Programming Assignment3 Writeup
编程作业代写 I don’t think the architecture in Figure1 will perform good on long sequences.I think encoder only output one final hidden state
Part1:
1. 编程作业代写
I don’tthink the architecture in Figure1 will perform good on long sequences.First of all, I think encoder only output one final hidden state, along with sequences more and more longer, the information can store in hidden state is more and more less.so it will not perform good.
Second, when we decoder, each output from decoder use one common Final hidden state, this is intuitively inappropriate, because for each input on decoder, they rely different proportions of input. Like, ‘cat cash dog’ ,when we translate ‘dog’ ,’cat’ is more important than ‘cash’.
2.
First, we can do something in Final hidden state, We can try not use only Final hidden state, but use all hidden output from Encoder, as we all know ,RNN can Output hidden each time step, we can use this hidden state, when we decoder ,we use same time step’s hidden state as a information give decoder.
Second, we can use Attention techniques improve the performance of this architecture.
3. 编程作业代写
When we train , we feed ground-truth token from previous time step, But when we generated text in test, we don’t know really previous time step ,so we have to use previous time step. This will rise a problem, In testing, we generate text each step is not 100% accurate, and each step the loss will accumulation, So along with sequences more and more long, the output text will more and more Inaccurate.
4.
The problem is when we training model we use ground-truth token, but when we testing, we can only use the token which be generate by step t-1, this make train and test is Inconsistent, so when we train model ,we can flip the coin when we training model, some time we choose the ground-truth token, but sometimes we choose the token generate by step t-1.
Part2:
1.编程作业代写
I don’t thinkqualitatively, because it translate “the air conditioning is working”to “ ethay airday onditionsay isday orday-inway-awlay”, air is wrong, onditionsay is wrong, isday is wrong , working is wrong. I think is more wrong on type vowel .
2.
I try some like ‘money is good love too’-> ‘onecay isway oodgay-ybay overay ootay’, ’tick tick and go back’->’itchingway itchingway andway ogay ackhay’,’dont hurt me please’->’ontway urthay epay easescay’.
3.编程作业代写
I find constant letter always loss itself, it will change itself, like ‘dont‘ should be translate to ‘ontday’,but result is ‘ontway’, letter is change.
Part3:
1.编程作业代写
RNN decode without attention only can achieve 0.982 loss in valid dataset and 0.658 loss in train dataset. But with attention, it can achieve 0.061 loss in valid dataset and 0.009 in valid set.
But the speed of RNN with attention is 1759 seconds, and without attention it will only need 417 seconds.why the model of RNN with attention is so slow? I think,it’s because of in part of attention, have a sub_model named mlp, It spend many time.
I can find some failure model, like:
source: the air conditioning is working
translated: ethay airway ondinctionsway isay orkingway
the ‘conditioning’ is translate to ‘ondinctionsway’, is wrong, and ‘airway’ is wrong.
The model I can identity may be vowel is more wrong, and when sentence is long, they may be wrong.
Part6:
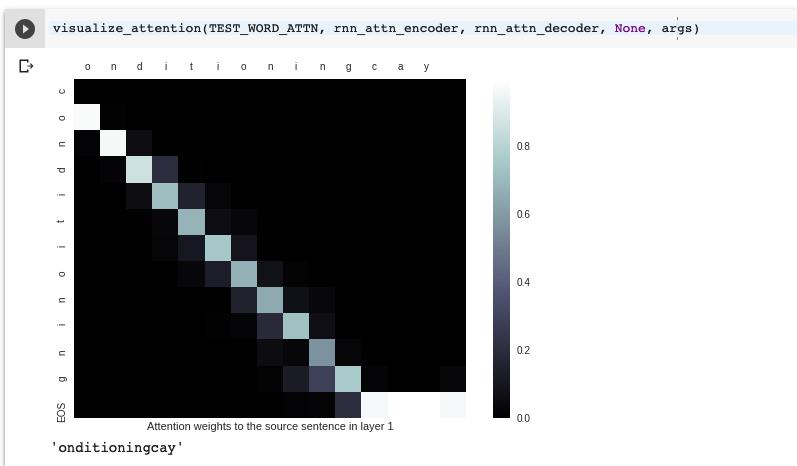
we use conditioning to do test, and we find its ok ,and we can say letter ‘0’s weight is biggest, so I guess generate one text, may first search the first letter in generate text.
And When we translate sentence ‘the air conditioning is working’ ,conditioning is wrong but only one word conditioning is right, other word will give translate some wrong information.
2.编程作业代写
Thespeed of RNN scaled dot-product is more faster than additive attention, but the loss of dot-product is bigger than additive attention. Because the function f(Q,K) in two model is different, additive is more complicate and dot-product attention is simple. So the accuracy of simple model is low, but need less time to train.
Part5:
- the advantage of scaled dot-product is: dot-product is simple and fast.
the disadvantage of scaled dot-product is: the loss of dot-product.
so,
the advantage of additive attention is: high accuracy.
the disadvantage of additive attention is: need too much time.
2. I am feel sad about this result, because the result is very bad.But it’s speed is faster than before model.
3.
