MemCache是一个自由、源码开放、高性能、分布式的分布式内存对象缓存系统,用于动态Web应用以减轻数据库的负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站访问的速度。MemCaChe是一个存储键值对的HashMap,在内存中对任意的数据(比如字符串、对象等)所使用的key-value存储,数据可以来自数据库调用、API调用,或者页面渲染的结果。MemCache设计理念就是小而强大,它简单的设计促进了快速部署、易于开发并解决面对大规模的数据缓存的许多难题,而所开放的API使得MemCache能用于java、C/C++/C#、Perl、Python、php、Ruby等大部分流行的程序语言。
另外,说一下MemCache和MemCached的区别:
1、MemCache是项目的名称
2、MemCached是MemCache服务器端可以执行文件的名称
MemCache访问模型
为了加深理解,看下图:
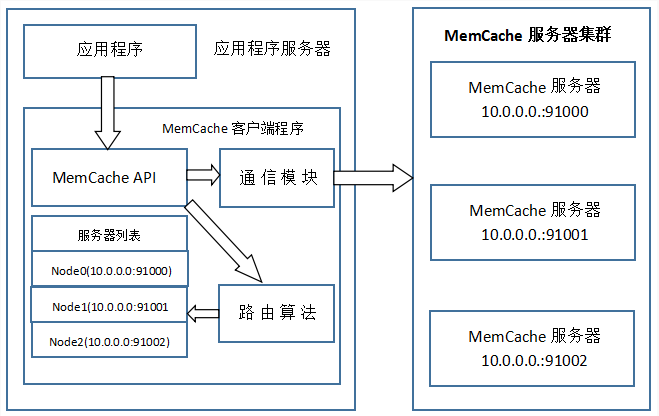
特别澄清一个问题,MemCache虽然被称为”分布式缓存”,但是MemCache本身完全不具备分布式的功能,MemCache集群之间不会相互通信(与之形成对比的,比如JBossCache,某台服务器有缓存数据更新时,会通知集群中其他机器更新缓存或清除缓存数据),所谓的”分布式”,完全依赖于客户端程序的实现,就像上面这张图的流程一样。
同时基于这张图,理一下MemCache一次写缓存的流程:
1、应用程序输入需要写缓存的数据
2、API将Key输入路由算法模块,路由算法根据Key和MemCache集群服务器列表得到一台服务器编号
3、由服务器编号得到MemCache及其的ip地址和端口号
4、API调用通信模块和指定编号的服务器通信,将数据写入该服务器,完成一次分布式缓存的写操作
读缓存和写缓存一样,只要使用相同的路由算法和服务器列表,只要应用程序查询的是相同的Key,MemCache客户端总是访问相同的客户端去读取数据,只要服务器中还缓存着该数据,就能保证缓存命中。
这种MemCache集群的方式也是从分区容错性的方面考虑的,假如Node2宕机了,那么Node2上面存储的数据都不可用了,此时由于集群中Node0和Node1还存在,下一次请求Node2中存储的Key值的时候,肯定是没有命中的,这时先从数据库中拿到要缓存的数据,然后路由算法模块根据Key值在Node0和Node1中选取一个节点,把对应的数据放进去,这样下一次就又可以走缓存了,这种集群的做法很好,但是缺点是成本比较大。
一致性Hash算法
从上面的图中,可以看出一个很重要的问题,就是对服务器集群的管理,路由算法至关重要,就和负载均衡算法一样,路由算法决定着究竟该访问集群中的哪台服务器,先看一个简单的路由算法。
1、余数Hash
比方说,字符串str对应的HashCode是50、服务器的数目是3,取余数得到1,str对应节点Node1,所以路由算法把str路由到Node1服务器上。由于HashCode随机性比较强,所以使用余数Hash路由算法就可以保证缓存数据在整个MemCache服务器集群中有比较均衡的分布。
