
Financial Econometrics and Empirical Finance Fall 2018 HW4
Due: Before November 26, 2018, 8am.
导读:这是一篇关于金融计量作业使用matlab作业代写的案例,它包含了回答问题的代写,
也包含了matlab代码实现,包括完整的报告,这个作为展示部分,并不能完全使用它
因为他的代写作业报告部分是不完整的,因为原创的关系,所有的东西不完全公开展示代写成果。
All assignments must be completed using a software or programming language that allows the manipulation of matrices and vectors. No canned statistical packages are allowed.
To complete this assignment, you will need the dataset countries_daily.mat. The file contains daily stock market indices of 73 developed, emerging, and frontier countries. The indices are in variable “Indx”, their labels are in “label”, and the corresponding dates are in vector “date”.
-
-
-
-
-
- For the rest of the analysis, use the following 5 countries: US, UK, Japan, Hong Kong, and China.
- Compute the daily and monthly log returns for the 5 countries. Make sure you locate them correctly in the
- Forthe following part of the analysis, use only daily log returns for the 5 (a).Compute the average returns for all countries, expressed in annualized
(b).Computethe standard deviation (realized volatility) of returns for all countries, expressed in annualized
(c).Break the sample into decades (eg 70s, 80s, …). For each country and decade, com putestandard deviations (realized volatility) of returns (whenever possible), expressed in annualized percents.
(d).Do the same for every one-year period. Plot the results (all countries in one plot), ex- pressed in annualized
-
-
-
-
-
-
-
- (e).Do the same for every month. Plot the results (all countries in one plot), expressed in annualized.(f).Run thefollowing regressions (one for each country) using the monthly realized volatilities in part
-
-
![]()
where RV i;t is the realized volatility of country i at time t. Report estimates of c i s; Áis;their t-statistics, and R 2 s:
(g).Are the volatilities predictable? Why?
(h). Now, re-compute monthly realized volatilities of every country (as in part (e)) but first exclude the largest 10 daily outliers for each country from the data.
(i).Re-run the same regressions and analysis as in part ( f).
(j).Did your estimates change significantly? Why?
4.For the following part of the analysis, use only monthly log returns for the 5 countries.
(a).Estimate an ARCH for each country. Compute standard errors using the Hessian method.
(b).Plot the ARCH estimates of the monthly volatilities (all countries in one plot), ex- pressed in annualized percents.
(c). Based on the ARCH(1) results, do you conclude that the monthly volatilities are persis- tent?
(d).Estimate a GARCH(1,1) for each country. Compute standard errors using the Hessian method.
(e).Plot the GARCH(1,1) estimates of the monthly volatilities (all countries in one plot), expressed in annualized percents.
(f).Based on the GARCH(1,1) results, do you conclude that the monthly volatilities are persistent?
(g).How do the GARCH(1,1) estimates compare to the ARCH(1) estimates?5.OPTIONAL: Run an asymmetric GARCH(1,1) model for the 5 countries. Do you observe asymmetries in thedata?
6.OPTIONAL: Run the analysis in questions 1-5 for all 73 countries (not only the selected 5). Do the conclusions you reach above hold more generally for the cross section ofcountries?
load('countries_daily.mat');
%% Q1
% Find the col index for countries
% US, UK, Japan, Hong Kong, and China.
country_index = [find(strcmp(label,'US'))
find(strcmp(label,'UNKING'))
find(strcmp(label,'JAP'))
find(strcmp(label,'HONG'))
find(strcmp(label,'CHINA'))];
%Indx for 5 countries
Indx_5 = Indx(:,country_index);
%% Q2
daily_table = fints(date, Indx_5, {'US','UK','JAP','HK','CH'});
daily_log_return = diff(log(daily_table));
%convert daily data to monthly data
monthly_table = tomonthly(daily_table);
monthly_log_return = diff(log(monthly_table));
% print returns in a txt file.
% fts2ascii('monthly_log_return.txt',monthly_log_return);
% fts2ascii('daily_log_return.txt',daily_log_return);
%% Q3
%a.
% convert Inf (due to the logarithm) to NaN
daily_log_return.US(2087) = NaN;
daily_log_return.JAP(2086) = NaN;
daily_log_return.HK(1275) = NaN;
daily_log_return.CH(6848) = NaN;
mean_daily = nanmean(daily_log_return);
% annualized return: 9.4029 11.2655 6.5787 11.9300 11.1869.
