副标题#e#
自动装箱和拆箱问题是Java中一个老生常谈的问题了,本日我们就来一些看一下装箱和拆箱中的若干问题。本文先报告装箱和拆箱最根基的对象,再来看一下口试笔试中常常碰着的与装箱、拆箱相关的问题。
以下是本文的目次纲要:
一.什么是装箱?什么是拆箱?
二.装箱和拆箱是如何实现的
三.口试中相关的问题
若有不正之处,请体谅和品评指正,不胜谢谢。
请尊重作者劳动成就,转载请标明原文链接:
http://www.cnblogs.com/dolphin0520/p/3780005.html
一.什么是装箱?什么是拆箱?
在前面的文章中提到,Java为每种根基数据范例都提供了对应的包装器范例,至于为什么会为每种根基数据范例提供包装器范例在此不举办叙述,有乐趣的伴侣可以查阅相关资料。在Java SE5之前,假如要生成一个数值为10的Integer工具,必需这样举办:
Integer i = newInteger(10);
而在从Java SE5开始就提供了自动装箱的特性,假如要生成一个数值为10的Integer工具,只需要这样就可以了:
Integer i = 10;
这个进程中会自动按照数值建设对应的 Integer工具,这就是装箱。
那什么是拆箱呢?顾名思义,跟装箱对应,就是自动将包装器范例转换为根基数据范例:
Integer i = 10; //装箱 int n = i; //拆箱
简朴一点说,装箱就是 自动将根基数据范例转换为包装器范例;拆箱就是 自动将包装器范例转换为根基数据范例。
下表是根基数据范例对应的包装器范例:

二.装箱和拆箱是如何实现的
上一小节相识装箱的根基观念之后,这一小节来相识一下装箱和拆箱是如何实现的。
我们就以Interger类为例,下面看一段代码:
public class Main {
public static void main(String[] args) {
Integer i = 10;
int n = i;
}
}
反编译class文件之后获得如下内容:
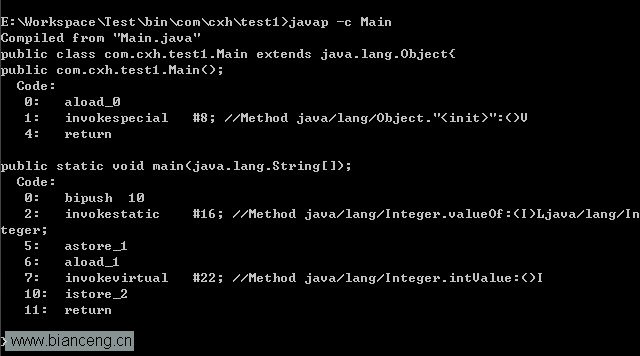
#p#副标题#e#
从反编译获得的字节码内容可以看出,在装箱的时候自动挪用的是Integer的valueOf(int)要领。而在拆箱的时候自动挪用的是Integer的intValue要领。
其他的也雷同,好比Double、Character,不相信的伴侣可以本身手动实验一下。
因此可以用一句话总结装箱和拆箱的实现进程:
装箱进程是通过挪用包装器的valueOf要领实现的,而拆箱进程是通过挪用包装器的 xxxValue要领实现的。(xxx代表对应的根基数据范例)。
三.口试中相关的问题
固然大大都人对装箱和拆箱的观念都清楚,可是在口试和笔试中碰着了与装箱和拆箱的问题却不必然会答得上来。下面罗列一些常见的与装箱/拆箱有关的口试题。
1.下面这段代码的输出功效是什么?
public class Main {
public static void main(String[] args) {
Integer i1 = 100;
Integer i2 = 100;
Integer i3 = 200;
Integer i4 = 200;
System.out.println(i1==i2);
System.out.println(i3==i4);
}
}
也许有些伴侣会说城市输出false,可能也有伴侣会说城市输出true。可是事实上输出功效是:
true false
为什么会呈现这样的功效?输出功效表白i1和i2指向的是同一个工具,而i3和i4指向的是差异的工具。此时只需一看源码便知毕竟,下面这段代码是Integer的valueOf要领的详细实现:
public static Integer valueOf(int i) {
if(i >= -128 && i <= IntegerCache.high)
return IntegerCache.cache[i + 128];
else
return new Integer(i);
}
而个中IntegerCache类的实现为:
private static class IntegerCache {
static final int high;
static final Integer cache[];
static {
final int low = -128;
// high value may be configured by property
int h = 127;
if (integerCacheHighPropValue != null) {
// Use Long.decode here to avoid invoking methods that
// require Integer's autoboxing cache to be initialized
int i = Long.decode(integerCacheHighPropValue).intValue();
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - -low);
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
}
private IntegerCache() {}
}
#p#分页标题#e#
从这2段代码可以看出,在通过valueOf要领建设Integer工具的时候,假如数值在[-128,127]之间,便返回指向IntegerCache.cache中已经存在的工具的引用;不然建设一个新的Integer工具。
上面的代码中i1和i2的数值为100,因此会直接从cache中取已经存在的工具,所以i1和i2指向的是同一个工具,而i3和i4则是别离指向差异的工具。
2.下面这段代码的输出功效是什么?
public class Main {
public static void main(String[] args) {
Double i1 = 100.0;
Double i2 = 100.0;
Double i3 = 200.0;
Double i4 = 200.0;
System.out.println(i1==i2);
System.out.println(i3==i4);
}
}
查察本栏目
也许有的伴侣会认为跟上面一道题目标输出功效沟通,可是事实上却不是。实际输出功效为:
false false
至于详细为什么,读者可以去查察Double类的valueOf的实现。
在这里只表明一下为什么Double类的valueOf要了解回收与Integer类的valueOf要领差异的实现。很简朴:在某个范畴内的整型数值的个数是有限的,而浮点数却不是。
留意,Integer、Short、Byte、Character、Long这几个类的valueOf要领的实现是雷同的。
Double、Float的valueOf要领的实现是雷同的。
3.下面这段代码输出功效是什么:
public class Main {
public static void main(String[] args) {
Boolean i1 = false;
Boolean i2 = false;
Boolean i3 = true;
Boolean i4 = true;
System.out.println(i1==i2);
System.out.println(i3==i4);
}
}
输出功效是:
true
true
至于为什么是这个功效,同样地,看了Boolean类的源码也会一目了然。下面是Boolean的valueOf要领的详细实现:
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
而个中的 TRUE 和FALSE又是什么呢?在Boolean中界说了2个静态成员属性:
public static final Boolean TRUE = new Boolean(true);
/**
* The <code>Boolean</code> object corresponding to the primitive
* value <code>false</code>.
*/
public static final Boolean FALSE = new Boolean(false);
至此,各人应该大白了为何上面输出的功效都是true了。
4.谈谈Integer i = new Integer(xxx)和Integer i =xxx;这两种方法的区别。
虽然,这个题目属于较量宽泛范例的。可是要点必然要答上,我总结一下主要有以下这两点区别:
1)第一种方法不会触发自动装箱的进程;而第二种方法会触发;
2)在执行效率和资源占用上的区别。第二种方法的执行效率和资源占用在一般性环境下要优于第一种环境(留意这并不是绝对的)。
假如有哪位伴侣有增补的内容,接待下方留言,不胜谢谢。
作者:海子
出处:http://www.cnblogs.com/dolphin0520/
