
Mysql中的锁
锁是电子计算机融洽好几个过程或是进程高并发浏览某一个資源的体制,用以维护保养数据信息一致性。
锁的归类
从对数据信息实际操作的种类分成:读锁和写锁
读锁(共享资源锁,S锁,share的简称):
相同一份数据信息,好几个读实际操作能够另外开展。
写锁(排他锁,X锁):
当某一客户对数据信息开展改动的情况下,不允许普通用户读或是写。
读锁和读锁中间不容易矛盾(意思是一行数据信息被一个手机客户端A加了读锁,别的手机客户端B还可以对这一条数据信息加读锁)
读锁和写锁中间会矛盾:这儿分成二种状况,一种是先加读锁,后加了写锁,这时加写锁会造成矛盾进到等候情况;另一种是先加写锁,后加读锁,这时加读锁造成矛盾进到等候情况。
写锁和写锁中间也会矛盾,要等候前一个写锁被释放出来另一个手机客户端才可以加写锁。
总结便是:读锁–读锁不堵塞,读锁–写锁会堵塞,写锁–读锁会堵塞,写锁–写锁会堵塞。
有时,实行句子时mysql会全自动给这一条句子锁上,有时又不容易,实际看储存模块。但是大家还可以手动式锁上。
怎样手动式锁上:
- 下排他锁:
Select/update/insert/delete …… for update; # 如果是innodb,这儿上的是行锁,假如在myisam这儿上的是表锁。
- 上共享资源锁:
Select/update/insert/delete …… lock in share mode;
从粒度分布来分:表锁和行锁
表锁:偏重于myisam,花销小,上锁快,并且不容易产生死锁;锁住粒度分布大,产生锁矛盾的几率高,高并发度低。
行锁:偏重于innodb,非常容易产生死锁;锁粒度分布小,高并发度较高。
表锁和行锁中也分读锁和写锁。
手动式以上锁:
Lock table t write; # 给表t上一个表级的写锁
Lock table t read; # 给表t上一个表级的读锁
大批量给表锁开启:
Unlock tables
Myisam只适用表锁。
Innodb适用表锁和行锁。
下边对于myisam和innodb二种模块产生高并发读写能力来了解读锁、写锁、表锁和行锁。
Myisam下的高并发上锁:
场景1:
手机客户端A先实行
Select * from t where id between 1 and 200000;
另外手机客户端B:
Select * from t where id = 200001;
結果: A和B另外实行select。
缘故:A实行select时,myisam会全自动为t表加一个表级的读锁;B实行select的情况下也会为t上一个表级的读锁。可是读锁中间不抵触,因此 B也锁上取得成功。AB能够另外读。
场景2:
手机客户端A先实行
Select * from t where id between 1 and 200000;
另外手机客户端B:
Update t set name=’111’ where id = 200001;結果: B等A实行select结束后才逐渐实行update。
缘故:A实行select时,myisam会全自动为t表加一个表级的读锁;B实行update的情况下也会为t上一个表级的写锁。可是读锁和写锁中间抵触,这时堵塞,因此 B要等A释放出来了读锁以后才可以上写锁。
场景3:
手机客户端B先实行
Update t set name=’111’ where id = 200001;
另外手机客户端A:
Select * from t where id between 1 and 200000;
結果: A等B实行完update以后才逐渐select
缘故:B先以上等级的写锁,这时A想上读锁被不成功,要等B开启后A才可以锁上。
场景4:
手机客户端A先实行
Select * from t where id between 1 and 200000 for update;
另外手机客户端B:
Select * from t where id = 200001;結果: B等A实行完后才实行。
缘故:应用了 for update,表明A实行这条select时并不是上一个读锁,只是上一个写锁(排他锁)。因此 B要锁上的情况下被写锁抵触堵塞。
Innodb下的高并发:
先表明几个方面:
最先,innodb中除开select以外,每一句sql单句全是一个事务管理。
例如:
# 实行
insert into t values (null, “zbp”)
