CMDA 3634 Fall 2019 HW 11
HW代写 An example of a completed MPI-based cluster-centroid project is available in the class repository at code.vt.edu/tcew/cmda3634
An example of a completed MPI-based cluster-centroid project is available in the class repository at code.vt.edu/tcew/cmda3634, which you can pull with Git. The example project is in the HW10/ directory. If your code from Task 2 of HW 10 did not work, you can use the example in this assignment. Even if your code did work, you might want to take a look at the provided code, including the makefile.
Task 1 HW代写
Perform a compiler optimization study on your MPI-based cluster-centroid program from HW 10.
Q1.1 (5pts) Use the MPI wall time function MPI Wtime in your MPI-based cluster-centroid code to measure and print the amount of time that it takes to complete the centroid calculation (excluding FILE input/output operations). Compile your project without special compiler options and run your program with one process and mpiClusters.dat as input. Record the runtime.HW代写
Q1.2 (5pts) Recompile the project with each of the different compiler optimization flags demonstrated in class (-O1, -O2, and -O3).
Run each program with one process and mpiClusters.dat as input. Record the runtime for the program produced by each compiler optimization. For each optimization, compute the speedup ratio compared to the un-optimized program. Use the timings for your test cases to make a completed version of Table 1, which is like Table 23.1 in the lecture notes.
| Optimization | Compiler | Runtime (seconds) | Speedup |
| None | mpicc | 1 | |
| -O1 | mpicc | HW代写 | |
| -O2 | mpicc | ||
| -O3 | mpicc |
Table 1: An incomplete optimization study table. Runtimes need to be measured and speedup ratios need to be calculated calculated.
Q1.3 (5 points extra credit)Repeat Q1.2 using the Intel icpc compiler (available on Cas- cades) instead of the GNU compilers. Remember to use module purge and load the Intel compiler module before loading a MPI module. You will need to load the correctmodule on the compute node, as demonstrated in the profiling and optimization lecture.HW代写
Use the runtimes of the Intel-compiled programs to expand your version of Table 1 with new rows as shown in Table 2.
| .
None |
.
icpc |
. | . |
| -O1 | icpc | ||
| -O2 | icpc | HW代写 | |
| -O3 | icpc |
Table 2: An example continuation of Table 1 for the extra credit Intel compiler optimization study.

Task 2 HW代写
Perform a strong scaling study on the MPI-based cluster-centroid program without compiler optimization.
This task should sound familiar since it is almost the same as the in-class assignment after Lecture 21 on November 6.
Q2.1 (15pts) Use the Cascades cluster to run the un-optimized MPI-based cluster-centroid program with 1, 2, . . . , 28 processes and mpiClusters.dat as input. Record each run- time.HW代写
I previously asked you not to add the large data file HW10/data/mpiClusters.dat to your Git repository, but Git is a convenient way to transfer the data file to Cascades. If you haven’t already, go ahead and commit the data file to your repository and pull it to your directory on Cascades. Remember you’ll need to do this before starting a computing session.HW代写
As a reminder, you can request an interactive session with the command
salloc –partition=dev_q –nodes=1 –tasks-per-node=28 -A cmda3634
Don’t forget to load the right modules with
module purge
module load gcc openmpi HW代写
You should be able to perform all 28 runs with one terminal command. If your compiled executable is called go, the following loop (in the Linux terminal) will run the executable 28 times, once with each number of processes.
for P in `seq 1 28`;
do
mpiexec -n $P ./go data/mpiClusters.dat
done
Of course, the above loop assumes that the data file that you want to analyze is
data/mpiClusters.dat.HW代写
Q2.2 (5pts) For each number of processes, compute the speedup ratio. Use any system you prefer to make a graph of (the number of processes, P ) vs (the speedup ratio, T1/TP ). For reference, include the straight line P = T1/TP You plot should resemble Figure 1.
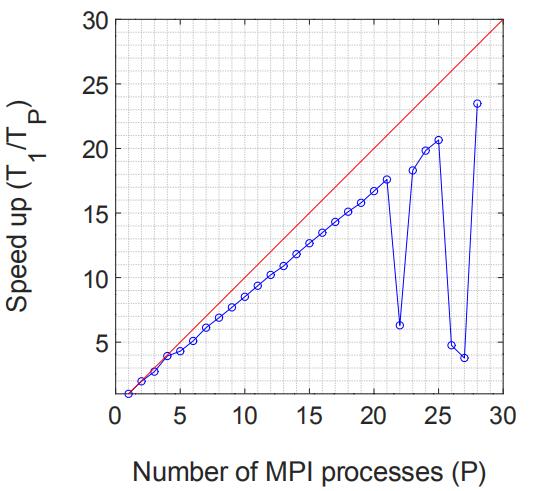
Figure 1: Example of a strong scaling study graph. The red line shows the theoretical perfect speedup rate P = T1/TP .
Q2.3 (5pts extra credit) Repeat the above scaling study three more times but on the program with optimized compilation. Each of the three compiler flags (-O1, -O2, -O3) should be used in one study.
Task 3 HW代写
Modify your k-means project to run in parallel via MPI. If you are not satisfied with your own k-means project, you may use the example k-means project that was provided for HW 9 and the reference code provided for HW10.
Q3.1 (10pts) Parallelize the cluster centroid calculation using MPI. You may use your work from HW 10 or the example solution explained at the top of this assignment.
Q3.2 (15pts) Parallelize the calculation of the nearest cluster centroid assignment using MPI.HW代写
Q3.3 (15pts extra credit) Perform optimization and strong scaling studies on your k-means code. In other words, repeat Tasks 1 and 2 with your k-means code in place of the cluster-centroid code.
While testing your code, you can use any of the data provided for HW 7, 9, or 10.
Submission
Q4.1 (5pts) Submit your work as follows.
- Writea report on your results and use LATEX to typeset
- Your report shouldinclude
- All of the C source files you used, including any that you borrowed from the instructor’s example. In your report, source files should be nicely formatted with the minted
- The table explained in Task
- The graphs explained in Task
- Upload the PDF and tex files of your report to
- Your report shouldinclude
- Submitthe C source files of ALL tasks by pushing them to your Git repository onvt.edu You may not receive any credit if your code is not in your repository. HW代写Please imitate the directory structure in the instructor’s example, shown below.
HW11/
makefile src/
mpiCluster.c data.c
[any other source files] data/mpiClusters.dat
[any other data files] include/data.h
[any other header files]
