死锁
死锁就是指的2个或是2个之上的事务管理在实行全过程中,由于角逐锁資源而导致的一种相互之间等候的状况。
留意,务必是互相等候才会死锁,假如仅仅A等B,是不容易产生死锁的。如果是A等B,B也等A便会死锁;或是有2个之上的事务管理产生一个环城路等候如:A等B,B等C,C等A,也会死锁。
死锁的伤害:
最先,mysql用的锁是一种自旋锁而不是一般的互斥锁,这代表着事务管理拿不上锁而被堵塞,等候别的事务管理释放出来锁的情况下不容易让给CPU,只是一直在高转速。这一全过程会一直耗费CPU。
因此 死锁的伤害很显著,一方面堵塞了指令的实行,造成分布式系统没法开展;另一方面死锁会造成好几个事务管理一直等候锁释放出来,CPU会被布满。
因此 假如在应用mysql发觉CPU被布满得话,很可能是由于死锁的缘故。
自然,mysql在产生锁等候的情况下不容易让事务管理一直等,只是会有一个请求超时時间。在InnoDB模块中,能够根据主要参数:innodb_lock_wait_timeout查看:
SHOW VARIABLES LIKE 'innodb_lock_wait_timeout';默认设置请求超时时间50s,请求超时后会全自动释放出来锁回退事务管理。
假如运行命令会产生死锁得话,mysql会立即出错:Deadlock found when trying to get lock; try restarting transaction;
意思是:试着去获得锁的情况下发觉会死锁,请再次打开一个事务管理。
很好运是否,mysql这一小机灵鬼还能检验出死锁。下边说说它是怎么检测出死锁的:
现阶段数据库查询绝大多数选用wait-for graph(等候图,图这类算法设计)的方法来开展死锁检验,InnoDB模块也是选用这类方法来检验死锁。
等候图的连接点意味着一个事务管理,连接点与连接点中间的连接意味着锁的等候偏向关联。
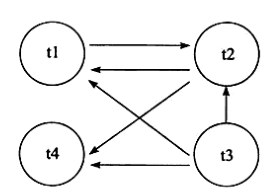
当图中连接点与连接点间产生环路,则证实存有死锁:
如下图中,t1和t2中间存有环路,这就证实t1和t2事务管理中间存有死锁
下边我举1个普遍的会产生死锁的状况:
场景:仿真模拟击杀时超售
大家一般会在业务流程层也一段那样的逻辑性(伪代码):
0 :\n Update goods set `store`=`store` - 1;\t\t# 降低库存量\n Insert into `order` values (xxxx);\t\t\t# 加上订单信息\nCommit;"}">Begin # 逐渐事务管理
store = select `store` from goods where id = 100 lock in share mode; # 查看id为100的产品的库存量, 这儿务必上锁,不然查出的库存量是历史时间库存量(快照更新读),而不是全新的库存量。
If store > 0 :
Update goods set `store`=`store` - 1; # 降低库存量
Insert into `order` values (xxxx); # 加上订单信息
Commit;
如今假定表goods仅有字段名id 和 store,并且store的值是1,也就是目前恰好只有一个库存量。A和B2个顾客在抢这一产品。
# A和B另外begin:
# 手机客户端A实行
select `store` from goods where id = 100 lock in share mode; # 查到是1
# 还未commit
# 正好这时手机客户端B也实行到select
select `store` from goods where id = 100 lock in share mode; # 查出也是1
# 还未commit
# 这时A见到库存量是1,因此逐渐减库存量
Update goods set `store`=`store` - 1;
# 这时A产生堵塞,由于B早已对id为100的行到了一个S锁。可是这时都还没产生死锁,由于只需手机客户端B在这时实行commit或是rollback就可以消除A的堵塞,让A取得X锁对产品的库存量开展改动。
# 可是这时手机客户端B也去减库存量,由于B也看到库存量是1
Update goods set `store`=`store` - 1;
# 这时B也发生了堵塞,由于A在select的情况下对id到了一个S锁。这时A在等B释放出来S锁,而B也等待A释放出来S锁,因此产生死锁。这个时候A和B都没法实行commit或rollback完毕事务管理和释放出来锁,只有一直互相等下来。怎么解决?实际上只需给 select 加X锁而不是加S锁就可以处理。
大家再次来一次:
# 手机客户端A实行
select `store` from goods where id = 100 for update; # 查到是1
# 还未commit
# 正好这时手机客户端B也实行到select
select `store` from goods where id = 100 for update; # 被A的X锁堵塞
# 这时A见到库存量是1,因此逐渐减库存量
Update goods set `store`=`store` - 1; # 库存量变成0
# A实行commit
# 手机客户端B的堵塞被消除,可是查到库存量早已是0了。因此舍弃减库存量的update实际操作。
所以说 应用S锁来查库存量剩下量不管从逻辑性上還是考虑到锁的层面全是错的,应当应用X锁来查。
因为mysql上锁的方法各式各样,因此 出現死锁的状况也是稀奇古怪。那麼假如在真正新项目中发生了死锁,大家该怎样清查?