如果不考虑服务器集群的伸缩性(什么是伸缩性,请参见大型网站架构学习笔记),那么余数Hash算法几乎可以满足绝大多数的缓存路由需求,但是当分布式缓存集群需要扩容的时候,就难办了。
就假设MemCache服务器集群由3台变为4台吧,更改服务器列表,仍然使用余数Hash,50对4的余数是2,对应Node2,但是str原来是存在Node1上的,这就导致了缓存没有命中。如果这么说不够明白,那么不妨举个例子,原来有HashCode为0~19的20个数据,那么:

现在我扩容到4台,加粗标红的表示命中:

#p#分页标题#e#
如果我扩容到20+的台数,只有前三个HashCode对应的Key是命中的,也就是15%。当然这只是个简单例子,现实情况肯定比这个复杂得多,不过足以说明,使用余数Hash的路由算法,在扩容的时候会造成大量的数据无法正确命中(其实不仅仅是无法命中,那些大量的无法命中的数据还在原缓存中在被移除前占据着内存)。这个结果显然是无法接受的,在网站业务中,大部分的业务数据度操作请求上事实上是通过缓存获取的,只有少量读操作会访问数据库,因此数据库的负载能力是以有缓存为前提而设计的。当大部分被缓存了的数据因为服务器扩容而不能正确读取时,这些数据访问的压力就落在了数据库的身上,这将大大超过数据库的负载能力,严重的可能会导致数据库宕机。
这个问题有解决方案,解决步骤为:
(1)在网站访问量低谷,通常是深夜,技术团队加班,扩容、重启服务器
(2)通过模拟请求的方式逐渐预热缓存,使缓存服务器中的数据重新分布
2、一致性Hash算法
一致性Hash算法通过一个叫做一致性Hash环的数据结构实现Key到缓存服务器的Hash映射,看一下一张图:
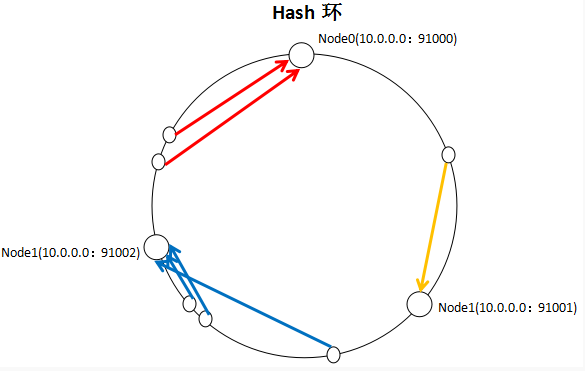
具体算法过程为:先构造一个长度为232的整数环(这个环被称为一致性Hash环),根据节点名称的Hash值(其分布为[0,232-1])将缓存服务器节点放置在这个Hash环上,然后根据需要缓存的数据的Key值计算得到其Hash值(其分布也为[0,232-1]),然后在Hash环上顺时针查找距离这个Key值的Hash值最近的服务器节点,完成Key到服务器的映射查找。
就如同图上所示,三个Node点分别位于Hash环上的三个位置,然后Key值根据其HashCode,在Hash环上有一个固定位置,位置固定下之后,Key就会顺时针去寻找离它最近的一个Node,把数据存储在这个Node的MemCache服务器中。使用Hash环如果加了一个节点会怎么样,看一下:
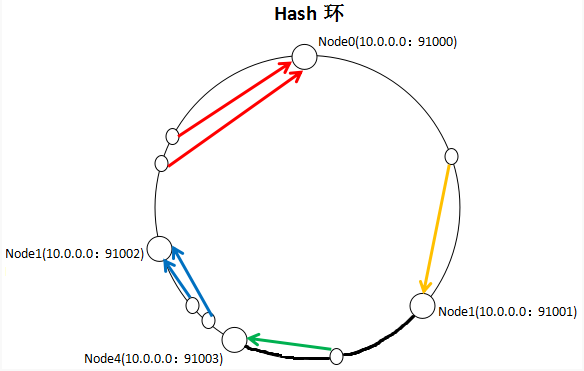
看到我加了一个Node4节点,只影响到了一个Key值的数据,本来这个Key值应该是在Node1服务器上的,现在要去Node4了。采用一致性Hash算法,的确也会影响到整个集群,但是影响的只是加粗的那一段而已,相比余数Hash算法影响了远超一半的影响率,这种影响要小得多。更重要的是,集群中缓存服务器节点越多,增加节点带来的影响越小,很好理解。换句话说,随着集群规模的增大,继续命中原有缓存数据的概率会越来越大,虽然仍然有小部分数据缓存在服务器中不能被读到,但是这个比例足够小,即使访问数据库,也不会对数据库造成致命的负载压力。
至于具体应用,这个长度为232的一致性Hash环通常使用二叉查找树实现,至于二叉查找树,就是算法的问题了,可以自己去查询相关资料。
