CSC 485H/2501H: Computational Linguistics
Assignment 1
计算语言学代写 Late assignments will not be accepted without a valid medical certificate or other documentation of an emergency.This assignment is worth 33%
Late assignments will not be accepted without a valid medical certificate or other documentation of an emergency.
This assignment is worth 33% (CSC 485) or 25% (CSC 2501) of your final grade.
- Read the whole assignment carefully.
- Type the written parts of your submission in no less than 12pt font.
- What you turn in must be your own work. You may not work with anyone else on any of the problems in this assignment. If you needassistance, contact the instructor or the TA for the assignment.
- Any clarifications to the problems will be posted on the Piazza forum for the class. You will be responsible for taking into account in your solutions any information that is posted there, or discussed in class, soyou should check the forum regularly between now and the due date.
- The starter code directory for this assignment is accessible on Teaching Labs machines at the path /u/csc485h/fall/pub/a1/. In this handout, code files we refer to are located in that directory.
- When implementing code, make sure to read the docstrings carefully as they provide important instructions and implementation details.
- Fill in your name, student number, and UTORid on the relevant lines at the top of each Python file that you submit. (Do not add new lines; just replace the NAME, NUMBER, and UTORid placeholders.)
1.Transition-based dependency parsing (42 marks) 计算语言学代写
Dependency grammars posit relationships between “head” words and their modifiers. These relationships constitute trees where each word depends on exactly one parent: either another word or, for the head of the sentence, a dummy symbol, “ROOT”. The first part of this assignment concerns a parser that builds a parse incrementally. At each step, the state of the parse is represented by:
- A stack of words that are currently being processed.
- A buffer of words yet to be processed.
- A list of dependencies predicted by the parser.
Initially, the stack only contains ROOT, the dependencies list is empty, and the buffer contains all words of the sentence in order. At each step, the parser advances by applying a transition to the parse until its buffer is empty and the stack is of size 1.
The following transitions can be applied: 计算语言学代写
- SHIFT: removes the first word from the buffer and pushes it onto the stack.
- LEFT-ARC: marks the second-from-top item (i.e., second-most recently added word) on the stack as a dependant of the first item and removes the second item from the stack.
- RIGHT-ARC: marks the top item (i.e., most recently added word) on the stack as a dependant of the second item and removes the first item from the stack.
a (4 marks)
Complete the sequence of transitions needed for parsing the sentence “To ask those questions is to answer them” with the dependency tree shown below. At each step, indicate the state of the stack and the buffer, as well as which transition to apply at this step, including what, if any, new dependency to add. The first four steps are provided to get you started.
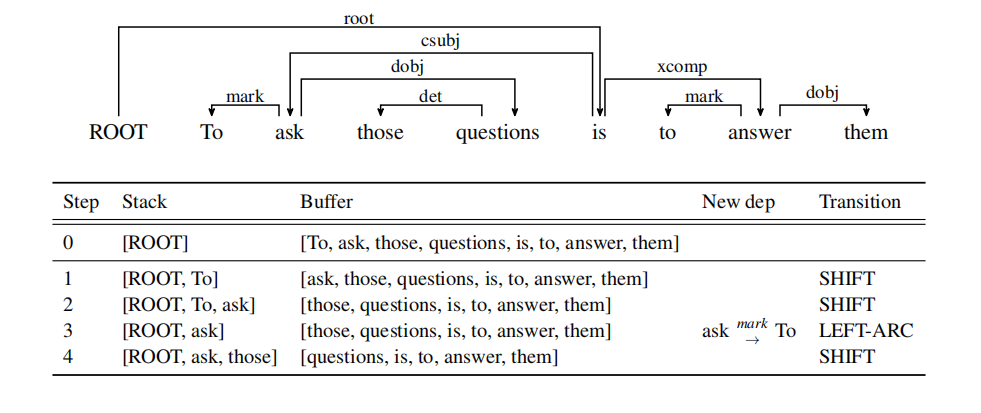

(b) (1 mark)
A sentence containing n words will be parsed in how many steps, in terms of n? (Exact, not asymptotic.) Briefly explain why.