# 它实际上真实实行的是
Begin;
insert into t values (null, “zbp”)
Commit;也有在全自动递交事务管理和非全自动递交事务管理的状况下,begin的实行次序
例如:
# 我想实行2个sql单句
Insert xxx1; # 隔10秒后,.我去实行下边这句话insert
Insert xxx2;# 在全自动递交事务管理(set autocommit=1)的状况下,它的真正实行状况以下:
Begin;
Insert xxx1;
Commit;
# 过去了10秒以后
Begin;
Insert xxx2;
Commit;# 在手动式递交事务管理(set autocommit=0)的状况下,它的真正实行状况以下:
Begin;
Insert xxx1;
Commit;
Begin;
# 过去了10秒情况下
Insert xxx2;
Commit;
Begin;这儿仅仅提一提非全自动递交事务管理的这一特性,但大部分状况大家的单sql事务管理全是应用全自动递交事务管理的。
第二点是:在事务管理中,实行sql的情况下很有可能全自动或手动式加了锁,可是实行完这一条sql后锁不容易释放出来,要直到commit后才会释放出来。
例如
Begin;
Update xxx # 到了锁1
Update xxx2 # 到了锁2
Delete from xxx where id=3 # 到了锁3
Commit; # 释放出来锁1,锁2,锁3
下边逐渐场景剖析:
手机客户端A和B另外begin,以后
场景1:
手机客户端A先:
Update t set name=’zbp’ where id = 3;
还没有commit
手机客户端B另外:
Select * from t where id=3;結果:A和B另外实行,B沒有堵塞。
缘故:在innodb事务管理中,读取数据的情况下默认设置不上锁,只是选用mvcc的体制载入undo日志中的历史记录。因此 ,A实行update的情况下,大会上一个行级的排他锁,可是B实行select的情况下,因为不用上写锁,因此 B不容易堵塞。
假定沒有mvcc体制,那麼B读取数据的情况下就必须加一个读锁,这时B会堵塞。因此 MVCC体制在一定水平上解决了读–写中间的高并发难题。MVCC在以后会再详细介绍
场景2:
手机客户端A先:
Select * from t where id=3 lock in share mode;
还没有commit
手机客户端B另外:
Update t set name=’111’ where id =3;
結果:A先实行完,B被堵塞沒有实行。
缘故:A手动式给id为3的数据信息加了一个行级的读锁。读锁和B的写锁相环路抵触因此 堵塞。B要直到A实行了commit的情况下才会释放出来锁,B才逐渐实行。
场景3:
手机客户端A先:
Select * from t where id=3 lock in share mode;
还没有commit
手机客户端B另外:
Update t set name=’111’ where id =4;結果:AB另外实行沒有堵塞。
缘故:A和B上锁的目标分别是不一样的行。这一事例表明innodb默认设置应用行锁并非表锁。
场景4:
手机客户端A先:
Select * from t where id=3 lock in share mode;
还没有commit
手机客户端B另外:
Select * from t where id=3 lock in share mode;
結果:AB另外开展沒有堵塞
缘故:A和B全是上的读锁。读锁中间是兼容的,因此 即便A还没有释放出来读锁,B能够实行。
不但是update的情况下会锁上,insert和delete的情况下也会对这方面数据信息下排它锁。
场景5:行锁衰退为表锁
手机客户端A和B另外begin,表t仅有id和name字段名,id是主键,name沒有设定数据库索引。以后
手机客户端A:
Select * from t where name=’zhangsan’ lock in share mode;
还没有commit
手机客户端B:
Update t set name=’lisi111’ where name=’lisi’ ;結果:A实行取得成功,B堵塞沒有实行