MemCache实现原理
首先要说明一点,MemCache的数据存放在内存中,存放在内存中个人认为意味着几点:
1、访问数据的速度比传统的关系型数据库要快,因为Oracle、MySQL这些传统的关系型数据库为了保持数据的持久性,数据存放在硬盘中,IO操作速度慢
2、MemCache的数据存放在内存中同时意味着只要MemCache重启了,数据就会消失
3、既然MemCache的数据存放在内存中,那么势必受到机器位数的限制,这个之前的文章写过很多次了,32位机器最多只能使用2GB的内存空间,64位机器可以认为没有上限
然后我们来看一下MemCache的原理,MemCache最重要的莫不是内存分配的内容了,MemCache采用的内存分配方式是固定空间分配,还是一张图说明:
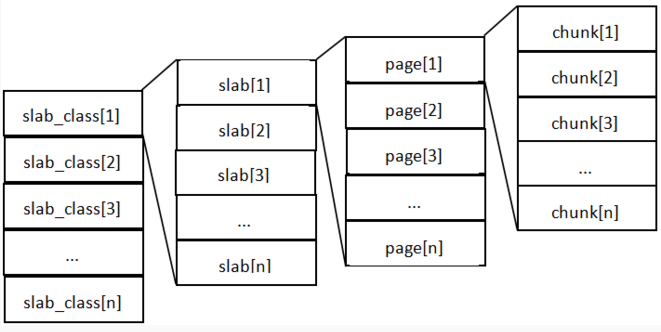
这张图片里面涉及了slab_class、slab、page、chunk四个概念,它们之间的关系是:
1、MemCache将内存空间分为一组slab
2、每个slab下又有若干个page,每个page默认是1M,如果一个slab占用100M内存的话,那么这个slab下应该有100个page
3、每个page里面包含一组chunk,chunk是真正存放数据的地方,同一个slab里面的chunk的大小是固定的
4、有相同大小chunk的slab被组织在一起,称为slab_class
MemCache内存分配的方式称为allocator,slab的数量是有限的,几个、十几个或者几十个,这个和启动参数的配置相关。
#p#分页标题#e#
MemCache中的value过来存放的地方是由value的大小决定的,value总是会被存放到与chunk大小最接近的一个slab中,比如slab[1]的chunk大小为80字节、slab[2]的chunk大小为100字节、slab[3]的chunk大小为128字节(相邻slab内的chunk基本以1.25为比例进行增长,MemCache启动时可以用-f指定这个比例),那么过来一个88字节的value,这个value将被放到2号slab中。放slab的时候,首先slab要申请内存,申请内存是以page为单位的,所以在放入第一个数据的时候,无论大小为多少,都会有1M大小的page被分配给该slab。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk数组,最后从这个chunk数组中选择一个用于存储数据。
如果这个slab中没有chunk可以分配了怎么办,如果MemCache启动没有追加-M(禁止LRU,这种情况下内存不够会报OutOfMemory错误),那么MemCache会把这个slab中最近最少使用的chunk中的数据清理掉,然后放上最新的数据。针对MemCache的内存分配及回收算法,总结三点:
1、MemCache的内存分配chunk里面会有内存浪费,88字节的value分配在128字节(紧接着大的用)的chunk中,就损失了30字节,但是这也避免了管理内存碎片的问题
2、MemCache的LRU算法不是针对全局的,是针对slab的
