
GISC 412: Data challenge
Jupyter notebooks代写 The data challenge is an opportunity to put the skills you have learned in the course into action. You have been given four datasets
Background Jupyter notebooks代写
The data challenge is an opportunity to put the skills you have learned in the course into action. You have been given four datasets: two consist of point data (5,252,032 and 5,471,960 points respectively), one of polygon data, and one containing line data. The smallest dataset is 50 Mb, the largest more than 1Gb. The point data represent image positions and have the following format (ids, user-ids, longitude, latitude, x, y). One dataset was sourced from georeferenced Flickr images and the other from the georeferenced Geograph images (Antoniou et al. 2010; Purves et al. 2011). Note that in Flickr user-ids are strings, while in Geograph they are integers, and x and y coordinates are in OSGB36 coordinates.
The polygons represent borders of political units in the UK. However, these units can take different forms: namely so-called unitary authorities in Scotland and Wales, local government districts in Northern Ireland and local authorities in the Republic of Ireland. In England, the situation is more complicated with a mix of metropolitan boroughs, London boroughs, unitary authorities and so- called two-tier non metropolitan counties. Figure 1 shows a map of these borders, and indicates to which class different polygons belong.Jupyter notebooks代写
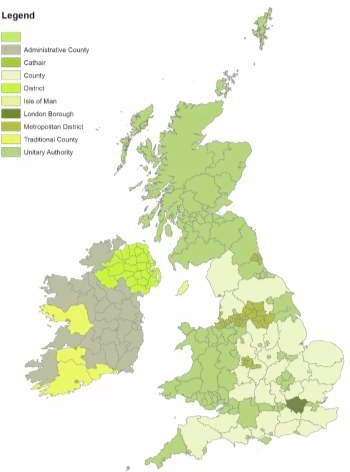
Figure 1: Political units in the UK and Republic of Ireland
Finally, the line data represent the mean high-water mark in for Great Britain. Note that these data include ids for individual units, and areas. The smallest areas with a high-water mark are very small indeed!Jupyter notebooks代写

Tasks Jupyter notebooks代写
We want to know more about the relationship between the number of images taken and the political units with which they are associated. We also want to compare the two image datasets and identify differences between them. Finally, we are also interested in bias introduced by individual users on the values which we produce. To find this out, you will need to use everything we discussed in the course, and implement a few extra methods to do some simple statistics.Jupyter notebooks代写
You can work individually or in pairs. In your projects you have to investigate some of following six questions (2A and 2B count as one question). Individuals should answer three questions,
groups of two should answer all six questions:
- Basicsummary statistics describing each image dataset; the mean centroid, the standard deviational ellipse, and the area and perimeter of the convex hull.
- A)The 30 political units that contain the most images in Flickr and Geograph sorted by rank,
B) The 30 political units that contain the least images in Flickr and Geograph sorted by rank.
3.A discussion of whether the area of political units is correlated with the number of images found for Flickr orGeograph?Jupyter notebooks代写
4.A discussion of whether there is a relationship between being near to the high-water mark and the number of pictures taken in Flickr orGeograph?
5.The 10, 100, and 1000 images nearest to the following points (expressed in OSGB36) inFlickr and Geograph: (216578, 771230) (528926, 179699) and (309772, 778633). For the point sets thus created, calculate the area of their bounding boxes and convex hulls respectively. To which political units do these bounding boxes and convex hulls belong?
6.Findthe five most active photographers (as represented by their IDs) in each dataset, and a ranked list of the political units in which they took photographs.
To answer the questions, you must implement code to carry out every step, including:Jupyter notebooks代写
- Reading the data in from the files you were given (you can use R orPython).
- Build data structures to store all the data appropriately. If you choose, you can utilise a PostgreSQL database but it is not required.
- Implement a solution for each question using R or Python.
Results Jupyter notebooks代写
The code can be prepared in R Studio or, if using Python in a suitable code editor. Alternately, you can develop the code on your own computer but I will be unable to provide individual troubleshooting support if things aren’t working the way you expect (e.g., loading libraries, etc.). If you are feeling adventurous then you can create a “reproducible” document that includes code that can be run inside your report using Knitr, or if you are using Python then you can use Jupyter notebooks with Markdown and interspersed code cells.
You’ll submit the following:
- Your solutions to the questions you chose to answer, such that we can compare the solutions of the different groups. Include graphs and maps as appropriate tocommunicate your solutions.Jupyter notebooks代写
- An overview of the way in which you read in, stored, and processed the data, with an annotated diagram showing the workflow you used to answer the questions. Theannotation should describe the most important functions and tools you used. In this document you will also make clear who did what.
- A maximum one-page description for each of the problems you solved as well as any problems you encountered. You should also discuss briefly what you think your resultsmean– to do this you will have to think a little about what the data actually represent.
- Your well-commented code.Jupyter notebooks代写
Hints Jupyter notebooks代写
The files will be too big to just read everything into a very simple data structure at once. You will need to either create interim files, or use clever techniques to minimize the amount of data in memory. You should test things on much smaller datasets, and remember, using Excel or ArcGIS to look at the data is fine – your solution has to work without recourse to these (or any other non-R or Python tools). Note, too, that the complete files may be too big to load into Excel and many other standard tools. Remember it is also acceptable to make approximations, provided you explain how and the implications of such approximations. Finally, although the data have been prepared for you, they may still contain unexpected outliers or other undesirable features.
Hand-in and interim presentations
Final hand-in is Friday, 22 October at midnight. On the final day of class 15 October, each group will give a brief progress presentation where you tell us all where you are and what problems you are encountering.
Sources and useful information
Antoniou, V., Morley, J., & Haklay, M. (2010). Web 2.0 geotagged photos: Assessing the spatial dimension of the phenomenon. Geomatica, 64(1), 99-110.
Flickr: www.flickr.com
Geograph: www.geograph.org.uk
Ordnance Survey Boundary Line (source for England, Wales and Scotland boundaries): https://www.ordnancesurvey.co.uk/docs/user-guides/boundary-line-userguide.pdf
Purves, R.S., Edwardes, A., & Wood, J. (2011). Describing place through user generated content. First Monday, 16(9).Jupyter notebooks代写

其他代写:考试助攻 计算机代写 java代写 function代写 paper代写 web代写 编程代写 report代写 数学代写 algorithm代写 金融经济统计代写 Exercise代写 finance代写 python代写 java代写 code代写 代码代写 project代写 作业帮助 course代写
