副标题#e#
从 initialValue 说起
问题的发明源自对 JPA 中 TableGenerator 的测试。测试的情况有这样几个条件:
为利便查询的测试,Employee 表格在初始化时会导入部门记录,这部门记录的主键在初始剧本中手动写好,好比 1、2、3、4。(参看文章所附示例代码中的import_data.sql 文件)。
Employee 实体利用 TableGenerator 主键生成器,initialValue 的值配置为 10。
在单位测试中添加新的 Employee 记录。
Employee 实体类的代码参看清单 1:
清单 1. Employee 实体类
@Entity @Table(name="emp3")
public class Employee3 {
@TableGenerator(name="id_gen",table="id_gen",initialValue=10) @Id
@GeneratedValue(strategy=TABLE,generator="id_gen")
private long id;
private String firstName;
private String lastName;
......
}
@TableGenerator 的设置参数 initialValue 指的是主键生成列的初始值,这在 @TableGenerator 的 API 文档中写得很清楚。此刻 initialValue 值配置为 10, 那么在单位测试顶用 JPA 添加新的 Employee 记录时,新记录的主键会从 11 开始,不会与已有的数据产生斗嘴(参看文章所附示例代码中 src/java/test/sample/case3/OldInitialValue.java)。执行的功效出乎料想,测试报错,说是主键反复。错误信息如清单 2 所示:
清单 2. 主键反复错误信息
11:23:40,220 ERROR SqlExceptionHelper:144 – Duplicate entry ‘1’ for key ‘PRIMARY’
这实在令人狐疑。假如 initialValue 的寄义不是初始值,那还能是什么呢?
问题其实出在措施所用的 JPA 提供者(Hibernate)上面。假如改用其他 JPA 提供者,预计不会呈现上面的问题(未验证)。Hibernate 之所以会呈现这种环境,并非蒙昧,也不是不尊重尺度,而有它自身的原因,这在文章后头会提到。此刻,为了把问题讲清楚, 有须要先谈谈 JPA 主键生成器选型的问题,相识一下 @TableGenerator 在 JPA 中的非凡职位。
JPA 主键生成器选型
JPA 提供了四种主键生成器,参看表 1:

SequenceStyleGenerator
Hibernate 的 SequenceStyleGenerator 答允在不支持 Sequence 工具的数据库中模仿利用 SEQUENCE 主键生成器,这种模仿的 SEQUENCE 主键生成器本质上其实照旧 TABLE 生成器。默认环境下不启用该生成器。详细设置与新 TableGenerator 相似。参考资源中有相关资料。
一般来说,支持 IDENTITY 的数据库,如 MySQL、SQL Server、DB2 等,AUTO 的结果与 IDENTITY 沟通。IDENTITY 主键生成器最大的特点是:在表中插入记录今后主键才会生成。这意味着,实体工具只有在生存到数据库今后,才气获得主键值。用 EntityManager 的 persist 要领来生存实体时必需在数据库中插入记载,这种主键生成机制大大限制了 JPA 提供者优化机能的大概性。在 Hibernate 中通过配置 FlushMode 为 MANUAL,可以将记录的插入延迟到长事务提交时再执行,从而淘汰对数据库的会见频率。实施这种系统机能晋升方案的前提就是不能利用 IDENTITY 主键生成器。
SEQUENCE 主键生成器主要用在 PostgreSQL、Oracle 等自带 Sequence 工具的数据库打点系统中,它每次从数据库 Sequence 工具中取出一段数值分派给新生成的实体工具,实体工具在写入数据库之前就会分派到相应的主键。
上面的阐明中,我们把现实世界中的干系数据库分成了两大类:一是支持 IDENTITY 的数据库,二是支持 SEQUENCE 的数据库。对支持 IDENTITY 的数据库来说,利用 JPA 时变得有点贫苦:出于机能思量,它们在选用主键生成计策时该当制止利用 IDENTITY 和 AUTO,同时,他们不支持 SEQUENCE。看起来,四个主键生成器内里解除了三个,剩下独一的选择就是 TABLE。由此可见,TABLE 主键生成机制在 JPA 中职位非凡。它是在不影响机能环境下,通用性最强的 JPA 主键生成器。
本栏目
#p#副标题#e#
TableGenerator 有新旧之分?
