Apache Hadoop 是用于开拓在漫衍式计较情况中执行的数据处理惩罚应用措施的框架。雷同于在小我私家计较机系统的当地文件系统的数据,在 Hadoop 数据生存在被称为作为Hadoop漫衍式文件系统的漫衍式文件系统。处理惩罚模子是基于“数据局部性”的观念,个中的计较逻辑被发送到包括数据的集群节点(处事器)。这个计较逻辑不外是写在编译的高级语言措施,譬喻 Java. 这样的措施来处理惩罚Hadoop 存储 的 HDFS 数据。
Hadoop是一个开源软件框架。利用Hadoop构建的应用措施都漫衍在集群计较机贸易大型数据集上运行。贸易电脑自制并遍及利用。这些主要是在低本钱计较上实现更大的计较本领很是有用。你造吗? 计较机集群由一组多个处理惩罚单位(存储磁盘+处理惩罚器),其被毗连到互相,并作为一个单一的系统。
Hadoop的组件
下图显示了 Hadoop 生态系统的各类组件
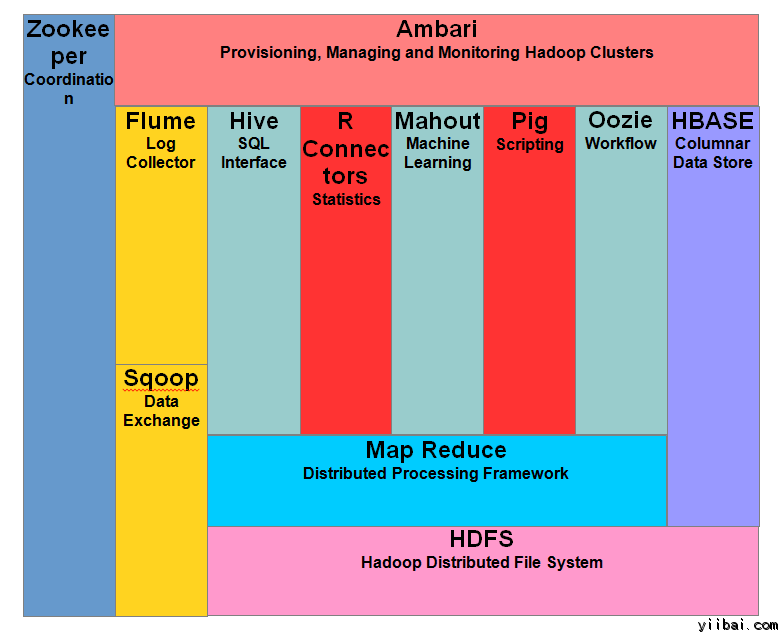
Apache Hadoop 由两个子项目构成 –
-
Hadoop MapReduce : MapReduce 是一种计较模子及软件架构,编写在Hadoop上运行的应用措施。这些MapReduce措施可以或许对大型集群计较节点并行处理惩罚大量的数据。
-
HDFS (Hadoop Distributed File System): HDFS 处理惩罚 Hadoop 应用措施的存储部门。 MapReduce应用利用来自HDFS的数据。 HDFS建设数据块的多个副本,并集群分发它们到计较节点。这种分派使得应用靠得住和极其迅速的计较。
固然 Hadoop 是因为 MapReduce 和漫衍式文件系统 – HDFS 而最着名的, 该术语也是在漫衍式计较和大局限数据处理惩罚的框架下的相关项目。 Apache Hadoop 的其他相关的项目包罗有:Hive, HBase, Mahout, Sqoop , Flume 和 ZooKeeper.
Hadoop 成果
• 合用于大数据阐明
作为大数据在自然界中趋于漫衍和非布局化,Hadoop 集群最适合于大数据的阐明。因为,它处理惩罚逻辑(未实际数据)流向计较节点,更少的网络带宽耗损。这个观念被称为数据区域性观念,它可以辅佐提高基于 Hadoop 应用措施的效率。
• 可扩展性
HADOOP集群通过增加附加群集节点可以容易地扩展到任何水平,并答允大数据的增长。 别的,标度不要求修改到应用措施逻辑。
• 容错
HADOOP生态系统有一个划定,来复制输入数据到其他群集节点。这样一来,在集群某一节点有妨碍的环境下,数据处理惩罚仍然可以继承,通过利用存储另一个群集节点上的数据。
网络拓扑中的Hadoop
网络拓扑布局(机关),当 Hadoop 集群的巨细增长会影响到 Hadoop 集群的机能。除了机能,人们还需要体贴妨碍的高可用性和处理惩罚。为了实现这个Hadoop集群结构,操作了网络拓扑。

凡是环境下,网络带宽是任何网络要思量的一个重要因素。然而,丈量带宽大概是较量坚苦的,在 Hadoop 中,网络被暗示为树,在 Hadoop 集群节点之间树(跳数)的间隔是一个重要因素。在这里,两个节点之间的间隔便是本身最近的民众祖先总间隔。
Hadoop集群包罗数据中心,机架和其实际执行功课的节点。这里,数据中心包罗机架,机架是由节点构成。可用网络带宽历程的变革取决于历程的位置。 也就是说,可用带宽变得更小,因为 –