(exp(mean_daily * 250) - 1) * 100
%b. annualized RV: 17.0532 19.0475 20.4422 30.4970 38.4871.
rv_daily = nanstd(daily_log_return);
rv_daily * sqrt(250)*100
%c
% extract decades, e.g. 196 is 60s; 201 is 2010s
decades = unique(floor(year(daily_log_return.dates)/10));
ind60 = floor(year(daily_log_return.dates)/10) == 196; % index for 60s, so on
ind70 = floor(year(daily_log_return.dates)/10) == 197;
ind80 = floor(year(daily_log_return.dates)/10) == 198;
ind90 = floor(year(daily_log_return.dates)/10) == 199;
ind00 = floor(year(daily_log_return.dates)/10) == 200;
ind10 = floor(year(daily_log_return.dates)/10) == 201;
[nanstd(daily_log_return(ind60)) * sqrt(250) * 100;
nanstd(daily_log_return(ind70)) * sqrt(250) * 100;
nanstd(daily_log_return(ind80)) * sqrt(250) * 100;
nanstd(daily_log_return(ind90)) * sqrt(250) * 100;
nanstd(daily_log_return(ind00)) * sqrt(250) * 100;
nanstd(daily_log_return(ind10)) * sqrt(250) * 100;]
%Ans: US Uk Jap HK China
% NaN 12.9044 NaN 16.0274 NaN
% 14.3688 20.6744 14.1688 34.2972 NaN
% 16.2006 19.1892 17.2237 33.7533 NaN
% 13.5458 14.4014 23.3901 27.2376 48.1655
% 21.8650 23.0491 23.7870 26.5015 28.1994
% 20.2548 24.9943 18.0349 19.5158 25.9324
%d
years = unique(year(daily_log_return.dates));
rv_year = nan(length(years),5);
for i = 1965:2010
ind_temp = (year(daily_log_return.dates) == i);
rv_year(i-1964,:) = nanstd(daily_log_return(ind_temp)) * sqrt(250) * 100;
end
plot(years, rv_year)
title('Yearly RV')
legend('US','UK','Jap','HK','CH')
%e
rv_month = nan(length(years)*12,5);
for i = 1965:2010
for j = 1:12
ind_temp = ((year(daily_log_return.dates) == i) .* (month(daily_log_return.dates) == j));
rv_month((i-1965)*12+j,:) = nanstd(daily_log_return(logical(ind_temp))) * sqrt(250) * 100;
end
end
rv_month = rv_month(1:547,:); % 2010 only has 7 months, omit the last 5 rows
[Y,M] = meshgrid(1965:2010, 1:12);
xaxis = datenum([Y(:), M(:), ones(numel(Y),1)]);
xaxis = xaxis(1:547);
plot((xaxis), rv_month);
datetick('x','yyyy','keeplimits')
title('Monthly RV')
legend('US','UK','Jap','HK','CH')
%f
rv_month = rv_month/100;
tsUS = rv_month(:,1);
tsUS(isnan(tsUS)) = [];
tsUK = rv_month(:,2);
tsUK(isnan(tsUK)) = [];
tsJAP = rv_month(:,3);
tsJAP(isnan(tsJAP)) = [];
tsHK = rv_month(:,4);
tsHK(isnan(tsHK)) = [];
tsCH = rv_month(:,5);
tsCH(isnan(tsCH)) = [];
fitlm(tsUS(2:end),tsUS(1:(end-1)))
fitlm(tsUK(2:end),tsUK(1:(end-1)))
fitlm(tsJAP(2:end),tsJAP(1:(end-1)))
fitlm(tsHK(2:end),tsHK(1:(end-1)))
fitlm(tsCH(2:end),tsCH(1:(end-1)))
%g
plot(1:(length(tsUS)-1), predict(fitlm(tsUS(2:end),tsUS(1:(end-1)))))
hold on
plot(1:(length(tsUS)-1), tsUS(2:end))
legend('US predicted values','UK observed values')
hold off
%h
for i = 1:10
temp_mat = fts2mat(daily_log_return);
[m, mI] = nanmax(temp_mat(:,1));
daily_log_return.US(mI) = NaN;
end
for i = 1:10
temp_mat = fts2mat(daily_log_return);
[m, mI] = nanmax(temp_mat(:,2));
daily_log_return.UK(mI) = NaN;
end
for i = 1:10
temp_mat = fts2mat(daily_log_return);
[m, mI] = nanmax(temp_mat(:,3));
daily_log_return.JAP(mI) = NaN;
end
for i = 1:10
temp_mat = fts2mat(daily_log_return);