3、应该可以理解为什么MemCache存放的value大小是限制的,因为一个新数据过来,slab会先以page为单位申请一块内存,申请的内存最多就只有1M,所以value大小自然不能大于1M了
再总结MemCache的特性和限制
上面已经对于MemCache做了一个比较详细的解读,这里再次总结MemCache的限制和特性:
1、MemCache中可以保存的item数据量是没有限制的,只要内存足够
2、MemCache单进程在32位机中最大使用内存为2G,这个之前的文章提了多次了,64位机则没有限制
3、Key最大为250个字节,超过该长度无法存储
4、单个item最大数据是1MB,超过1MB的数据不予存储
5、MemCache服务端是不安全的,比如已知某个MemCache节点,可以直接telnet过去,并通过flush_all让已经存在的键值对立即失效
6、不能够遍历MemCache中所有的item,因为这个操作的速度相对缓慢且会阻塞其他的操作
7、MemCache的高性能源自于两阶段哈希结构:第一阶段在客户端,通过Hash算法根据Key值算出一个节点;第二阶段在服务端,通过一个内部的Hash算法,查找真正的item并返回给客户端。从实现的角度看,MemCache是一个非阻塞的、基于事件的服务器程序
8、MemCache设置添加某一个Key值的时候,传入expiry为0表示这个Key值永久有效,这个Key值也会在30天之后失效。这个失效的时间是memcache源码里面写的,开发者没有办法改变MemCache的Key值失效时间为30天这个限制。
MemCache指令汇总
上面说过,已知MemCache的某个节点,直接telnet过去,就可以使用各种命令操作MemCache了,下面看下MemCache有哪几种命令:

看完以上MemCache的相关内容介绍,那么它有哪些问题呢?下面小编以Memcache存储大数据的问题为例:
Memcached存储单个item最大数据是在1MB内,如果数据超过1M,存取set和get是都是返回false,而且引起性能的问题。
我们之前对排行榜的数据进行缓存,由于排行榜在我们所有sqlselect查询里面占了30%,而且我们排行榜每小时更新一次,所以必须对数据做缓存。为了清除缓存方便,把所有的用户的数据放在同一key中,由于memcached:set的时候没有压缩数据。在测试服测试的时候,没发现问题,当上线的时候,结果发现,在线人数刚刚490人的时候,服务器loadaverage飘到7.9。然后我们去掉缓存,一下子就下降到0.59。
#p#分页标题#e#
所以Memcahce不适合缓存大数据,超过1MB的数据,可以考虑在客户端压缩或拆分到多个key中。大的数据在进行load和uppack到内存的时候需要花很长时间,从而降低服务器的性能。
Memcached支持最大的存储对象为1M。这个值由其内存分配机制决定的。
memcached默认情况下采用了名为SlabAllocator的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached进程本身还慢。SlabAllocator就是为解决该问题而诞生的。SlabAllocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题.