缘故:大家见到A和B实际操作的是两根不一样的行,可是在innodb中,假如对一条沒有采用数据库索引的sql开展锁上,便会从行锁衰退成表锁。因此 手机客户端A这儿就把全部表都锁定了。
手机客户端B想上一个写锁,但是因为A把全部表锁定了,因此 务必让等A commit了,把锁释放出来了B才可以实行,并且B实行的情况下也没用到数据库索引也是上的一个表锁。
有时大家的sql看起来本来where用了数据库索引,随后上锁发觉還是变成了表锁,这是由于你的数据库索引无效。你能用explain看一下他的key字段名是不是确实采用了数据库索引。
在这儿大家顺带再谈一谈上锁和数据库索引中间的关联:
大家说加行锁,实际上实质上是给数据库索引上锁。倘若一个表里边有3个字段名:id, name, extra
在其中id是主键,name是一般数据库索引。
如果我们实行一条以主键数据库索引为if语句:
Update x set extra=”xxx” where id > 100 and id <90;
上边应用到主键数据库索引,这时跑到主键的聚集索引的b 树中把id为90到100的行都锁了起來。随后再改extra字段名的值。
如果我们实行一条以一般数据库索引为标准的句子:
Update x set extra = “xxx” where name = “zbp” or name = “zhangsan”;
这儿也采用一般数据库索引,并且一般数据库索引沒有无效。因此 ,mysql会先去name这一二级数据库索引的B 树的叶子节点里将name为zbp和zhangsan的原素给锁定。
随后寻找叶子节点中zbp和zhangsan相匹配的id,再跑到聚集索引的B 树中把id相匹配的行给锁定。
随后再在聚类算法数据库索引中改动extra字段名的值。
换句话说二级数据库索引的纪录和主键数据库索引的纪录的这2行都被锁定了。
如果我们并以数据库索引的字段名为标准,那麼行锁变成表锁。
如今大家思索一个难题,倘若一个事务管理A实行 select * from x where id = 1 for update; 由于这儿采用了主键做为标准,因此 它会锁定主键数据库索引的B 树的id为1的数据信息。我想问一下,另一个事务管理B这时实行 select id from x where name=”zbp1”; (假定id为1的数据信息name便是zbp1),这一事务管理会堵塞吗。
要留意:select id from x where name=”zbp1”; 采用了覆盖索引,代表着这条sql不容易再去查主键数据库索引的B 树了。我的猜想是,A只锁定了主键数据库索引,沒有锁定二级数据库索引,因此 B应当不容易堵塞。
我试了一下,還是堵塞了,来看仅用到主键数据库索引做为标准不但把主键数据库索引给锁定了,还把二级数据库索引也锁定了。
锁上造成快照更新读变成当今读:
场景6:锁上造成快照更新读变成当今读
AB另外打开事务管理 begin; 表t中仅有一条纪录 (1, ‘zbp’)
手机客户端A:
Update t set name=’zbp2’ where id=1;
实行了commit
手机客户端B:
Select * from t;
Select * from t lock in share mode;結果:B的第一个查看結果是zbp,第二个結果是zbp2
缘故:A因为commit了,因此 A释放出来了锁,因此 B实行第二个select的情况下不容易堵塞。为何2次查看結果不一样:由于第一个select 没锁上,是一个快照更新读,读的是B这一事务管理内的由此可见版本号而B事务管理的由此可见版本号中name是zbp,第二个select到了锁,是一个当今读,读的是最新版的数据信息,因此 是zbp2;
意向锁
什么叫意向锁?
意向锁自身是一种表锁,并且是一种不容易和行级锁矛盾的表锁。Innodb中,(意愿)表锁和行锁能够并存。
在innodb中,当mysql要对数据信息加行锁的情况下会先对全部表加一个意向锁,以后才往相匹配的行加行锁。这时这一表既加了行锁又加了表锁,因此 行锁和表锁并存。
意向锁是mysql全自动加的,不用大家手动式加。
意向锁分成
意愿写锁(IX):当必须对数据信息加行级写锁时,mysql 会先向全部表加意向写锁
意愿读锁(IS):当必须对数据信息加行级读锁时,mysql 会先向全部表加意向读锁
怎么会出現意向锁,它的出現是为了更好地要处理什么问题?