When I train this model I find this model can capture no massage in attention, I don’t know why ,It’sperformance is very bad. I think my model is wrong , but I can’t find wrong.编程作业代写
Part6:
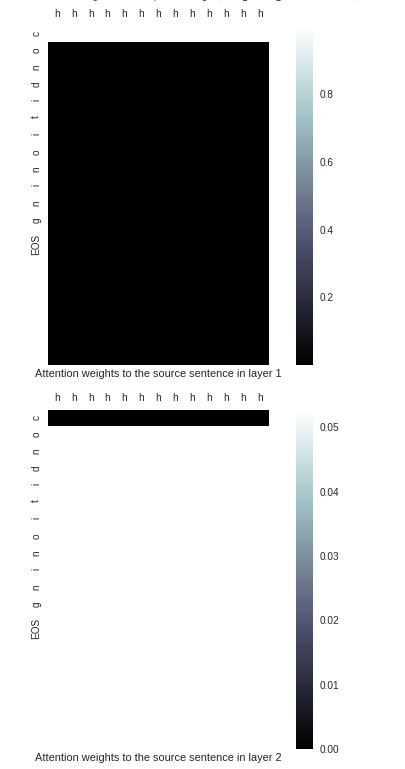
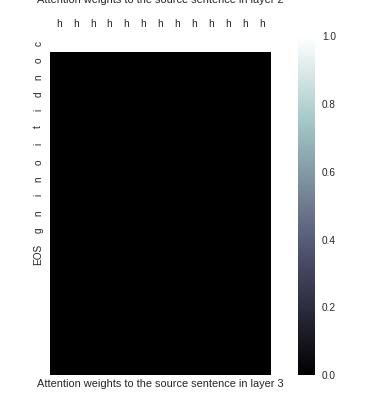
I use Attention Visualization to see the fault, as the picture shown below, I Cant find the massage capture by attention.
I use ‘conditioning’ to test.
4.
first,In our simple model , we just need find the three simple ruler translate, English to Pig-Latin, the ruler is always about first two letter, It’s very simple.
second, model can find position massage by CausalScaledDotAttention
Implicitly ,because first encode is just know itself, so know little thing sometime is a information.
Part6:
I hava use visualize technique in above content for analysis attention performance, both of attention and transform.
In this section, I will use visualize attention to see cake, drink, and aardvark and well-mannered, and made up myself word ‘sfsf’ to test.编程作业代写
For cake,It can perform good, we can see this picture, :
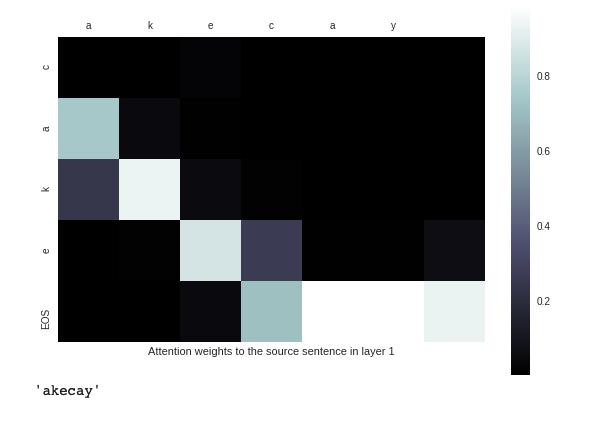
For case ‘aardvark’, the result is:

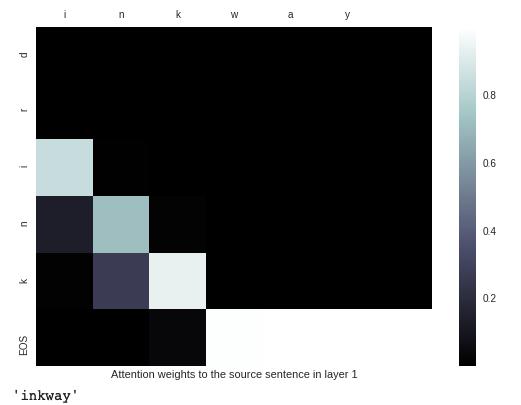
For case ‘drink’ ,the result is:
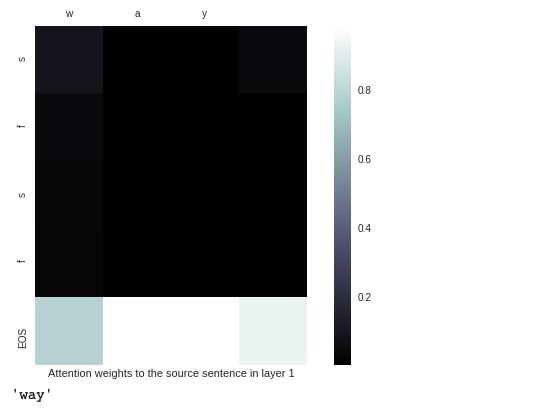
For case ‘sfsf’, the result is:
For case ‘well-mannered’,the result is:


更多其他:r语言代写 code代写 CS代写 cs作业代写 C语言代写 Data Analysis代写 java代写 代写作业 代写加急 代码代写
