副标题#e#
在上篇博文《Web版RSS阅读器(三)——理会在线Rss订阅》中,已经提到了碰着的问题,这里再具体说一下。
在理会rss名目标订阅时,碰着的最主要的问题是,呈现了“Server returned HTTP response code: 403 for URL: http://xxxxxx”的错误,百度一下就知道,这是在网站会见中很常见的一个错误,处事器领略客户的请求,但拒绝处理惩罚它。即拒绝会见!接着查资料,得知某些处事器(好比CSDN博客)拒绝java作为客户端举办对其的会见,所以在理会时,会抛异常。
不让会见怎么办,别怕,我们上有政策,下有对策。通过配置User-Agent来欺骗处事器,从而会见处事器。
connection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)"); //用UA伪装会见毗连工具
可是折腾了半天,发明只有修改rsslib4j.jar才气给毗连工具配置UA。只好找源码修改一下了,N久之后,在Google Code上猎取到一个开源的项目newrsslib4j,它是在rsslib4j的基本上修改而来的,项目开源主页:http://code.google.com/p/newrsslib4j/。满怀欣喜的下载下来,功效发明,依旧有403的问题。一狠心,本身来做一个rsslib,然后就checkout了newrsslib4j的源码,本身动手窜改。
1. 修改403 forbidden问题。
修改org.gnu.stealthp.rsslib包中的RssParser类的setXmlResource()要领,给URLConnection工具,添加UA。
/**
* Set rss resource by URL
* @param ur the remote url
* @throws RSSException
*/
public void setXmlResource(URL ur) throws RSSException{
try{
URLConnection con = u.openConnection();
//-----------------------------
//添加时间:2013-08-14 21:00:17
//人员:@龙轩
//博客:http://blog.csdn.net/xiaoxian8023
//添加内容:由于处事器屏蔽java作为客户端会见rss,所以配置User-Agent
con.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
//-----------------------------
con.setReadTimeout(10000);
String charset = Charset.guess(ur);
is = new InputSource (new UnicodeReader(con.getInputStream(),charset));
if (con.getContentLength() == -1 && is == null){
this.fixZeroLength();
}
}catch(IOException e){
throw new RSSException("RSSParser::setXmlResource fails: "+e.getMessage());
}
}
修改org.mozilla.intl.chardet包中的Charset类的guess()要领,注释掉本来的InputStream工具,建设URLConnection,配置User-Agent,通过URLConnection工具建设InputStream :
//judge from url
public static String guess(URL url) throws IOException {
//-----------------------------
//修改时间:2013-08-14 21:00:17
//人员:@龙轩
//博客:http://blog.csdn.net/xiaoxian8023
//修改内容:注释InputStream,建设URLConnection,配置User-Agent,通过URLConnection工具建设InputStream
//InputStream in = url.openStream();
URLConnection con = url.openConnection();
con.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
InputStream in = con.getInputStream();
//-----------------------------
return guess(in);
}
#p#副标题#e#
2. 添加获取文章摘要的要领
测试今后,发明Rss名目标订阅,居然没有提供一个获取内容摘要的要领。所以,继承修改。修改org.gnu.stealthp.rsslib包中的RssObject类,添加一个getSummary()要领,用来获取内容摘要:
//-----------------------------------
//添加时间:2013-08-14 19:32:15
//人员:@龙轩
//添加内容:添加getSummary()要领,返回文章摘要信息
/**
* Get the element's summary
* @return the summary
*/
public String getSummary(){
String summary = getDescription();
if (summary.length() >= 300) {
summary = summary.substring(0, 300);
}
String regEx_html = "\\s|<[^>]+>|&\\w{1,5};"; // 界说HTML标签和非凡字符的正则表达式
Pattern pattern = Pattern.compile(regEx_html,Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(summary);
summary = matcher.replaceAll(""); // 过滤script标签
if (summary.length() >= 100) {
summary = summary.substring(0, 100);
}
summary = summary + "...";
return summary;
}