场景7:
有一张 users 表: MySql,InnoDB,Repeatable-Read:users(id PK,name)
假定有100W条数据信息
手机客户端A:
Begin;
Update users set name=’zbp’ where id=5w;
A未提交
手机客户端B要立即给users表加一个表级的读锁:
Lock tables users read;
倘若沒有意向锁的存有。那麼B要想给表加一个表等级的读锁,B就需要分辨users表是不是早已被别的手机客户端的事务管理加了写锁(包含表级写锁和行级写锁)。因此 ,mysql便会对100W条数据信息开展一一解析xml,直至解析xml到第5w条纪录的情况下mysql发觉:哦~,第10W条纪录被上了一个写锁,因此B逐渐堵塞,等候A把写锁释放出来才锁上。
可是这一一条条解析xml的全过程很费cpu并且用时。
为了更好地处理这一状况,mysql能够在手机客户端A上行下行级写锁以前先上一个意愿写锁(IX)。B得加表级读锁的情况下立即发觉user表早已被上了一个表级的意愿写锁,这个时候B也无需去一个个解析xml数据信息看users是不是被锁了,由于意向锁早已确立对你说users表早已被锁。
因此 ,意向锁的一个作用便是有一种通告的作用,立即告知别的想以上锁的事务管理说:这一表早已被行锁给锁住了一些行了,你不能再在上面加一个表锁了哦。
意向锁中间相互之间兼容

这一非常好了解:
比如事务管理A update 了users表格中id为1的数据信息未提交,事务管理B update 了id为100的数据信息。这时users表被上了4把锁:A加上的意愿写锁和id=1上的行级写锁、B加上的意愿写锁和id=100上的行级写锁
这一全过程不容易堵塞,就早已表明了事务管理A加了IX锁以后事务管理B也可以取得成功上IX锁,不然B就无法改变id为100的数据信息了。
一个事务管理的意向锁和此外一个事务管理的行锁兼容
用上边的事例一样能够了解。事务管理A上的IX锁以后,事务管理B依然可以取得成功的给id为100的行上行下行锁。
一个事务管理的意向锁和另一个事务管理的表锁相互独立(但意愿读锁和表级读锁不相互独立)
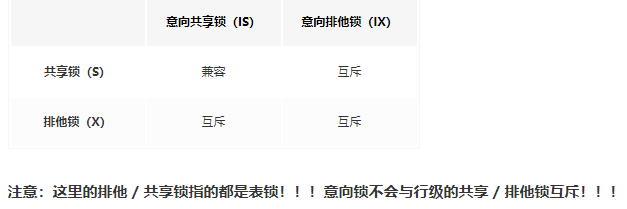
意向锁是innodb适用多粒度分布锁的反映(适用表锁和行锁并存的反映)
行锁依照优化算法来分,又可以分成:纪录锁(record lock),空隙锁(gap lock)和临键锁(next-key lock)。
空隙锁和临键锁(处理幻读)
最先什么叫空隙?
举个事例:有一个innodb表,3个字段名,id, name, extra, id是主键,name是一般数据库索引。
---- ------- -------
| id | name | extra |
---- ------- -------
| 1 | zbp | xxx |
| 3 | zbp3 | xxx |
| 4 | zbp4 | xxx |
| 5 | zbp5 | xxx |
| 6 | zbp6 | xxx |
| 9 | zbp6 | xxx |
| 10 | zbp6 | xxx |
| 12 | zbp12 | xxx |
| 13 | zbp13 | xxx |
| 14 | zbp14 | xxx |
---- ------- ------- 针对id来讲,id并不是持续的,这一表的id的空隙有5个,分别是:1以前,1/3中间(缺了个2),6/9中间(缺了个7和8),10/12中间(缺了11)及其14以后。
针对name数据库索引来讲,不反复的值中间全是空隙,因此 name字段名的空隙有9个。
针对extra字段名而言,因为extra并不是数据库索引字段名,因此 不会有空隙一说。并且对extra锁上便是一个表锁,表锁把全部表(包含全部行和全部空隙)都锁定了。
什么叫空隙锁?