之前(2012-03-16)我们重新测试了memcached::set的数据大小。可能是我们用PHP的memcached扩展是最新版,set数据的时候是默认压缩的。set数据:
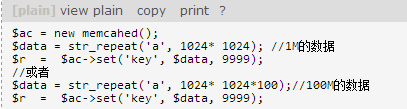
不论是1M的数据还是100M的数据,都能set成功。后来我发现,memcachedset数据的时候是默认压缩的。由于这个这个是重复的字符串,压缩率高达1000倍。因此100M的数据压缩后实际也就100k而已。
当我设置:

也就是说memcachedserver不能存储超过1M的数据,但是经过客户端压缩数据后,只要小于1M的数据都能存储成功。
memcached相关知识:
1、memcached的基本设置
1)启动Memcache的服务器端
#/usr/local/bin/memcached-d-m10-uroot-l192.168.0.200-p12000-c256-P/tmp/memcached.pid
-d选项是启动一个守护进程,
-m是分配给Memcache使用的内存数量,单位是MB,我这里是10MB,
-u是运行Memcache的用户,我这里是root,
-l是监听的服务器IP地址,如果有多个地址的话,我这里指定了服务器的IP地址192.168.0.200,
-p是设置Memcache监听的端口,我这里设置了12000,最好是1024以上的端口,
-c选项是最大运行的并发连接数,默认是1024,我这里设置了256,按照你服务器的负载量来设定,
-P是设置保存Memcache的pid文件,我这里是保存在/tmp/memcached.pid,
2)如果要结束Memcache进程,执行:
#kill`cat/tmp/memcached.pid`
哈希算法将任意长度的二进制值映射为固定长度的较小二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该
段落的一个字母,随后的哈希都将产生不同的值。要找到散列为同一个值的两个不同的输入,在计算上是不可能的。
2、适用memcached的业务场景?
1)如果网站包含了访问量很大的动态网页,因而数据库的负载将会很高。由于大部分数据库请求都是读操作,那么memcached可以显著地减小数据库负载。
2)如果数据库服务器的负载比较低但CPU使用率很高,这时可以缓存计算好的结果(computedobjects)和渲染后的网页模板(enderredtemplates)。
3)利用memcached可以缓存session数据、临时数据以减少对他们的数据库写操作。
4)缓存一些很小但是被频繁访问的文件。
5)缓存Web'services'(非IBM宣扬的WebServices,译者注)或RSSfeeds的结果.。
3、不适用memcached的业务场景?
1)缓存对象的大小大于1MB
Memcached本身就不是为了处理庞大的多媒体(largemedia)和巨大的二进制块(streaminghugeblobs)而设计的。
2)key的长度大于250字符
3)虚拟主机不让运行memcached服务
#p#分页标题#e#
如果应用本身托管在低端的虚拟私有服务器上,像vmware,xen这类虚拟化技术并不适合运行memcached。Memcached需要接管和控制大块的内存,如果memcached管理的内存被OS或hypervisor交换出去,memcached的性能将大打折扣。
4)应用运行在不安全的环境中
Memcached为提供任何安全策略,仅仅通过telnet就可以访问到memcached。如果应用运行在共享的系统上,需要着重考虑安全问题。
5)业务本身需要的是持久化数据或者说需要的应该是database
4、不能能够遍历memcached中所有的item
这个操作的速度相对缓慢且阻塞其他的操作(这里的缓慢时相比memcached其他的命令)。memcached所有非调试(non-debug)命令,例如add,set,get,fulsh等无论
memcached中存储了多少数据,它们的执行都只消耗常量时间。任何遍历所有item的命令执行所消耗的时间,将随着memcached中数据量的增加而增加。当其他命令因为等待(遍历所有item的命令执行完毕)而不能得到执行,因而阻塞将发生。
5、memcached能接受的key的最大长度是250个字符
memcached能接受的key的最大长度是250个字符。需要注意的是,250是memcached服务器端内部的限制。如果使用的Memcached客户端支持”key的前缀”或类似特性,那么key(前缀+原始key)的最大长度是可以超过250个字符的。推荐使用较短的key,这样可以节省内存和带宽。
6、单个item的大小被限制在1Mbyte之内
因为内存分配器的算法就是这样的。
详细的回答:
1)Memcached的内存存储引擎,使用slabs来管理内存。内存被分成大小不等的slabschunks(先分成大小相等的slabs,然后每个slab被分成大小相等chunks,不同slab的chunk大小是不相等的)。chunk的大小依次从一个最小数开始,按某个因子增长,直到达到最大的可能值。如果最小值为400B,最大值是1MB,因子是1.20,各个slab的chunk的大小依次是:
slab1-400B;slab2-480B;slab3-576B…slab中chunk越大,它和前面的slab之间的间隙就越大。因此,最大值越大,内存利用率越低。Memcached必须为每个slab预先分配内存,因此如果设置了较小的因子和较大的最大值,会需要为Memcached提供更多的内存。
2)不要尝试向memcached中存取很大的数据,例如把巨大的网页放到mencached中。因为将大数据load和unpack到内存中需要花费很长的时间,从而导致系统的性能反而不好。如果确实需要存储大于1MB的数据,可以修改slabs.c:POWER_BLOCK的值,然后重新编译memcached;或者使用低效的malloc/free。另外,可以使用数据库、MogileFS等方案代替Memcached系统。
7、memcached的内存分配器是如何工作的?为什么不适用malloc/free!?为何要使用slabs?