TableGenerator 注解和 TableGenerator 类
这里重复提到的 TableGenerator 有两种,一是 JPA 中的注解,另一个是 Hibernate 中的实现类,阅读时需要留意区别。TableGenerator 注解是 JPA 类型中的注解,用于确定 TABLE 主键生成器的各个参数。Hibernate 中的两个 TableGenerator 类实现了 TABLE 主键生成器的成果,它们是类,不是注解。
JPA 的 @TableGenerator 只是通用的注解,详细的成果要由 JPA 提供者来实现。Hibernate 中实现该注解的类有两个,一是原有的 TableGenerator,类名为 org.hibernate.id.TableGenerator,这是默认的 TableGenerator。二是新 TableGenerator,指的是 org.hibernate.id.enhanced.TableGenerator。当用 Hibernate 来提供 JPA 时,需要通过设置参数指定利用何种 TableGenerator 来提供相应成果。
在 4.1 版本的 Hibernate Reference Manual 关于设置参数的章节中(网址可从参考资源中找到)可以找到如下说明:
#p#分页标题#e#
我们发起所有利用 @GeneratedValue 的新工程都设置 hibernate.id.new_generator_mappings=true 。因为新的生成器越发高效,也更切合 JPA2 的类型。不外,要是已经利用了 table 或 sequence 生成器,新生成器与之不相兼容。
还可以再参考一下 HHH-4884 和 HHH-4690 ,内里有 Hibernate 开拓人员对这些问题的观点。
综合这些资源,可以获得如下结论:
假如不设置 hibernate.id.new_generator_mappings=true,利用 Hibernate 来提供 TableGenerator 时,JPA 中 @TableGenerator 注解的 initialValue 参数是无效的。
Hibernate 开拓人员原本但愿用新 TableGenerator 替换掉原有的 TableGenerator,但这么做会导致已经利用旧 TableGenerator 的 Hibernate 工程在进级 Hibernate 后,新生成的主键值大概会与原有的主键斗嘴,导致不行预料的功效。为保持兼容,Hibernate 默认环境下利用旧 TableGenerator 机制。
没有汗青承担的新 Hibernate 工程都应该利用 hibernate.id.new_generator_mappings=true 设置选项。
此刻回到清单 1 所示的问题,要办理这个问题只需在 persistence.xml 文件中添加如下一行设置即可:
清单 3. 添加新的设置行
<property name="hibernate.id.new_generator_mappings" value="true" />
利用新 TableGenerator 后就可以安心地在 JPA 中利用 initialValue 参数了,不外,这只是新 TableGenerator 的一个长处,我们接下来还可以看看新 TableGenerator 带来的更多用法。
新 TableGenerator 的更多用法
新 TableGenerator 除了实现 JPA TableGenerator 注解的全部成果外,尚有其他 JPA 注解没有包括的成果,其设置参数共有 8 项。新 TableGenerator 的 API 文档具体表明白这 8 项参数的寄义,但很奇怪的是,Hibernate API 文档中给出的是 Java 常量的名字,在实际利用时还需要通过这些常量名找到对应的字符串,很是不利便。用对应字符串替换常量后,可以获得下面的设置参数表:

在描写各个参数的寄义时,表中多次提到了“序列”,在这个内外的意思相当于 sequence,也相当于 segment。这里反应出术语的杂乱,假如在 Hibernate文档中把两个英文单词统一起来,阅读的时候会越发清楚。新 TableGenerator 的 8 个参数可分为两组,前 5 个参数描写的是帮助表的布局,后 3个参数用于设置主键生成算法。
先来看前 5 个参数,下图是本文示例措施用于主键生成的帮助表,把图中的元素和新 TableGenerator 前 4 个设置参数一一对应起来,它们的寄义一目了然。
图 1. 帮助表
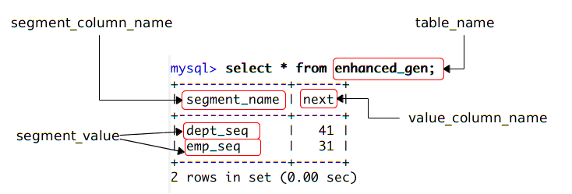
第 5 个参数 segment_value_length 是用来确定序列名称地址列的长度,即序列名所能利用的最大字符数。从这 5 个参数的寄义可以看出,新TableGenerator 支持在同一个表中放下多个主键生成器,从而制止数据库中为生成主键而建设大量的帮助表。
后头 3 个参数用于描写主键生成算法。第 6 个参数指定初始值。第 7 个参数 increment_size 确定了步长。最要害的是第 8 个参数optimizer。optimizer 的默认值一栏写的是“依 increment_size 的取值而定”,到底如何确定呢?
