Homework III
kNN Classifier代写 You are asked to build a k-Nearest Neighbor (kNN) classifier. The data set for evaluation is the heart data set.
Due date: Feb. 28, 2019 (Before the Class)
Problem 1: kNN Classifier (20 points) kNN Classifier代写
You are asked to build a k-Nearest Neighbor (kNN) classifier. The data set for evaluation is the heart data set. More information about the data can be found here https://archive.ics. uci.edu/ml/datasets/Statlog+(Heart). The data set is included in homework-3-data-set.zip on ICON. In the heart data folder, there are three files: “trainSet.txt”, “trainLabels.txt”, and “test.txt”.
Each row of “trainSet.txt” corresponds to a data point whose class label is provided in the same row of “trainLabels.txt”. Each row of “testSet.txt” corresponds to a data point whose class label needs to be predicted. You will train a classification model using “trainSet.txt” kNN Classifier代写and“trainLabels.txt”, and use it to predict the class labels for the data points in “testSet.txt”.Use the leave one out cross validation on the training data to select the best k among {1, 2, . . . , 10}. Report the averaged leave-one-out error (averaged over all training data points) for each k ∈{1, 2, . . . , 10} and the best k used for predicting the class labels for test instances. You should also report the predicted labels for the testSet.
Problem 2: Na¨ıve Bayes for Text Classification (50 points)kNN Classifier代写
In this problem, you are asked to implement a Na¨ıve Bayes Classifier for text categorization. In particular, given a document x = (x1, . . . , xm), where xj is the occurrence of word wj in the document, we model Pr(x|Ck) as
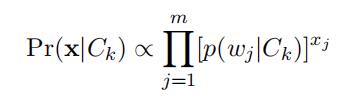
where p(wj|Ck) stands for the probability of observing the word wj in any document from categoryCk. Given a collection of training documents x1, . . . , xnk in category Ck, where xi = (xi , . . . , xi ),1 m the probabilities of p(wj|Ck) can be estimated by MLE, i.e.,
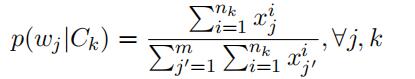
To avoid the issue that some words may not appear in training documents of a certain class, the estimated probabilities are usually smoothed. One smoothing method is Laplace smoothing whichcomputes p(wj|Ck) by
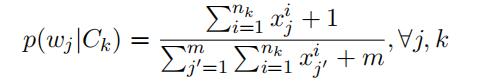
The log-likelihood for (x, y = k) is given by
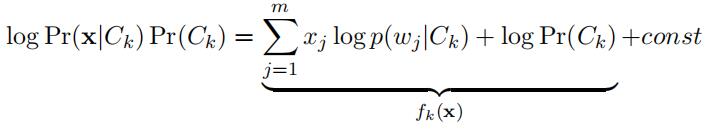
where Pr(Ck) can be estimated by Pr(Ck) = nkk=1 nkand fkcan be considered as aprediction score of x for the k-th class. The class label of a test document x can be predicted by k∗ = arg max1≤k≤K fk(x).
The data set for training and evaluation is the 20NewsGroup data, which is included in the provided zip file. You will find six text files in this data set: train.data, train.label, train.map, test.data, test.label, and test.map, where the first three files are used for training and the last three files are for testing. In the train.data file, you will find the word histograms of all documents; each row is a tuple of format (document-id, word-id, word-occurrence). kNN Classifier代写
The class labels of training documents can be found in train.label with the order corresponding to training documents’ id, and the topic of each class can be found in train.map. Similarly, the word histograms and the class assignments of test documents can be found in test.data and test.label, respectively. In this problem, you need to train a Na¨ıve Bayes classifier with the Laplace smoothing using the training data and apply the learned classifier to predict the class labels for the test documents. You need to submit your code for implementing the Naive Bayes classifier and (b) report theclassification accuracy (the proportion of test documents that are classified correctly) over the test documents. kNN Classifier代写Note: You code should be able to generate a ftle that contains the predicted labels of test documents in the same order. Include instructions on how to run your code so that TA can run your
Problem 3: PCA (30 points)
You are asked to build a k-Nearest Neighbor (kNN) classifier based on dimenationality reduced data by PCA. The data set for evaluation is the gisette data set. More information about the data can be found here https://archive.ics.uci.edu/ml/datasets/Gisette. The data set is included in homework-3-data-set.zip on ICON. The data is in the same format as that in Problem 1.
You will train a classification model using “trainSet.txt” and “trainLabels.txt”, and use it to predict the class labels for the data points in “testSet.txt”. First, train a kNN based on the original features and then conduct PCA on the data and learn a kNN model using the reduced data. Report the performance of both models on the testing data. For learning both models, you should also conduct cross-validation (of your choice) to select the best k. Describe the cross-validation approach and report the best value of k for both models. You need to submit your code as well.kNN Classifier代写
Problem 4: Median Distance of Nearest Neighbor (Optional: 20 points)kNN Classifier代写
Consider N data points uniformly distributed in a p-dimensional unit ball centered at origin. Consider the nearest neighbor of the origin. Prove that the median distance from the origin to the closest data point is:
d(p, N ) = .1 − 2−1/N Σ1/p

更多其他:C++代写 java代写 r代写 代码代写 金融代写 python代写 web代写 物理代写 数学代写 考试助攻 C语言代写 计算机代写 finance代写 code代写