Next, you will implement a transition-based dependency parser that uses a neural network as a classifier to decide which transition to apply at a given partial parse state. A partial parse state is collectively defined by a sentence buffer as above, a stack as above with any number of items on it, and a set of correct dependency arcs for the sentence.
(c) (6 marks) 计算语言学代写
Implement the complete and parse_step methods in the PartialParse class in parse.py. These implement the transition mechanism of the parser. Also implement get_n_rightmost_deps and get_n_leftmost_deps. You can run basic (non-exhaustive) tests by running python3 test_parse.py.
(d) (6 marks)
Our network will predict which transition should be applied next to a partial parse. In principle, we could use the network to parse a single sentence simply by applying predicted transitions until the parse is complete. However, neural networks run much more efficiently when making predictions about “minibatches” of data at a time; in this case, that means predicting the next transition for many different partial parses simultaneously. We can parse sentences in minibatches according to algorithm 1.
Implement this algorithm in the minibatch_parse function in parse.py. You can run basic (non-exhaustive) tests by running python3 test_parse.py.
Training your model to predict the right transitions will require you to have a notion of how well it performs on each training example. 计算语言学代写
The parser’s ability to produce a good dependency tree for a sentence is measured using an attachment score. This is the percentage of words in the sentence that are assigned as a dependant of the correct head. The unlabelled attachment score (UAS) considers only this, while the labelled attachment score (LAS) considers the label on the dependency relation as well. While this is ultimately the score we want to maximize, it is difficult to use this score to improve our model on a continuing basis.
Instead, we will use the model’s per-transition accuracy (per partial parse) as a proxy for the parser’s attachment score, so we will need the correct transitions. But the data set just provides sentences and corresponding dependency arcs. You must therefore implement an oracle that, given a partial parse and a set of correct, final target dependency arcs, provides the next transition to take to advance the partial parse towards the final solution set of dependencies. The classifier will later be trained to try to predict the correct transition by minimizing the error in its predictions versus the transitions provided by the oracle.
(e) (12 marks) 计算语言学代写
Implement your oracle in the get_oracle method of parse.py. You can run basic tests by running python3 test_parse.py.
The last step is to construct and train a neural network to predict which transition should be applied next, given the state of the stack, buffer, and dependencies. First, the model extracts a feature vector representing the current state. The function that extracts the features that we will use has been implemented for you in data.py. This feature vector consists of a list of tokens (e.g., the last word in the stack, first word in the buffer, dependant of the second-to-last word in the stack if there is one, etc.).
They can be represented as a list of integers:
[w1,w2,…,wm]
where m is the number of features and each 0 ≤ wi < |V| is the index of a token in the vocabulary (|V| is the vocabulary size). Using pre-trained word embeddings (i.e., word vectors), our network will first look up the embedding for each word and concatenate them into a single input vector:

(f) (13 marks)
In model.py, implement the neural network classifier governing the dependency parser by filling in the appropriate sections; they are marked by BEGIN and END comments.
You will train and evaluate the model on a corpus of English Web text that has been annotated with Universal Dependencies. Run python3 train.py to train your model and compute predictions on the test data. With everything correctly implemented, you should be able to get an LAS of around 80% on both the validation and test sets (with the best-performing model out of all of the peochs at the end of training).
2.Graph-based dependency parsing (58 marks) 计算语言学代写
The transition-based mechanism above is limited to only being able to parse projective dependency trees. A projective dependency tree is one in which the edges can be drawn above the words without crossing other edges when the words, preceded by ROOT, are arranged in linear order. Equivalently, every word forms a contiguous substring of the sentence when taken together with its descendants. The tree in the above figure was projective. The tree below is not projective.

(a) (3 marks)
Why is the transition-based parser above insufficient to generate non-projective dependency trees?
