要分4次从根节点向下找)。大家假定57,11,90,33这4个id各自放到了4个叶子节点中,主键数据库索引的树有3层,那麼在主键数据库索引共开展 (3-1) * 4 = 8次io,再再加上在二级数据库索引产生的3次io,一共是11次io。
因此 范畴搜索和in搜索对比于精确查找(=)而言是更费io的。
================================================
联合索引搜索在B 树中的完成:
在具体工作上,如果我们对一个表的3,4个字段名建数据库索引得话,大家非常少会对每一个字段名独立建数据库索引。只是对这3,4个字段名创建一个联合索引。
联合索引的最底层是怎么完成的(关键,如今在网上说的索引优化标准全是根据此)
以一个innodb表,4个字段名,7条纪录为例子:
Col1 Col2 Col3 Col4
10001 Assistant 1998-09-03 2002-06-03
10001 Engineer 1996-08-03 2001-08-03
10001 Staff 2001-09-03 2006-03-06
10002 Staff 1996-08-03
10003 Staff 1997-08-03 2011-08-07
10003 Staff 2001-09-03 2009-06-03
10004 Staff 1996-08-03
创建 index(col1, col2, col3) 这3个字段名的联合索引。
搭建B 的排列标准以下:先依照col1排列,假如col1同样,那麼再按col2排列,col1和col2都同样则按col3排列。搭建出去的一个B 树以下:
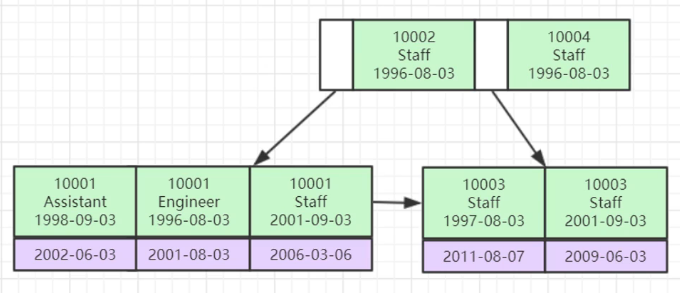
依照在网上说的最左作为前缀标准,我们知道 where col1 = 10003 and col2=”staff” 应用到联合索引,可是where col3=1996-08-03沒有采用联合索引
下面从最底层解释一下,为何 where col3=1996-08-03沒有采用联合索引;
实际上缘故非常简单,当实行 where col3=1996-08-03 的情况下,等同于不要看 col1和col2,那麼我们在B 树中不要看col1和col2是这一模样的(划线法):
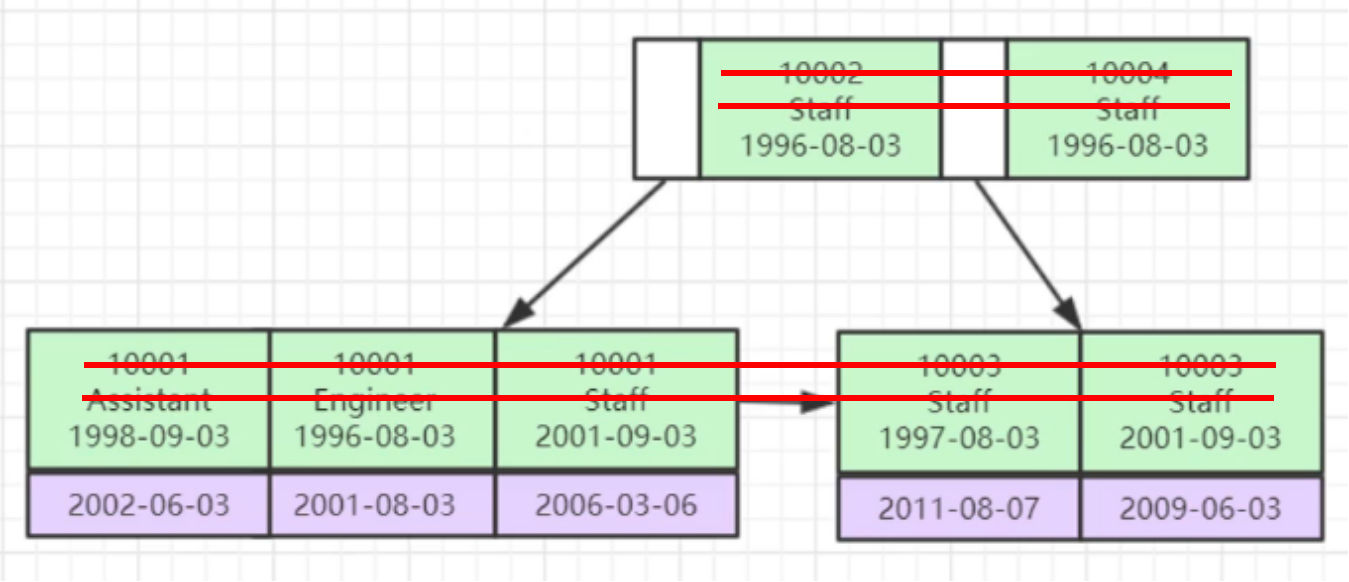
大家只到数据库索引的髙速搜索是根据树连接点的每一个数据库索引key全是排好序的,但是这时 只看col3它在B 树中(从左往右)就并不是一个排好序的模样只是一个乱序的模样,因此 这时它会做一个全表扫描仪而没法采用数据库索引开展搜索。
再举一个事例:
一个文章内容表,我给它的id和view设定了独立数据库索引,现在有2个数据库索引
Select * from article where id>500 and view < 100;
