总述先看看官方给出的这145万余条数据的字段信息描写:id – a unique identifier for each tripvendor_id – a code indicating the provider associated with the trip recordpickup_datetime – date and time when the meter was engageddropoff_datetime – date and time when the meter was disengagedpassenger_count – the number of passengers in the vehicle (driver entered value)pickup_longitude – the longitude where the meter was engagedpickup_latitude – the latitude where the meter was engageddropoff_longitude – the longitude where the meter was disengageddropoff_latitude – the latitude where the meter was disengagedstore_and_fwd_flag – This flag indicates whether the trip record was held in vehicle memory before sending to the vendor because the vehicle did not have a connection to the server – Y=store and forward; N=not a store and forward triptrip_duration – duration of the trip in seconds
一共11个字段,个中包罗上下车时间、上下车经纬度、路程时长、搭客人数、数据记录发送种别(储存发归照旧直接发送)、数据提供者的id编号
正文#用到的包library(dplyr)library(lubridate)library(data.table)library(geosphere)library(ggplot2)library(gridExtra)
第一部门:数据的根基轮廓和处理惩罚#1.数据读取train <-tbl_df(fread(“train.csv”))由于数据量较大,利用fread函数举办读取,并转化为tbl工具范例
#2.数据的根基环境class(train)

glimpse(train)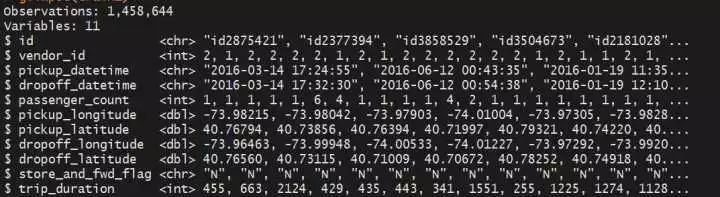 summary(train)
summary(train)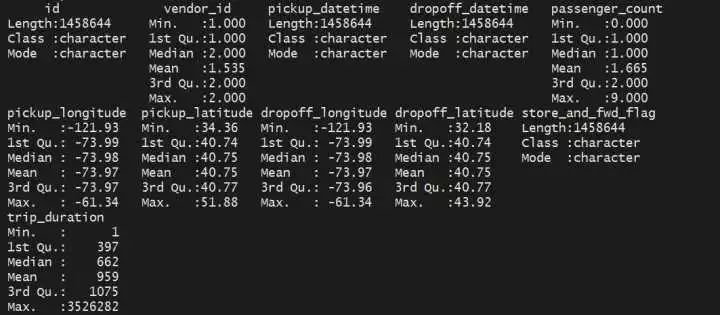 可以看到:(1)上下车时间为chr范例,需转化为时间范例(2)vendor_id有大概不是1就是2,是不是可以把这个字段领略为出租车公司的编号(公司1、公司2)(3)路程时长最长的为3526282秒,我的天,快要41天??(4)搭客数目标中位数为1,平均数为1.665,可以先猜测一下,是不是单人打车的环境最多见?
可以看到:(1)上下车时间为chr范例,需转化为时间范例(2)vendor_id有大概不是1就是2,是不是可以把这个字段领略为出租车公司的编号(公司1、公司2)(3)路程时长最长的为3526282秒,我的天,快要41天??(4)搭客数目标中位数为1,平均数为1.665,可以先猜测一下,是不是单人打车的环境最多见?