[m, mI] = nanmax(temp_mat(:,4));
daily_log_return.HK(mI) = NaN;
end
for i = 1:10
temp_mat = fts2mat(daily_log_return);
[m, mI] = nanmax(temp_mat(:,5));
daily_log_return.CH(mI) = NaN;
end
rv_month = nan(length(years)*12,5);
for i = 1965:2010
for j = 1:12
ind_temp = ((year(daily_log_return.dates) == i) .* (month(daily_log_return.dates) == j));
rv_month((i-1965)*12+j,:) = nanstd(daily_log_return(logical(ind_temp))) * sqrt(250) * 100;
end
end
rv_month = rv_month(1:547,:); % 2010 only has 7 months, omit the last 5 rows
[Y,M] = meshgrid(1965:2010, 1:12);
xaxis = datenum([Y(:), M(:), ones(numel(Y),1)]);
xaxis = xaxis(1:547);
plot((xaxis), rv_month);
datetick('x','yyyy','keeplimits')
title('Monthly RV')
legend('US','UK','Jap','HK','CH')
%i
rv_month = rv_month/100;
tsUS = rv_month(:,1);
tsUS(isnan(tsUS)) = [];
tsUK = rv_month(:,2);
tsUK(isnan(tsUK)) = [];
tsJAP = rv_month(:,3);
tsJAP(isnan(tsJAP)) = [];
tsHK = rv_month(:,4);
tsHK(isnan(tsHK)) = [];
tsCH = rv_month(:,5);
tsCH(isnan(tsCH)) = [];
% ar1 = arima(1,0,0);
% ar1US = estimate(ar1,tsUS);
fitlm(tsUS(2:end),tsUS(1:(end-1)))
fitlm(tsUK(2:end),tsUK(1:(end-1)))
fitlm(tsJAP(2:end),tsJAP(1:(end-1)))
fitlm(tsHK(2:end),tsHK(1:(end-1)))
fitlm(tsCH(2:end),tsCH(1:(end-1)))
% Yes. All the estimators obtain large p-values. This implies that the
% preivious RV_t is significant for the AR(1) model for predicting RV_t+1.
% The model is not sensitive with the outliers. Even through the outlier
% were omitted, the estimation results does not changed significantly.
%% Q4
%abc
arch1 = garch(0,1);
temp_months = fts2mat(monthly_log_return);
figure
hold on
for i = 1:5
tempcountry = temp_months(:,i);
tempcountry(logical(isnan(tempcountry)+isinf(tempcountry))) = [];
[EstMdl,EstParamCov] = estimate(arch1,tempcountry)
plot(1:547,[repmat(NaN, 547-length(tempcountry), 1); infer(EstMdl, tempcountry)*sqrt(12) * 100])
se = sqrt(diag(EstParamCov))
end
title('Monthly RV')
legend('US','UK','Jap','HK','CH')
hold off
%def
garch1 = garch(1,1);
temp_months = fts2mat(monthly_log_return);
figure
hold on
for i = 1:5
tempcountry = temp_months(:,i);
tempcountry(logical(isnan(tempcountry)+isinf(tempcountry))) = [];
[EstMdl,EstParamCov] = estimate(garch1,tempcountry)
plot(1:547,[repmat(NaN, 547-length(tempcountry), 1); infer(EstMdl, tempcountry)*sqrt(12) * 100])
se = sqrt(diag(EstParamCov))
end
title('Monthly RV')
legend('US','UK','Jap','HK','CH')
hold off
% more persistent. Generalized ARCH allows us to capture
%the persistence of conditional volatility in a parsimonious way.
%% Q5
gjr11 = gjr(1,1);
temp_months = fts2mat(monthly_log_return);
figure
hold on
for i = 1:5
tempcountry = temp_months(:,i);
tempcountry(logical(isnan(tempcountry)+isinf(tempcountry))) = [];
[EstMdl,EstParamCov] = estimate(gjr11,tempcountry)
plot(1:547,[repmat(NaN, 547-length(tempcountry), 1); infer(EstMdl, tempcountry)*sqrt(12) * 100])
se = sqrt(diag(EstParamCov))
end
title('Monthly RV')
legend('US','UK','Jap','HK','CH')
hold off
%According to the t statistics, we found the evidence of asymmetries for
%all five countries except China.