我想问一下这一sql是否会另外采用id和view这两个数据库索引开展搜索?
是不容易的,缘故非常简单,从最底层的角度观察,创建了2个独立数据库索引代表着建立了两株B 树,可是mysql不容易对一条sql句子去查两株B 树,只是总是去在其中一颗B 树查。因此 上边的sql尽管where中写到了id和view的标准,可是真实采用的就只有一个数据库索引。
再再举一个事例:
这一事例便是大家在网上搜mysql提升的情况下提及的一条标准:where用联合索引做为标准时,应用范畴搜索以后的标准都用不上数据库索引。
例如:
数据以下
col1 col2 col3
5 13 254
5 24 500
8 18 304
6 22 108
9 33 290
10 24 350
9 22 333
8 30 566
10 40 302
10 17 130
10 36 280
创建联合索引index col1_col2_col3(col1, col2, col3)
Select * from t where col1=10 and col2>20 order by col3
Select * from t where col1=10 and col2>20 and col3 =300
上边的两个sql中,Col1和 col2 都采用了数据库索引,可是col3沒有采用数据库索引。这儿还要从B 树表述,用一句话说便是 合乎col1=10 的叶连接点她们的col2字段名是排好序的。可是合乎 col1=10且col2>10的叶连接点她们的col3字段名是乱序的,因此 order by col3沒有采用数据库索引,必须mysql在运行内存中对col3开展排列,而 col3=300 沒有采用数据库索引,由于数据库索引迅速搜索是取决于安排好序这一特点的。
我那么说很有可能大伙儿搞不懂,那么就画上图好啦。
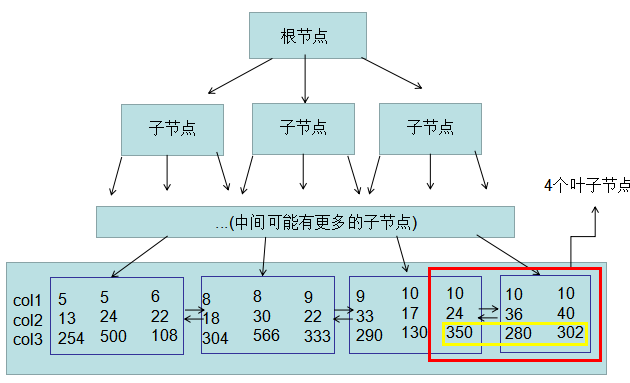
上边是一个搭建好的B Tree,白框内的数据库索引是考虑 col1 = 10 and col2>20的数据库索引。你看一下她们的col3字段名,也就是淡黄色圈圈以内的內容(350,302,280),黄框中的col3并不是排好序的,只是乱序的。因此 col3是沒有采用数据库索引。
========================================================
数据库索引的优点和缺点
数据库索引的优点:
我们知道数据库索引的B 树形结构的功效是排列和迅速搜索。
沒有数据库索引大家必须全表扫描仪,每扫描仪一条纪录便是一次IO(有多少条数据信息便会产生几回IO),拥有数据库索引以后,精确查找时树的叠加层数便是IO实际操作的频次,因而数据库索引能够降低IO成本费。