#3.看看有没有缺失值####sum(is.na(train))
这的确是个福音,没有缺失值的数据集是何等的可爱
#4.把上下车时间、出租车公司的ID、搭客数改一下字段范例train <- train %>% mutate(pickup_datetime = ymd_hms(pickup_datetime), dropoff_datetime = ymd_hms(dropoff_datetime), vendor_id = factor(vendor_id), passenger_count = factor(passenger_count))
#5.trip_duration和上下车时间计较出来的数据是否一致train %>% mutate(check = abs(int_length(interval(pickup_datetime,dropoff_datetime)) – trip_duration) == 0) %>% select(check,pickup_datetime,dropoff_datetime,trip_duration) %>% group_by(check) %>% count() 可以看到,时长和上下车时间计较出来的功效保持一致
可以看到,时长和上下车时间计较出来的功效保持一致
#6.添加一些字段#(1)从上车时间可以提取出礼拜几、月份、时段,添加这三个字段train <- train %>% mutate(weekday = wday(pickup_datetime,label = TRUE), month = month(pickup_datetime,label = TRUE), hour = hour(pickup_datetime))#(2)从上下车经纬度可以整合出两点之间的间隔(km),撤除旅程时长,可以得出速度,添加这两个字段
pickuplocation <- train %>% select(pickup_longitude,pickup_latitude)dropofflocation <- train %>% select(dropoff_longitude,dropoff_latitude)#间隔,单元为km
train <- train %>% mutate(distance = distHaversine(pickuplocation,dropofflocation)/1000) #速度,单元km/h
train <- train %>% mutate(speed = distance/trip_duration*3600)留意,这里的间隔利用的是distHaversine函数计较得出两点的最短间隔,该间隔成立在haversine模子上得出,这里就不深入接头了,有乐趣的伴侣可以自行google 第二部门 数据可视化展示(单字段)颠末第一部门对原始数据简朴的相识及处理惩罚,举办相对应的数据可视化展示,先单独看看各个字段的数据环境:(1)视察vendor_id的环境p1 <- train %>% ggplot(aes(vendor_id,fill = vendor_id)) + geom_bar() + theme(legend.position = “null”)