死锁的排 查
面 对网上间断性的 MySQL 死锁难题,我的清查处理方式以下:
1.网上不正确日志警报发 现死锁出现异常
2.查询不正确日志的局部变量信息内容
3.查询 MySQL 死锁有关的日志
4.依据 binlog 查询死锁有关事务管理的实行內容
5.依据上述信息内容找到2个互相死锁的事务管理实行的 SQL 实际操作,依据本系列产品详细介绍的锁有关基础知识,开展剖析推论死锁缘故
6.改动业务流程编码
大家关键详细介绍1~4步。
最先在清查死锁以前,要先确保死锁日志和binlog日志早已打开:
查询死锁日志的打开 和 打开纪录死锁
show variables like "%innodb_print_all_deadlocks%";
set global innodb_print_all_deadlocks=1
查询binlog日志打开状况和部位
show variables like \"%log_bin%\";\n+---------------------------------+--------------------------------+\n| Variable_name | Value |\n+---------------------------------+--------------------------------+\n| log_bin | ON |\n| log_bin_basename | /var/lib/mysql/mysql-bin |\n| log_bin_compress | OFF |\n| log_bin_compress_min_len | 256 |\n| log_bin_index | /var/lib/mysql/mysql-bin.index |\n| log_bin_trust_function_creators | OFF |\n| sql_log_bin | ON |\n+---------------------------------+--------------------------------+\n"}">MariaDB [(none)]> show variables like "%log_bin%";
--------------------------------- --------------------------------
| Variable_name | Value |
--------------------------------- --------------------------------
| log_bin | ON |
| log_bin_basename | /var/lib/mysql/mysql-bin |
| log_bin_compress | OFF |
| log_bin_compress_min_len | 256 |
| log_bin_index | /var/lib/mysql/mysql-bin.index |
| log_bin_trust_function_creators | OFF |
| sql_log_bin | ON |
--------------------------------- --------------------------------
查询不正确日志部位
show variables like \"%log_error%\";\n+---------------+------------------------------+\n| Variable_name | Value |\n+---------------+------------------------------+\n| log_error | /var/log/mariadb/mariadb.log |\n+---------------+------------------------------+"}">MariaDB [(none)]> show variables like "%log_error%";
--------------- ------------------------------
| Variable_name | Value |
--------------- ------------------------------
| log_error | /var/log/mariadb/mariadb.log |
--------------- ------------------------------
死锁日志的获得
1.show engine innodb status 指令获得死锁信息内容,可是该指令只有获得近期一次的死锁信息内容。
2.根据在不正确日志搜索死锁日志。只需打开了死锁日志(innodb_print_all_deadlocks),那麼当产生死锁的情况下,会将死锁日志一起纪录到不正确日志中。
一定要注意,死锁不正确是Note等级的不正确,假如在不正确日志中找不着死锁的错误报告很有可能时由于设定了不正确等级造成Note等级的不正确沒有纪录到日志中。
我们可以查询log_error_verbosity自变量,它表明要纪录到不正确日志的等级。这一自变量有三个值:1、2、3,默认设置是3. 她们的实际意义是:
1 — Errors Only
2 — Errors and warnings
3 — Errors, warnings, and notes
set global log_error_verbosity=3; 表明纪录全部等级的不正确。
下边大家仿真模拟一个死锁:
手机客户端A、B另外实行begin
手机客户端A先实行:
select * from x where id=1 lock in share mode;
手机客户端B再实行:
update x set name='zbp333' where id=3;
update x set name='zbp111' where id=1; # 堵塞, 等候A释放出来对id=1的共享资源锁
最终手机客户端A实行:
select * from x where id=3 lock in share mode; # 会等候B释放出来id=3的排他锁,这时A和B相互之间等候,产生死锁下边是在不正确日志中获得的死锁日志:
2020-11-03 21:50:53 15899 [Note] InnoDB: Transactions deadlock detected, dumping detailed information.