实际上,这是一个编译时选项。默认会使用内部的slab分配器,而且确实应该使用内建的slab分配器。最早的时候,memcached只使用malloc/free来管理内存。然而,这种方式不能与OS的内存管理以前很好地工作。反复地malloc/free造成了内存碎片,OS最终花费大量的时间去查找连续的内存块来满足malloc的请求,而不是运行memcached进程。slab分配器就是为了解决这个问题而生的。内存被分配并划分成chunks,一直被重复使用。因为内存被划分成大小不等的slabs,如果item的大小与被选择存放它的slab不是很合适的话,就会浪费一些内存。
8、memcached对item的过期时间有什么限制?
item对象的过期时间最长可以达到30天。memcached把传入的过期时间(时间段)解释成时间点后,一旦到了这个时间点,memcached就把item置为失效状态,这是一个简单但obscure的机制。
9、什么是二进制协议,是否需要关注?
二进制协议尝试为端提供一个更有效的、可靠的协议,减少客户端/服务器端因处理协议而产生的CPU时间。根据Facebook的测试,解析ASCII协议是memcached中消耗CPU时间最多的环节。
10、memcached的内存分配器是如何工作的?为什么不适用malloc/free!?为何要使用slabs?
实际上,这是一个编译时选项。默认会使用内部的slab分配器,而且确实应该使用内建的slab分配器。最早的时候,memcached只使用malloc/free来管理内存。然而,这种方式不能与OS的内存管理以前很好地工作。反复地malloc/free造成了内存碎片,OS最终花费大量的时间去查找连续的内存块来满足malloc的请求,而不是运行memcached进程。slab分配器就是为了解决这个问题而生的。内存被分配并划分成chunks,一直被重复使用。因为内存被划分成大小不等的slabs,如果item的大小与被选择存放它的slab不是很合适的话,就会浪费一些内存。
11、memcached是原子的吗?
#p#分页标题#e#
所有的被发送到memcached的单个命令是完全原子的。如果您针对同一份数据同时发送了一个set命令和一个get命令,它们不会影响对方。它们将被串行化、先后执行。即使在多线程模式,所有的命令都是原子的。然是,命令序列不是原子的。如果首先通过get命令获取了一个item,修改了它,然后再把它set回memcached,系统不保证这个item没有被其他进程(process,未必是操作系统中的进程)操作过。memcached1.2.5以及更高版本,提供了gets和cas命令,它们可以解决上面的问题。如果使用gets命令查询某个key的item,memcached会返回该item当前值的唯一标识。如果客户端程序覆写了这个item并想把它写回到memcached中,可以通过cas命令把那个唯一标识一起发送给memcached。如果该item存放在memcached中的唯一标识与您提供的一致,写操作将会成功。如果另一个进程在这期间也修改了这个item,那么该item存放在memcached中的唯一标识将会改变,写操作就会失败。
小编结语:
更多内容尽在课课家教育!