(b) (8 marks)
Implement the is_projective function in graphalg.py. You can run some basic tests based on the trees in the handout by running python3 graphalg.py. Run the count_projective.py script and report the result.
(c) (4 marks)
A related concept to projectivity is gap degree. The gap degree of a word in a dependency tree is the least k for which the subsequence consisting of the word and its descendants (both direct and indirect) is entirely comprised of k +1 maximally contiguous substrings. Equivalently, the gap degree of a word is the number of gaps in the subsequence formed by the word and all of its descendants, regardless of the size of the gaps. The gap degree of a dependency tree is the greatest gap degree of any word in the tree.
What are the gap degrees of the tree above and the tree on page 2? Show your work. 计算语言学代写
Unlike the transition-based parser above, in this part of the assignment you will be implementing a graph-based parser that doesn’t have the same limitation for non-projective trees. In particular, you will be implementing an edge-factored parser, which learns to score possible edges such that the correct edges should receive higher scores than incorrect edges. A sentence containing n words has a dependency graph with n+1 vertices (with the one extra vertex being for ROOT); there are therefore (n+1)2 possible edges.
In this assignment, the vertices for the sentence words (including ROOT) will each be represented as vectors of size p. The vertices for the entire sentence can then be represented as a matrix S ∈ R(n+1)×p.1 Assume that ROOT is placed before the first word in the sentence.
1 Be aware that the vectors are computed differently compared to Part 1. There, we used word2vec; here we use BERT, a contextual representation model that provides a vector representation for each word-token in the context of a sentence; in other words, the same word-type will have different vector representations depending on the sentence it appears in.
The model you are to implement has two components: an arc scorer and a label scorer. 计算语言学代写
The arc scorer produces a single score for each vertex pair; the label scorer produces |R| scores for each vertex pair, where R is the set of dependency relations (det, dobj, etc.). The arc scores are used to select edges into an unlabelled dependency tree, after which the label scores can be used to select dependency relations for their edges.
Let aij denote the arc score for the candidate dependency edge from vertex j to vertex i. Note the ordering! It may be different from what you’re used to: aij is the score corresponding to j being the head of i. Then the matrix A with elements aij = [A]ij is defined as:
DA = MLPAd(S)
HA = MLPAh(S)
aij = [DA]iWA([HA]j)T +[HA]j · bA
MLPa,d and MLPa,h are (separate) Multi-Layer Perceptron layers that transform the original input sentence matrix S to a smaller dimensionality dA < p. For this assignment, we will be using MLPs with one hidden layer and one output layer, both of width dA, along with Rectified Linear Unit (ReLU) activation and dropout for each layer. WA and bA are trainable parameters.
Lastly, for each word i in the sentence, we can compute the probability of word j being its head with softmax and then use cross-entropy as the loss function Jh for training:
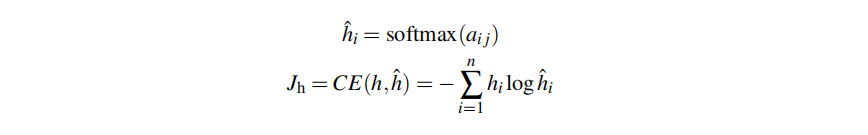
(d) (6 marks)
Implement create_arc_layers and score_arcs in graphdep.py. You will need to determine the appropriate dimensions for WA and bA, as well as how to implement the arc score calculations for the batched sentence tensors. You should be able to do this entirely with PyTorch tensor operations; using a loop for this question will result in a penalty.
(e) (1 mark)
For effective, stable training, especially for deeper networks, it is important to initialize weight matrices carefully. A standard initialization strategies for ReLU layers is called He initialization. For a given layer’s weight matrix W of dimension m × n, where m is the number of input units to the layer and n is the number of units in the layer, He initialization samples values Wi j from a Gaussian distribution with mean µ = 0 and variance σ2 = 2/m.