%% Q6
%all for all countries
all_daily_table = fints(date, Indx, label);
all_daily_log_return = diff(log(all_daily_table));
all_monthly_table = tomonthly(all_daily_table);
all_monthly_log_return = diff(log(all_monthly_table));
% convert Inf (due to the logarithm) to NaN
all_daily_log_return = fts2mat(all_daily_log_return);
all_daily_log_return(isinf(all_daily_log_return)) = NaN;
all_monthly_log_return = fts2mat(all_monthly_log_return);
all_monthly_log_return(isinf(all_monthly_log_return)) = NaN;
% average daily return
all_mean_daily = nanmean(all_daily_log_return);
% annualized return:
(exp(all_mean_daily * 250) - 1) * 100
%b. annualized RV:
all_rv_daily = nanstd(all_daily_log_return);
all_rv_daily * sqrt(250)*100
%c
%extract decades, e.g. 196 is 60s; 201 is 2010s
ind60 = floor(year(date)/10) == 196; % index for 60s, so on
ind70 = floor(year(date)/10) == 197;
ind80 = floor(year(dates)/10) == 198;
ind90 = floor(year(dates)/10) == 199;
ind00 = floor(year(dates)/10) == 200;
ind10 = floor(year(dates)/10) == 201;
[nanstd(all_daily_log_return(ind60,:)) * sqrt(250) * 100;
nanstd(all_daily_log_return(ind70,:)) * sqrt(250) * 100;
nanstd(all_daily_log_return(ind80,:)) * sqrt(250) * 100;
nanstd(all_daily_log_return(ind90,:)) * sqrt(250) * 100;
nanstd(all_daily_log_return(ind00,:)) * sqrt(250) * 100;
nanstd(all_daily_log_return(ind10,:)) * sqrt(250) * 100;]
%d
ddate = date(2:end); % omit the first day
years = unique(year(ddate));
rv_year = nan(length(years),73);
for i = 1965:2010
ind_temp = (year(ddate) == i);
rv_year(i-1964,:) = nanstd(all_daily_log_return(ind_temp,:)) * sqrt(250) * 100;
end
figure
hold on
for i = 1:73
if devel_dum(i) == 0
plot(years, rv_year(:,i), 'color','red')
else
plot(years, rv_year(:,i), 'color','blue')
end
end
title('Yearly RV; developed country: red; developing country: blue')
hold off
%e
%e
rv_month = nan(length(years)*12,73);
for i = 1965:2010
for j = 1:12
ind_temp = ((year(ddate) == i) .* (month(ddate) == j));
rv_month((i-1965)*12+j,:) = nanstd(all_daily_log_return(logical(ind_temp),:)) * sqrt(250) * 100;
end
end
rv_month = rv_month(1:547,:); % 2010 only has 7 months, omit the last 5 rows
figure
hold on
for i = 1:73
if devel_dum(i) == 0
plot(1:547, rv_month(:,i), 'color','red')
else
plot(1:547, rv_month(:,i), 'color','blue')
end
end
title('Monthly RV; developed country: red; developing country: blue')
hold off
%f
rv_month = rv_month/100;
for i = 1:73
label(i)
ts_temp = rv_month(:,i);
ts_temp(isnan(ts_temp)) = [];
fitlm(ts_temp(2:end),ts_temp(1:(end-1)))
end
%h
for i = 1:73
for j = 1:10
temp_mat = all_daily_log_return(:,i);
[m, mI] = nanmax(temp_mat(:,1));
all_daily_log_return(mI,i) = NaN;
end
end
rv_month = nan(length(years)*12,73);
for i = 1965:2010
for j = 1:12
ind_temp = ((year(ddate) == i) .* (month(ddate) == j));
rv_month((i-1965)*12+j,:) = nanstd(all_daily_log_return(logical(ind_temp),:)) * sqrt(250) * 100;
end
end
rv_month = rv_month(1:547,:); % 2010 only has 7 months, omit the last 5 rows
figure
hold on
for i = 1:73
if devel_dum(i) == 0
plot(1:547, rv_month(:,i), 'color','red')
else
plot(1:547, rv_month(:,i), 'color','blue')
end
end
title('Monthly RV; developed country: red; developing country: blue')
hold off
%i
rv_month = rv_month/100;
for i = 1:73
label(i)
ts_temp = rv_month(:,i);
ts_temp(isnan(ts_temp)) = [];
fitlm(ts_temp(2:end),ts_temp(1:(end-1)))
end
%4
%abc
arch1 = garch(0,1);
figure
hold on
for i = 1:73
label(i)
tempcountry = all_monthly_log_return(:,i);
tempcountry(logical(isnan(tempcountry)+isinf(tempcountry))) = [];
[EstMdl,EstParamCov] = estimate(arch1,tempcountry);
if devel_dum(i) == 0
plot(1:547,[repmat(NaN, 547-length(tempcountry), 1); infer(EstMdl, tempcountry)*sqrt(12) * 100],...