2020-11-03 21:50:53 15899 [Note] InnoDB:
*** (1) TRANSACTION: # 1
TRANSACTION 4247, ACTIVE 60 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 15890, OS thread handle 140010633271040, query id 1221457 localhost root Updating
update x set name=’zbp111′ where id=1 #2
2020-11-03 21:50:53 15899 [Note] InnoDB: *** (1) WAITING FOR THIS LOCK TO BE GRANTED: #3
RECORD LOCKS space id 50 page no 3 n bits 88 index PRIMARY of table `test`.`x` trx id 4247 lock_mode X locks rec but not gap waiting # 4
Record lock, heap no 19 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 4; hex 80000001; asc ;;
1: len 6; hex 000000000000; asc ;;
2: len 7; hex 80000000000000; asc ;;
3: len 5; hex 7a62703131; asc zbp11;;
4: len 2; hex 7831; asc x1;;
2020-11-03 21:50:53 15899 [Note] InnoDB: *** (2) TRANSACTION: # 5
TRANSACTION 421485610914136, ACTIVE 71 sec starting index read
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1136, 2 row lock(s)
MySQL thread id 15899, OS thread handle 140010632656640, query id 1221458 localhost root Statistics
select * from x where id=3 lock in share mode # 6
2020-11-03 21:50:53 15899 [Note] InnoDB: *** (2) HOLDS THE LOCK(S): #7
RECORD LOCKS space id 50 page no 3 n bits 88 index PRIMARY of table `test`.`x` trx id 421485610914136 lock mode S locks rec but not gap # 8
Record lock, heap no 19 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 4; hex 80000001; asc ;;
1: len 6; hex 000000000000; asc ;;
2: len 7; hex 80000000000000; asc ;;
3: len 5; hex 7a62703131; asc zbp11;;
4: len 2; hex 7831; asc x1;;
2020-11-03 21:50:53 15899 [Note] InnoDB: *** (2) WAITING FOR THIS LOCK TO BE GRANTED: # 9
RECORD LOCKS space id 50 page no 3 n bits 88 index PRIMARY of table `test`.`x` trx id 421485610914136 lock mode S locks rec but not gap waiting # 10