第二部门 数据可视化展示(单字段)颠末第一部门对原始数据简朴的相识及处理惩罚,举办相对应的数据可视化展示,先单独看看各个字段的数据环境:(1)视察vendor_id的环境p1 <- train %>% ggplot(aes(vendor_id,fill = vendor_id)) + geom_bar() + theme(legend.position = “null”)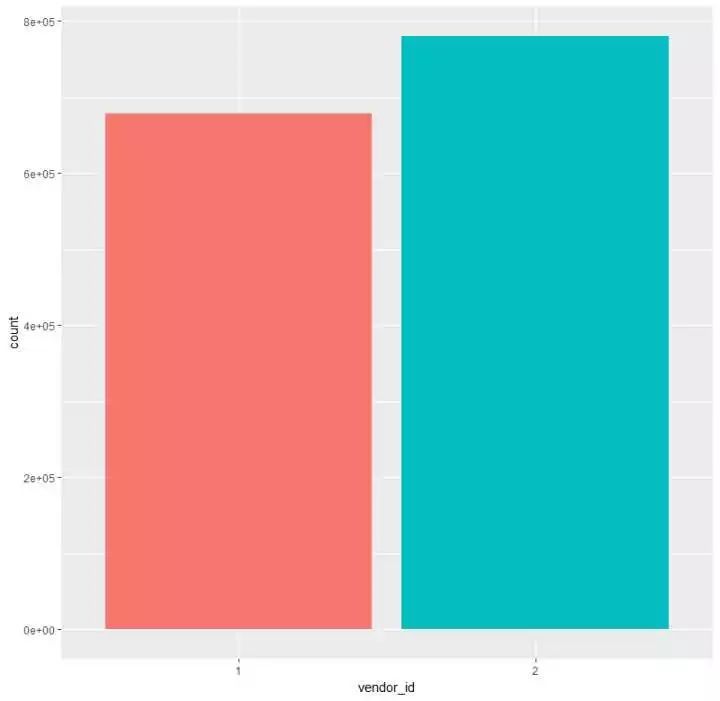 发明和之前的假设沟通,只有两种环境,且vendor_id为2的环境比vendor_id为1的环境多了10W条阁下
发明和之前的假设沟通,只有两种环境,且vendor_id为2的环境比vendor_id为1的环境多了10W条阁下
(2)#视察上车、下车时间的漫衍环境;组合比拟一下p2 <- train %>% ggplot(aes(pickup_datetime)) + geom_histogram(bins = 250,fill=”orange”)p3 <- train %>% ggplot(aes(dropoff_datetime)) + geom_histogram(bins = 250,fill=”skyblue”)p23 <- grid.arrange(p2,p3,nrow =2)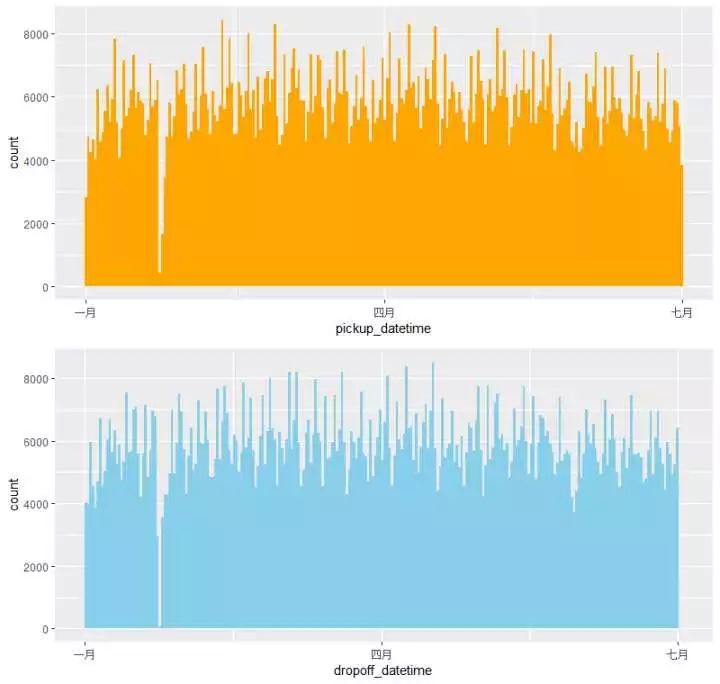 发明:(1)所有的打的记录都在1-6月份(2)概略上看去整个漫衍照旧较量匀称的,可是在1月底2月初之间呈现了一个很明明的回落趋势,来放大这个区间看看环境:
发明:(1)所有的打的记录都在1-6月份(2)概略上看去整个漫衍照旧较量匀称的,可是在1月底2月初之间呈现了一个很明明的回落趋势,来放大这个区间看看环境: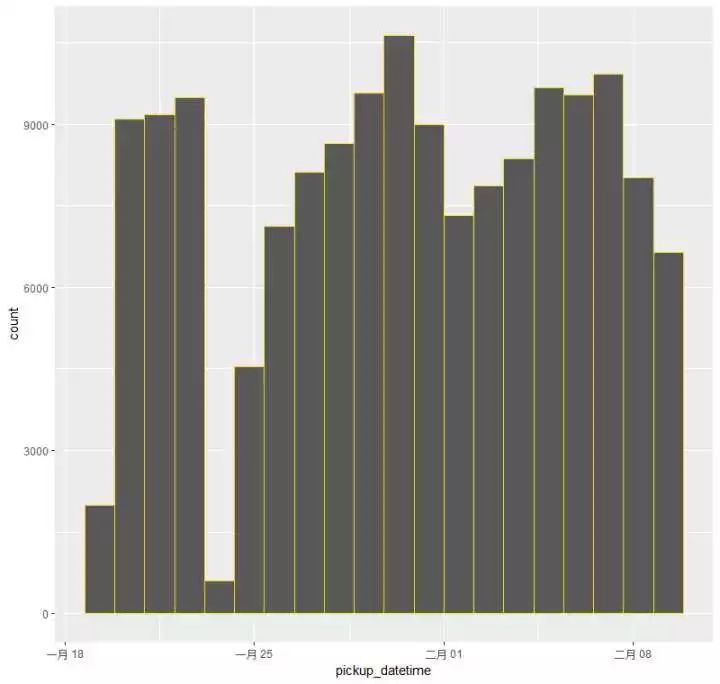 或许是23-25号之间,打车记录的数目呈现了一个很明明的下降,打的作为一项平日里很稀松泛泛的工作,逐日的订单量应该是相对平均的,这是为什么呢?是那几天出租车涨价?照旧雷同于停电一小时的勾当,号令不打的勾当?照旧天灾人祸?google一下,谜底是暴!风!雪!
或许是23-25号之间,打车记录的数目呈现了一个很明明的下降,打的作为一项平日里很稀松泛泛的工作,逐日的订单量应该是相对平均的,这是为什么呢?是那几天出租车涨价?照旧雷同于停电一小时的勾当,号令不打的勾当?照旧天灾人祸?google一下,谜底是暴!风!雪!