'color','red')
else
plot(1:547,[repmat(NaN, 547-length(tempcountry), 1); infer(EstMdl, tempcountry)*sqrt(12) * 100],...
'color','blue')
end
se = sqrt(diag(EstParamCov));
end
title('Monthly RV; developed country: red; developing country: blue')
hold off
%def
garch1 = garch(1,1);
figure
hold on
for i = 1:73
label(i)
tempcountry = all_monthly_log_return(:,i);
tempcountry(logical(isnan(tempcountry)+isinf(tempcountry))) = [];
[EstMdl,EstParamCov] = estimate(garch1,tempcountry);
if devel_dum(i) == 0
plot(1:547,[repmat(NaN, 547-length(tempcountry), 1); infer(EstMdl, tempcountry)*sqrt(12) * 100],...
'color','red')
else
plot(1:547,[repmat(NaN, 547-length(tempcountry), 1); infer(EstMdl, tempcountry)*sqrt(12) * 100],...
'color','blue')
end
se = sqrt(diag(EstParamCov));
end
title('Monthly RV; developed country: red; developing country: blue')
hold off
gjr11 = gjr(1,1);
figure
hold on
for i = 1:73
label(i)
devel_dum(i)
tempcountry = all_monthly_log_return(:,i);
tempcountry(logical(isnan(tempcountry)+isinf(tempcountry))) = [];
[EstMdl,EstParamCov] = estimate(gjr11,tempcountry);
if devel_dum(i) == 0
plot(1:547,[repmat(NaN, 547-length(tempcountry), 1); infer(EstMdl, tempcountry)*sqrt(12) * 100],...
'color','red')
else
plot(1:547,[repmat(NaN, 547-length(tempcountry), 1); infer(EstMdl, tempcountry)*sqrt(12) * 100],...
'color','blue')
end
se = sqrt(diag(EstParamCov));
end
title('Monthly RV; developed country: red; developing country: blue')
hold off
- For the rest of the analysis, use the following 5 countries: US, UK, Japan, Hong Kong, and China.See the m script.
- Compute the daily and monthly log returns for the 5 countries. Make sure you locate them correctly in the dataset.
See Appendix A: the daily and monthly log returns for the 5 countries - For the following part of the analysis, use only monthly log returns for the 5 countries.
- For the following part of the analysis, use only monthly log returns for the 5 countries.
- For the following part of the analysis, use only monthly log returns for the 5 countries.
- For the following part of the analysis, use only monthly log returns for the 5 countries.For the following part of the analysis, use only daily log returns for the 5 countries.(a) Compute the average returns for all countries, expressed in annualized percents.Annualized return (%): 9.4029 11.2655 6.5787 11.9300 11.1869.
(b) Compute the standard deviation (realized volatility) of returns for all countries, expressed in annualized percents.
Annualized realized volatility (%): 17.0532 19.0475 20.4422 30.4970 38.4871.(c) Break the sample into decades (eg 70s, 80s, …). For each country and decade, computeStandard deviations (realized volatility) of returns (whenever possible), expressed inannualized percents. US Uk Jap HK China60s NaN 12.9044 NaN 16.0274 NaN70s 14.3688 20.6744 14.1688 34.2972 NaN
80s 16.2006 19.1892 17.2237 33.7533 NaN
90s 13.5458 14.4014 23.3901 27.2376 48.1655
00s 21.8650 23.0491 23.7870 26.5015 28.1994
10s 20.2548 24.9943 18.0349 19.5158 25.9324
(d) Do the same for every one-year period. Plot the results (all countries in one plot), expressed in annualized percents.
(e) Do the same for every month. Plot the results (all countries in one plot), expressed in annualized percents.
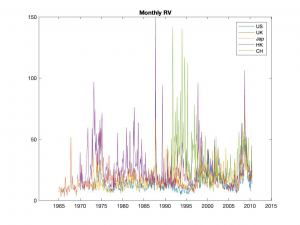
代写金融作业 (f) Run the following regressions (one for each country) using the monthly realized volatilities
in part (e):
Let chat and phihat be the estimates of c and phi, respectively. The corresponding t-statistics are in braces.