However, it is common to instead sample from a uniform distribution U (a,b) with lower bound a and upper bound b; in fact, the create_* methods in graphdep.py direct you to initialize some parameters according to a uniform distribution. Derive the values of a and b that yield a uniform distribution U (a,b) with the mean and variance given above.
The label scorer proceeds in a similar manner, but is a bit more complex. 计算语言学代写
Let lij ∈ R|R| denote a vector of scores, one for each possible dependency relation r ∈ R. We use similar MLPs as for the arc scorer (but with different dimensionality), and then compute the score vector as:
DL = MLPLd(S)
HL = MLPLh(S)
lij = [DL]iWL([HL]j)T +[HL]jWLh +[DL]jWLd +bL
WL is a third-order tensor, WLh and WLd are matrices, and bL is a vector so that lij is a vector as defined above. The MLPs for the label scorer have the same structure as for the arc scorer (two hidden layers, ReLU activations and dropout for each), but we use a smaller dimensionality dL < dA < p.

(f) (8 marks) 计算语言学代写
Implement create_label_layers and score_labels in graphdep.py. As above, you will need to determine the appropriate dimensions for the trainable parameters and how to implement the label score calculations for the batched sentence tensors. You should be able to do this entirely with PyTorch tensor operations; using a loop for this question will result in a penalty.
(g) (2 marks)
In the arc scorer, the score function includes a term that has HA but not DA, but there isn’t a term that has the opposite inclusions (DA but not HA). For the label scorer, both are included. Why does it not make sense to include a term just for DA, but it does for DL?
(h) (2 marks)
In standard classification problems, we typically multiply the input by a weight matrix and add a per-class bias to produce a class score for the given input. Why do we have to multiply WA and WL by (transformed versions of) the input twice in this case?
(i) (2 marks) 计算语言学代写
There are some constraints on which edges and edge-label combinations are possible. Implement these constraints in mask_possible in graphdep.py.
Finally, how do we make our final predictions given an input sentence? Since we know that our desired answer has a tree structure, and since the parsing model is trained to increase the scores assigned to the correct edges, we can use a maximum spanning tree algorithm to select the set of arcs. Then, for each arc from i to j, we can use argmax over lij to predict the dependency relation.
(j) (4 marks)
Why do we need to use a maximum spanning tree algorithm to make the final arc prediction? Why can’t we just use argmax, as we would in a typical classification scenario (and as we do for the dependency relations)? What happens if we use argmax instead?
(k) (12 marks) 计算语言学代写
Finish the rest of the implementation: is_single_root_tree and single_ root_mst in graphalg.py. You can refer to the pseudocode for the Chu-Liu-Edmonds algorithm in Figure 14.13 in the dependency parsing chapter of Jurafsky & Martin, 3rd edition textbook to guide your implementation.
As in part 1, you will train and evaluate the model on a corpus of English Web text that has been annotated with Universal Dependencies. Run python3 train.py to train your model and compute predictions on the test data. With everything correctly implemented, you should be able to get an LAS of around 82% on both the validation and test sets (with the best-performing model out of all of the peochs at the end of training).2
2 Because the two parsers use different word vectors, however, their LAS values are not directly comparable.
(l) (6 marks)
Find at least three example sentences where the transition-based parser gives a different parse than the graph-based parser, but both parses are wrong as judged by the annotation in the corpus. For each example, argue for which of the two parses you prefer.
Notes 计算语言学代写
-
While debugging,
you may find it useful to run your training code with the –debug flag, like so:
$ python3 train.py --debug
This will cause the code to run over a small subset of the data so that each training epoch takes less time. Remember to change the setting back prior to submission, and before doing your final run.
-
Training should run within 1–5 hours on a CPU,
but may be a bit faster or slower depending on the specific CPU. A GPU is much faster, taking around 5–10 minutes or less—again, with some variation depending on the specific GPU.