空隙锁实际上实质上也是一个行锁。它能够锁定行与行中间的空隙,促使insert没法插进数据信息到这种空隙中。
什么叫临键锁?
临键锁便是纪录锁 空隙锁。他不但能锁定行,还能锁定行中间的空隙,促使insert没法插进数据信息到这种空隙中。最普遍的表达形式便是where应用范畴标准的行锁。
场景剖析以下:
A、B都实行begin
1 and id 场景1:
手机客户端A:
Select * from x where id>1 and id < 4 for update;
A未commit
手机客户端B:
Insert into x values (2, ‘zbp2’); # 产生堵塞。
# 或是实行 update x set id=2 where name='zbp14'; 也会堵塞
缘故:A的where标准不但把行1,3,4给锁定了,还把1和3中间的空隙给锁定了,这时B就没法插进id为2的数据信息。
该事例A采用了临键锁
场景2:
手机客户端A:
Select * from x where id=1 for update;
A未commit
手机客户端B:
Insert into x values (2, ‘zbp2’); # 一切正常插进。
# 或是实行 update x set id=2 where name='zbp14'; 改动取得成功缘故:A仅仅把行1锁定了,可是沒有锁定1和3中间的空隙。假如id并不是主键或是唯一键,而仅仅一个一般数据库索引,这时A的select便会另外把行1自身和(-∞,1)与(1,3)这两个间隙都锁定。这一事例表明当应用主键或是唯一索引应用精准标准(=,in等)击中了一条纪录时,临键锁会退级为纪录锁。
该事例A采用了纪录锁,没能采用临键锁
2 and id场景2-2:
手机客户端A:
Select * from x where id>2 and id<=6;
手机客户端B:
insert into x values (7,'zbp7','xxx'); # 堵塞
# insert into x values (2, ’zbp2’, ‘xxx’); 也堵塞
缘故:A锁定了:(1,3)空隙 和[3,6]中间的4行 和 (6,9) 的空隙。
场景3:
手机客户端A:
Select * from x where id=7 for update;
A未commit
手机客户端B:
Insert into x values (7, ‘zbp7’); # 产生堵塞。
# 或是实行 update x set id=7 where name='zbp14'; 也会堵塞缘故:A沒有锁定一切的行,可是锁定了行6和行9中间的空隙(没锁定行,只锁定了空隙),这时B就没法插进id为7或是id为8的数据信息。这儿上的是一个空隙锁而不是纪录锁,由于where id=7沒有击中一切行。
一样的 如果是 Select * from x where id=16 for update; 便会把(14, 无穷)空隙给锁定,这时B实行 insert into x values (null,”zbp15”,”xxx”) 或是 实行insert into x values (17,”zbp17”,”xxx”)都是会被堵塞。
该事例A采用了空隙锁
场景4:
手机客户端A:
Select * from x where name=’zbp5’ for update;
A未commit
手机客户端B:
Insert into x values (null, ‘zbp5’); # 产生堵塞。
# 如果是实行:Insert into x values (null, ‘zbp55’); 依然会产生堵塞,由于zbp55也在(zbp5, zbp6)这一空隙中间。缘故:A不但把zbp5的行给锁定了,也把(zbp4, zbp5) 和 (zbp5, zbp6)这两个空隙给锁定了(和场景2比照,name是个一般数据库索引,因此 这儿采用的是一个临键锁而沒有衰退为一个纪录锁)。因此 B没法插进zbp5和zbp55
该事例采用了临键锁
场景5:
手机客户端A:
Select * from x where id=5 for update; # id为5的行,它的name字段名是zbp5
A未commit
手机客户端B:
Insert into x values (null, ‘zbp5’); # 插进取得成功。