US: chat = 0.050437 (8.469); phihat = 0.65231 (18.199); R-square = 0.425.UK: chat = 0.062021 (10.01); phihat = 0.62314 (18.551); R-square = 0.387.
Japan: chat = 0.08015 (10.273); phihat = 0.55654 (14.176); R-square = 0.31.
Hong Kong: chat = 0.10886 (9.9249); phihat = 0.56958 (15.283); R-square = 0.325.
China: chat = 0.16699 (7.895); phihat = 0.46435 (7.932); R-square = 0.216.
(g) Are the volatilities predictable? Why?
Yes, the volatilities is relatively predictable because the estimators are significant with very large absolute t values, which implies that the volatility tomorrow can be significantly explained by the volatility today.
(h) Now, re-compute monthly realized volatilities of every country (as in part (e)) but first exclude the largest 10 daily outliers for each country from the data.
See the m script.(i) Re-run the same regressions and analysis as in part (f).
US: chat = 0.050437 (8.469); phihat = 0.65231 (18.199); R-square = 0.425.
UK: chat = 0.062021 (10.01); phihat = 0.62314 (18.551); R-square = 0.387.
Japan: chat = 0.08015 (10.273); phihat = 0.55654 (14.176); R-square = 0.31.
Hong Kong: chat = 0.10886 (9.9249); phihat = 0.56958 (15.283); R-square = 0.325.
China: chat = 0.16699 (7.895); phihat = 0.46435 (7.932); R-square = 0.216.
(j) Did your estimates change significantly? Why?
4.No. Because the daily outliers do not affect the monthly volatilities much. The estimates do not change after omitting the ten largest daily outliers. Further, we conclude that the model is robust in the sense that it is not sensitive with the outliers.
(a) Estimate an ARCH(1) for each country. Compute standard errors using the Hessian method.
Let zetahat and alphahat be the estimators of zeta and alpha in ARCH(1) model. The corresponding standard errors are in braces.US: zetahat = 0.00190971(0.000107112); alphahat = 0.115896(0.0431546);
UK: zetahat = 0. 00318006(0. 000120722); alphahat = 0. 154723(0. 0567513);
Japan: zetahat = 0. 00332467(0. 000257953); alphahat = 0. 121348(0. 0477942);
Hong Kong: zetahat = 0. 00707944(0. 000468675); alphahat = 0. 435003(0. 0576163);
China: zetahat = 0. 0144135 (0. 000847664); alphahat = 0. 157127 (0. 0667098).
(b) Plot the ARCH(1) estimates of the monthly volatilities (all countries in one plot), expressed in annualized percents.
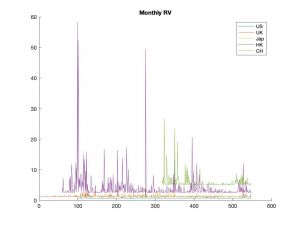
(c) Based on the ARCH(1) results, do you conclude that the monthly volatilities are persistent?
No, the monthly volatilities are not persistent since the impulse has large frequency and the curves have a large amount of peaks due to the small alpha’s.
(d) Estimate a GARCH(1,1) for each country. Compute standard errors using the Hessian method.
Let zetahat, alphahat, and deltahat be the estimators of zeta, alpha, and delta in GARCH(1,1) model. The corresponding standard errors are in braces.
US:
zetahat = 0. 000105881(5.67256e-05); alphahat = 0. 106849(0. 0271111); deltahat = 0.85121(0.0359651);
UK:
zetahat = 8.56841e-05 (4.59691e-05); alphahat = 0. 104627 (0. 0180071);
deltahat = 0. 879283 (0.0222718);
Japan:
zetahat = 0.0003334 (0.00019018); alphahat = 0. 108786(0. 0381217); deltahat = 0. 803807(0. 0743386);
Hong Kong:
zetahat = 0. 000573095(0. 000223863); alphahat = 0. 262737 (0. 0459238);
deltahat = 0.722435(0. 0502314);
China:
zetahat = 0. 000116806(0.000105747); alphahat = 0. 068612(0. 0179005);
deltahat = 0.922773(0.0145861).
详细报告不贴出!更多 代写金融作业 案例点击这里
- For the following part of the analysis, use only monthly log returns for the 5 countries.For the following part of the analysis, use only daily log returns for the 5 countries.(a) Compute the average returns for all countries, expressed in annualized percents.Annualized return (%): 9.4029 11.2655 6.5787 11.9300 11.1869.