-
You can run your model on a GPU-equipped machine in theteach.cs.toronto.edu network. 计算语言学代写
The starter code directory includes a gpu-train.sh script that will run the relevant command to run your train.py file, assuming the latter is in your current working directory (i.e., assuming that you run your the command while your shell was in the same directory as train.py). Note that the GPU machines are shared resources, so there may be limits on how long your code is allowed to run.
The gpu-train.sh script should be sufficient; it takes care of submitting and running the job to the cluster-management software. If you like, you are free to manage this yourself; see the documentation online at the relevant page on the Teaching Labs site. The partition you can use for this class is csc485.
If you wish to visit the labs in person, the Teaching Labs FAQ page lists the labs that have GPU-equipped machines.
-
Keep in mind that your mark is based on your implementation, 计算语言学代写
not (directly) on the LAS that your implementation achieves. Getting an 82% LAS does not guarantee full marks, nor does getting a lower LASguarantee that marks will be deducted. The end result can vary based on differences in environment, hardware or software, so this number isapproximate. Nevertheless, the further away your LAS, the more likely it is that you have an error in your implementation.
-
Except for is_single_root_tree and single_root_mst,
make sure that all of your changes occur within BEGIN and END boundary comments. Do not add any extra package or module imports and do not modify any other parts of the files other than to fill in your personal details at the top of the file.
You may alter other parts of the code as needed for debugging, but make sure that you revert any such changes for your final run and submission.
-
You will be better off with partially complete implementations that work but are sometimes incorrect than you will with an almost-complete implementation that Python cannot run.
Keep this in mind for your final submission. Also, make sure your submitted files are importable in Python (i.e., make sure that ‘import graphalg’ and ‘import graphdep’ do not yield errors).
What to submit 计算语言学代写
Submission is electronic and can be done from any Teaching Labs machine using the submit command:
$ submit -c <course> -a A1 <filename-1> ... <filename-n>
where <course> is csc485h or csc2501h depending on which course you have registered in, and <filename-1> to <filename-n> are the n files you are submitting. The files you are to submit are as follows:
- a1written.pdf: a PDF document containing your written answers as applicable for each question.
This PDF must also include a typed copy of the Student Conduct declaration as on the last page of this assignment handout.
Type the declaration as it is and sign it by typing your name. 计算语言学代写
- model.py: the (entire) model.py file with your implementations filled in.
- parse.py: the (entire) parse.py file with your implementations filled in.
- graphalg.py: the (entire) graphalg.py file with your implementations filled in.
- graphdep.py: the (entire) graphdep.py file with your implementationsfilled in.
- weights-q1.pt and weights-q2.pt: the weights file produced by your models’ final runs.
Again, except for is_single_root_tree and single_root_mst, ensure that there are no changes outside the BEGIN and END boundary comments provided other than filling in your details at the top of the file; you will lose marks if there are. Do not change or remove the boundary comments either.
Appendix A PyTorch 计算语言学代写
You will be using PyTorch to implement components of your neural dependency parser. PyTorch is an open-source library for numerical computation that provides automatic differentiation, making the back-propagation aspect of neural networks easier. Computation is done in units of tensors; the storage of and operations on tensors is provided in both CPU and GPU implementations, making it simple to switch between the two.
We recommend trying some of the tutorials on the official PyTorch site to get up to speed on PyTorch’s mechanics. In particular, the Tensors and nn module sections of the Learning PyTorch with Examples tutorial will be most relevant for this assignment.
If you want to run this code on your own machine, you can install the torch package via pip3, or any of the other installation options available on the PyTorch site. Make sure to use PyTorch version 1.9. You will also need to install the conllu and transformers packages.
Make sure to consult the PyTorch documentation as needed. The API documentation for torch, torch.nn, torch.nn.functional, and torch.Tensor will be useful while implementing the code in this assignment.

更多代写:C 温哥华代考 pte代考 英国微积分代考 presentation代写 英文report代写 代写reference