Record lock, heap no 20 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 4; hex 80000003; asc ;;
1: len 6; hex 000000001097; asc ;;
2: len 7; hex 46000001c501d6; asc F ;;
3: len 6; hex 7a6270333333; asc zbp333;;
4: len 3; hex 787878; asc xxx;;
2020-11-03 21:50:53 15899 [Note] InnoDB: *** WE ROLL BACK TRANSACTION (2) #11
死锁日志中的关键一部分我就用 #n 标识了出去
#1 表明事务管理1
#2 表明死锁产生前事务管理1的最终一条sql(但并不是事务管理1递交前的最终一条sql)
#3 表明事务管理1的update x ….. 要想获得的锁。
#4 lock_mode X locks rec but not gap waiting 表明事务管理1想获得一个纪录锁因此等候(最后一个英语单词waiting)。
纪录锁(LOCK_REC_NOT_GAP): lock_mode X locks rec but not gap
空隙锁(LOCK_GAP): lock_mode X locks gap before rec
Next-key 锁(LOCK_ORNIDARY): lock_mode X
插进意向锁(LOCK_INSERT_INTENTION): lock_mode X locks gap before rec insert intention
#5 事务管理2
#6 表明死锁产生前事务管理2的最终一条sql
#7 和 #8 表明事务管理2那时候正拥有的锁时一个S纪录锁(是A手机客户端实行的第一个select拥有的锁)
#9 和 #10 表明事务管理2想获得一个S纪录锁(是A手机客户端第二个select要想获得的锁)
#11 表明mysql回退了事务管理2。表明是事务管理2产生的死锁,由于产生死锁会出错,出错便会全自动回退。
如今可以基本判断的是,是事务管理2在实行
select * from x where id=3 lock in share mode
的情况下发生了死锁,而且在死锁以前,事务管理2早已拥有了一个共享资源锁。
依据之上信息内容,大家再在binlog日志搜索大量案件线索,由于死锁日志只有得出2条和死锁相关的sql。要想了解死锁产生时的大量的sql只有在binlog找。
/var/www/binlog.txt"}"># 实行下边的句子将binlog日志的內容载入到一个txt
mysqlbinlog -uroot -p mysql-bin.000059 --base64-output=decode-rows -v > /var/www/binlog.txt
随后大家依据死锁日志产生死锁的時间:“2020-11-03 21:50:53”,在binlog中找这一時间左右的sql,并且死锁日志也告知了你产生死锁的sql,因而还可以依据这一sql在binlog日志中找这一条sql左右的有关sql,这种sql全是很有可能造成最终哪条sql产生死锁的缘故。
PS:仅有commit了的事务管理才会纪录到binlog中,rollback回退的事务管理中的全部sql是不容易计入binlog中的。
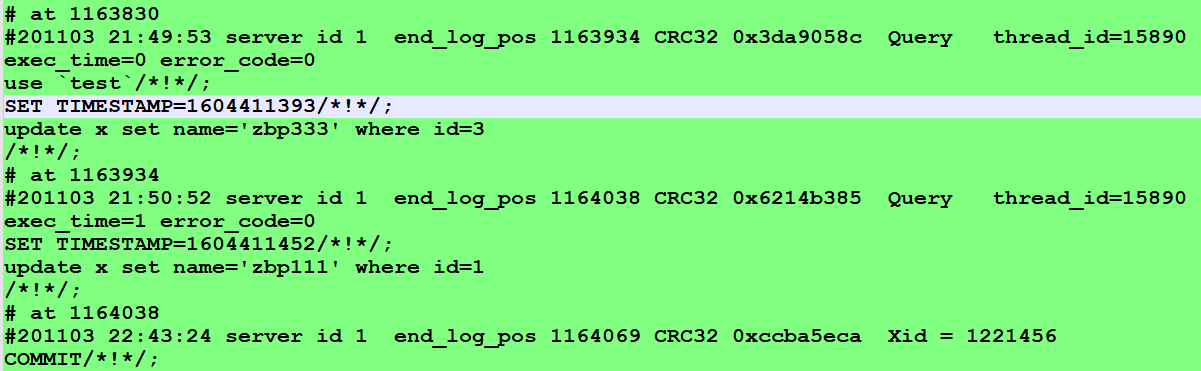
binlog日志只表明了手机客户端A的事务管理的sql,沒有纪录手机客户端B的事务管理的sql,由于手机客户端B的事务管理因为死锁出错被回退了。
死锁的防止
尽可能将长事务管理拆分为好几个小事务管理
查看时防止沒有whereif语句查看,并尽量应用数据库索引查看
如果可以的话尽可能应用等价查看,防止临键锁锁定空隙