为搞清楚这个问题,需要先来相识一下 Hibernate 自带的 Optimizer。
本栏目
Hibernate 自带的 Optimizer
Optimizer 可以翻译成优化器,利用优化器是为了制止每次生成主键时城市会见数据库。从 Hibernate 官方文档中找不到优化器的说明,需要查阅源码,在 org.hibernate.id.enhanced.OptimizerFactory 类中可以找到这些优化器的名字及对应的实现类,个中优化器的名字就是新TableGenerator 中 optimizer 参数中可以或许利用的值:

Hibernate 自带了 5 种优化器,那么此刻就可以加到上一节提到的问题了:默认环境下,新 TableGenerator 会选择哪个优化器呢?
又一次,在 Hibernate 文档中找不到谜底,照旧要去查阅源码。通过阐明 TableGenerator,可以看到 optimizer的选择计策。详细进程可用下图来描写:
图 2. 选定优化器的进程
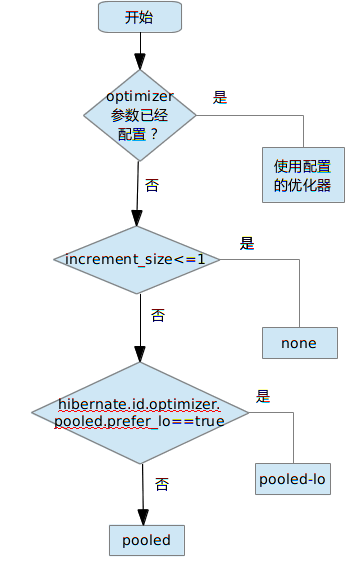
关于 allocationSize
#p#分页标题#e#
JPA 的 @TableGenerator 注解有一个参数 allocationSize,假如用 Hibernate 来提供 JPA,而且开启new_generator_mapping 参数,那么 allocationSize 的值就会是这里的 increment_size。常常可以在网络上看到把allocationSize 配置成 1 的例子,这种行为无异于应用措施的自残。这种环境下还不如利用 AUTO。值得名誉的是 allocationSize的默认值为 50。
可以看出,hilo 和 legacy-hilo 两种优化器,除非指定,一般不会在实践中呈现。接下来很重要的一步就是判定 increment_size 的值,假如increment_size 不做指定,利用默认的1,那么最终选择的优化器会是“none”。选中了“none”也就意味着没有任何优化,每次主键的生成都需要会见数据库。这种环境下 TableGenerator的优势丧失殆尽,假如再用同一张表生成多个实体的主键,结构出来的系统在机能上会是措施员的恶梦。
在 increment_size 值大于 1 的环境下,只有 pooled 和 pooled-lo 两种优化器可供选择,选择条件由布尔型参数hibernate.id.optimizer.pooled.prefer_lo 确定,该参数默认为 false,这也意味着,大大都环境下选中的优化器会是pooled。
我们不去接头 none 和 legacy-hilo,前者不该该利用,后者的名字看上去像是骨董。剩下 hilo、pooled 和 pooled-lo其实是同一种算法,它们的区别在于主键生成帮助表的数值。
本栏目
Optimizer 毕竟在表中记录了什么?