数据库索引新建的情况下会帮大家把数据库索引字段名安排好序,因此 查的情况下假如用了“order by 数据库索引字段名”得话,数据库查询就不用再对数据信息开展排列,降低了cpu的耗费。
数据库索引的缺点:
1.建太多的数据库索引是很占室内空间的。
2.数据库索引尽管能提升查看速率,可是会减少升级表的速率(insert、update和delete)。反映在最底层便是升级表的实际操作会造成B 树的再次均衡(页瓦解)、构造的更改和变更连接的偏向。
数据库索引的归类:
列项数据库索引:一个数据库索引只包括单独列,一个表能够建好几个列项数据库索引,但提议不必超出五个。并且用联合索引好于用列项数据库索引。
唯一索引:数据库索引列的值务必唯一,但容许空值。
联合索引:一个数据库索引包括好几个列的值。
什么字段名合适建数据库索引:
1.一个表务必有主键数据库索引,这儿会建数据库索引。
2.经常做为查询条件的字段名要
3.与别的表开展关系的字段名或是外键约束
4.查看时要常常排列的字段名
5.查看中统计分析和排序字段名(由于分组会先开展排列)
不宜建数据库索引的状况:
1.表纪录非常少(信息量不全集表扫描仪也迅速)
2.经常升级的字段名不宜建数据库索引,where标准用不上的字段名不建数据库索引
3.有很多反复的值的字段名换句话说离散度很低的字段名不宜建数据库索引(你回过头来,一个B 树的连接点的key中都是同样的值,排不排列都一样,并且也要载入好多好多的非叶子节点到运行内存,一样开展了许多io实际操作,比如下面的图:)
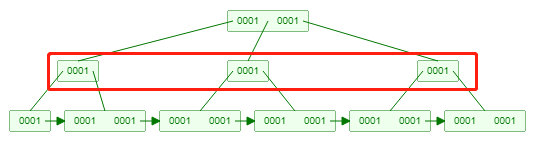
搜索where tid = 1 ,因为这棵树的数据库索引全是1,因此 全部的树连接点都是会从硬盘读到运行内存,io的频次=树中的连接点的数量。这个时候比全表扫描仪好一点点,可是也罢不上哪儿去。
========================================================
Memory 和 Merge 模块
Memory储存模块将表的数据信息储放在运行内存,每一个memory表相匹配一个frm文档,只储存表结构,而Memory的数据信息存有运行内存之中,它是为了更好地快速搜索和插进数据信息。Memory的浏览十分快,默认设置应用Hash数据库索引,但是因为是存有运行内存中,因此 一旦mysql关掉,数据信息便会消退,也就是不兼容持久化。
也有Memory模块是将数据信息存有运行内存,因此 表的数据信息不可以过多,不然运行内存会不够,换句话说不可以存大表。
Merge模块是一组Myisam表的组成,这种Myisam表务必构造完全一致。Merge表自身沒有存数据信息,对Merge种类的表的增删实质全是对內部的Myisam表开展的。
对Merge表drop实际操作是不容易删掉內部的Myisam,总是删掉Merge表。
这儿只简易的详细介绍有这二种模块,以后还有机会会对这种模块详解。