# 可是update x set name='zbp55' where name='zbp5'; 会堵塞缘故:这道题大家只需想一想最底层的B 树就非常容易了解。A查的是id为5的行,而且给这一行上锁,也就是给主键数据库索引的B 树中的叶连接点的id=5的行原素加行锁,可是B增加数据信息是往B 树的最后一个叶连接点以后((14, ∞)这一空隙)插进一个行原素,而(14, ∞)这一空隙并沒有被锁定。再看二级数据库索引的B 树,实际上二级数据库索引中name为zbp5的原素早已被锁定,可是zbp5的空隙沒有锁,因此 插进的数据信息的name为zbp5也不会堵塞,可是变更name为zbp5的sql堵塞了。
该事例采用了纪录锁
=5 for update;\tA未commit\n\n手机客户端B:\nInsert into x values (null, ‘zbp5’);\t\t# 堵塞。"}">场景6:
手机客户端A:
Select * from x where id>=5 for update; A未commit
手机客户端B:
Insert into x values (null, ‘zbp5’); # 堵塞。
缘故:A把(14, ∞)这一空隙给锁定了,而B增加数据信息的id肯定是15,在这个区段当中,因此 被堵塞了。
该事例采用了临键锁
=13 and id=13 and id场景7:不只是select会造成临键锁,update和delete也会
手机客户端A:
Update x set name=’zbpxxx’ where id>=13 and id<=14;
# 或是 delete from x where id>=13 and id<=14
A未commit
手机客户端B:
Insert into x values (null, ‘zbp5’); # 堵塞。
缘故:A的update或delete把(14, ∞)这一空隙给锁定了,而B增加数据信息的id肯定是15,因此 被堵塞了。
该事例采用了临键锁
场景8:一切正常状况下,insert不容易造成临键锁
手机客户端A:
insert into x values (7,'zbp7','xxx');
A未commit
手机客户端B:
insert into x values (8,'zbp8','xxx'); # 未堵塞。
# insert into x values (7,'zbp7','xxx'); 堵塞。缘故:这一事例中A沒有锁定(6,9)这一空隙,因此 B往这一空隙插进都没有堵塞。但是锁定了id=7的行。
自然,insert尽管沒有锁定空隙,可是insert也是会锁上的,当表中有唯一索引的情况下,insert插进大会上一个共享资源锁查验我想insert的值是不是在表格中早已有重复值,查验完后会插进一条数据信息,并对这一条插进的数据信息上一个行级的X锁。
临键锁在下列2个标准的时候会退级变成空隙锁或是纪录锁:
当查看未击中每日任务纪录时,会退级为空隙锁
当应用主键或是唯一索引的精准标准(in/=)击中了一条纪录时,会退级为纪录锁。可是假如用一般数据库索引击中一条纪录,不容易退级为纪录锁
场景9: 临键锁退级的情景
手机客户端A:
update x set name="zbp7" where id=7; # A试着改动一条不会有的纪录,这时where沒有击中,由于id=7的纪录压根不会有
# 或是实行 delete from x where id=7 删掉一条不会有的行
A未提交
手机客户端B:
insert into x values (8, "zbp8", "xxx"); # 插进数据信息8,堵塞缘故:id为7的行不会有,因此 沒有击中这一行便会把(6,9)这一空隙都锁定,因此 id=8的数据信息没法插进
假定如今id=7的纪录时存有的,A实行update x set name=”zbp777” where id=7;便会退级为纪录锁(由于id是主键,并且这儿是一个精准标准而不是范畴标准),这时能够插进id为8的纪录不容易堵塞。
场景10:delete删掉一条数据信息
手机客户端A:
Delete from x where id=3; # 删除了id=3的行
手机客户端B:
insert into x values (2, "zbp2", "xxx"); # 不容易堵塞
# insert into x values (3, "zbp3", "xxx"); # 堵塞了缘故: 删的是一条存有的纪录,并且是用主键精准删掉。因此 他是一个纪录锁,不容易锁定(1,4)这一空隙。因此 id=2的纪录能够插进,而id=3的纪录不可以插进。
我们可以在一个事务管理查看的情况下再加上临键锁来处理幻读难题,它便是根据可以锁定行与行的空隙,促使一个事务管理在学的情况下别的事务管理没法插进来保证的。