在表 3 中提到 hilo 优化器在帮助表中的数值是 bucket 的序号。这里 bucket可以翻译成“桶”,也可翻译成“块”,其寄义就是一段持续可分派的整数,如:1-10,50-100 等。桶的容量等于 increment_size 的值,假定increment_size 的值为 50,那么桶的序号和每个桶容纳的整数可参看下表:

hilo 优化器把桶的序号放在了数据库帮助表中,pooled-lo 优化器把下一个桶的第一个整数放在数据库帮助表中,而 pooled优化器则把下下桶的第一个整数放在数据库帮助表中。举个例子,假如 increment_size=50, 当前某实体分到的主键编号为60,可以猜测出各个优化器及对应的数据库帮助表中的值。如下表所示:

一般来说,pooled-lo 比 pooled 更切合人的习惯,没有配置 hibernate.id.optimizer.pooled.prefer_lo 为 true时,数据库帮助表的值会出乎人的料想。
措施员看到英文单词“pooled”,会和毗连池这样的观念接洽在一起,这里的池不外是一堆可用于主键分派的整数的“池”,其寄义与毗连池很相似。
新 TableGenerator 实例
关于空洞
不管是 hilo、照旧 pooled、可能 pooled-lo,在利用进程中不行制止地会发生空洞。好比当前主键编号分到第 60,接下来重启了应用措施,Hibernate 无法记着上一次分派的数值,于是 61-100 之间的整数大概永远都不会用于主键的分派。许多人会对此不适应,以为像是丢了什么对象,应用措施也因此不足完美。其实,仔细去阐明,这种感受只能算是人的心理不适,对措施来说,只是需要生成独一而不反复的数值罢了,数据库记录之间的主键编号是否持续基础不影响系统的利用。ORM 措施需要适应这些空洞的存在,计较机的世界里不会因为这些空洞而不足完美。
最后,演示一下 Hibernate 新 TableGenerator 的完整成果。新 TableGenerator 的一些成果不在 JPA 中,因此不能利用 JPA 的 @TableGenerator 注解,而是要利用 Hibernate 自身的 @GenericGenerator 注解。
@GenericGenerator 注解有个 strategy 参数,用来指定主键生成器的名称或类名,类名是容易找到的,不外写起来太不利便了。生成器的名称却不大好找,翻遍 Hibernate 的 manual,devguide,都无法找到这些生成器的名称,最后还得去看源码。可以在 DefaultIdentifierGeneratorFactory 类中找到新 TableGenerator 的名称应该是“enhanced-table”。设置新 TableGenerator 的例子参看清单 4 的代码:
清单 4. 设置新 TableGenerator 的代码
@Entity @Table(name="emp4")
public class Employee4 {
@GenericGenerator( name="id_gen", strategy="enhanced-table",
parameters = {
@Parameter( name = "table_name", value = "enhanced_gen"),
@Parameter( name ="value_column_name", value = "next"),
@Parameter( name = "segment_column_name",value = "segment_name"),
@Parameter( name = "segment_value", value = "emp_seq"),
@Parameter( name = "increment_size", value = "10"),
@Parameter( name = "optimizer",value = "pooled-lo")
})
@Id @GeneratedValue(generator="id_gen")
private long id;
private String firstName; private String lastName;
......
}
竣事语
#p#分页标题#e#
Hibernate 成长到此刻,文档的更新有些落伍于代码的实现,像新 Tablenerator 这样的特性,影响极大,许多措施员都在不清楚这些特性的环境下利用Hibernate,这会给未来的进级带来隐患。Hibernate 官方的文档有待进一步完善,本文但愿可以或许在这里做些补缺的事情。
下载
| 描写 | 名字 | 巨细 |
|---|---|---|
| 代码示例 | demo.tar.gz | 4.91K |