//添加竣事-----------------------------------------------
3. 办理理会不完全问题
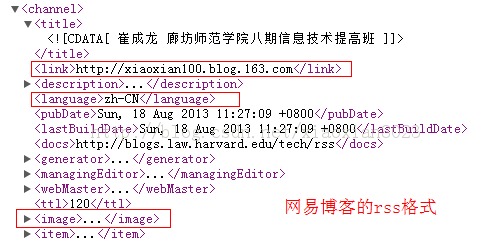
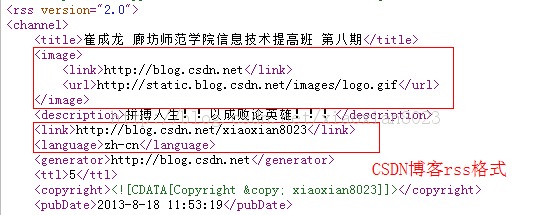
网易博客可以很好的理会出博客的link,language等节点,可是csdn、某些新闻资讯网站则不可。花了很长的时间去找问题,终于在不经意间,发明网易的博客节点的分列顺序与此外纷歧样,link,language等节点排在image节点上面的,而csdn则是在image的下面(如图),措施在理会时,先理会channel下的节点,写入到channel中,读取到image,则标志理会channel的变量为false,然后开始理会image节点下的内容。理会完毕今后,又要去理会channel节点下的link时,channel标志已经为false了,不能再继承理会,所以老是返回null。
#p#分页标题#e#
修改方案也很简朴,就是所有标志理会channel为false的节点,在理会完毕该节点后,从头标志理会channel为true,这样就可以继承理会channel节点下的其他值 。详细修改操纵:查察org.gnu.stealthp.rsslib包的RSSHandler类的startElement()要领,看看谁执行了 reading_chan = false; 这句代码。然后在endElement()要领中,从头配置 reading_chan = true; 即可:
/**
* Receive notification of the end of an element
* @param uri The Namespace URI, or the empty string if the element has no Namespace URI or if Namespace processing is not being performed.
* @param localName The local name (without prefix), or the empty string if Namespace processing is not being performed
* @param qName The qualified name (with prefix), or the empty string if qualified names are not available
*/
public void endElement(String uri,
String localName,
String qName){String data = buff.toString().trim();
if (qName.equals(current_tag)){
data = buff.toString().trim();
buff = new StringBuffer();
}if (reading_chan)
processChannel(qName,data);if (reading_item)
processItem(qName,data);if (reading_image)
processImage(qName,data);if (reading_input)
processTextInput(qName,data);if (tagIsEqual(qName,CHANNEL_TAG)){
reading_chan = false;
chan.setSyndicationModule(sy);
}if (tagIsEqual(qName,ITEM_TAG)){
reading_item = false;
//-----------------------------------------
//至此,修改的就差不多了,打开一下org.javali.util.test包的RssNewsFetcher类,修改一下测试列表和要领:
package org.javali.util.test;import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;import org.gnu.stealthp.rsslib.RSSChannel;
import org.gnu.stealthp.rsslib.RSSException;
import org.gnu.stealthp.rsslib.RSSHandler;
import org.gnu.stealthp.rsslib.RSSItem;
import org.gnu.stealthp.rsslib.RSSParser;public class RssNewsFetcher {
/**
* rss订阅列表
*/
private final static String[] rssArr = new String[] {
//"http://news.baidu.com/n?cmd=1&class=civilnews&tn=rss",
"http://xiaoxian100.blog.163.com/rss",
"http://blog.csdn.net/xiaoxian8023/rss/list"
};/**
* 测试理会rss订阅
* @throws IOException
*/
public void testFetchRssNews() throws IOException {
for (int i = 0; i < rssArr.length; i++) {
try {//获取rss订阅地点
URL url = new URL(rssArr[i]);
RSSHandler handler = new RSSHandler();//理会rss
//
已经修改的差不多了,下一步就是做成jar,以供本项目利用。步调很简朴。右键项目,选择“导出”→“Java”→“jar文件”,下一步,把右侧的勾全去掉,然后设定一下jar的生成路径,点击“完成”即可。javadoc生成方法差不多,可以参考这里。
手痒了么?快来试试看吧。虽然,此刻做的myrsslib4j 跟rsslib4j一样,仅仅支持rss名目标博客。下篇博客给各人奉献修悔改的rome——myrome,它很好的支持了rss和atom 2种名目标博客。此阅读器会以myrome来理会在线的订阅信息,敬请等候吧。
加句题外话,为了更好的与各人分享,我在Google Code中上传了myrsslib4j的源代码。项目主页:https://code.google.com/p/myrsslib4j/ 。小我私家本领所限,不免会有瑕疵,接待各人多多指正。