 (3)看看搭客数量的一个漫衍p4 <- train%>% ggplot(aes(passenger_count,fill = passenger_count)) + geom_bar() +theme(legend.position = “null”) + scale_y_sqrt()
(3)看看搭客数量的一个漫衍p4 <- train%>% ggplot(aes(passenger_count,fill = passenger_count)) + geom_bar() +theme(legend.position = “null”) + scale_y_sqrt()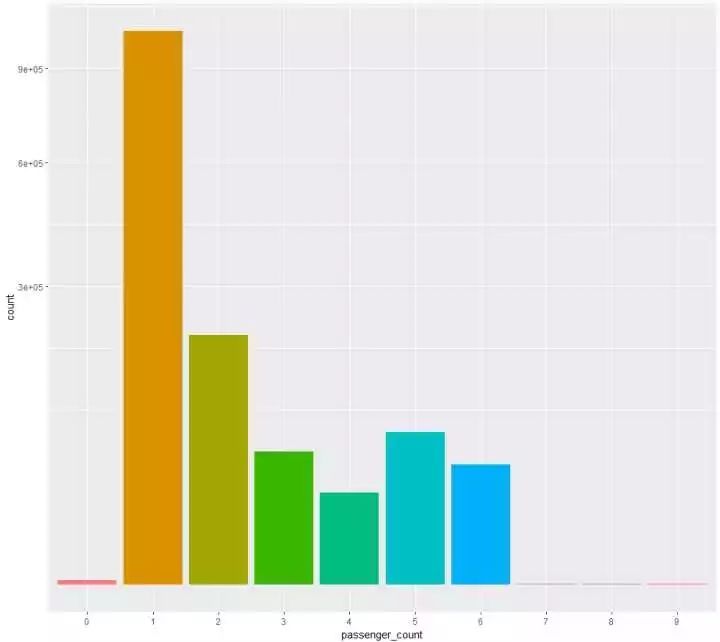 发明:(1)单人打车的环境最多,在145万多条的记录中,有100W+是单人打车的环境(2)呈现了搭客为0的打的记录(3)本来美国出租车还可以坐四个以上的搭客,并且5、6名搭客环境还不少,中国的的士有可以坐4个以上搭客的吗?
发明:(1)单人打车的环境最多,在145万多条的记录中,有100W+是单人打车的环境(2)呈现了搭客为0的打的记录(3)本来美国出租车还可以坐四个以上的搭客,并且5、6名搭客环境还不少,中国的的士有可以坐4个以上搭客的吗?
(4)看看记录是否第一时间发送处事器的环境漫衍p5 <- train %>% ggplot(aes(store_and_fwd_flag,fill = store_and_fwd_flag)) + geom_bar() +theme(legend.position = “null”) + scale_y_log10()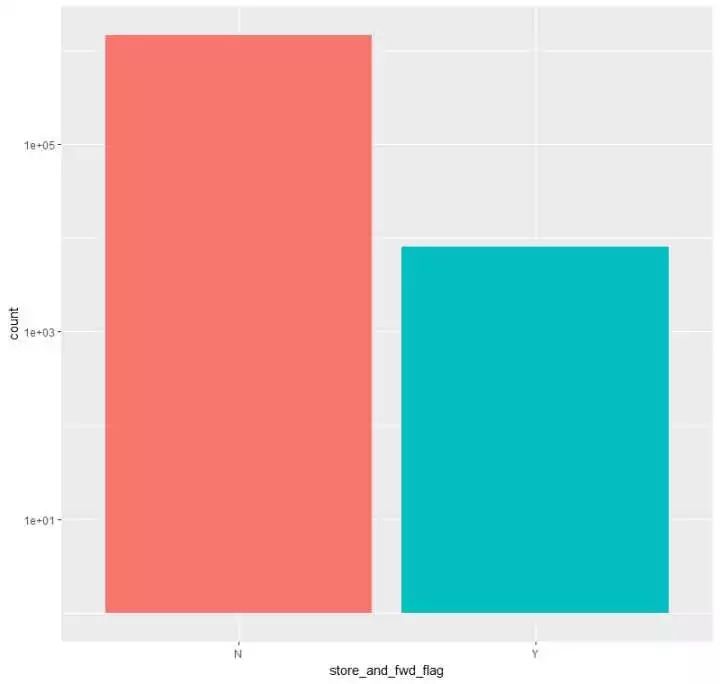 可以看到not a store and forward trip的环境要占大大都
可以看到not a store and forward trip的环境要占大大都
(5)看看观光时长的漫衍p6 <- train %>% ggplot(aes(trip_duration)) + geom_histogram(bins = 10000,fill=”red”) + coord_cartesian(x=c(1,6000))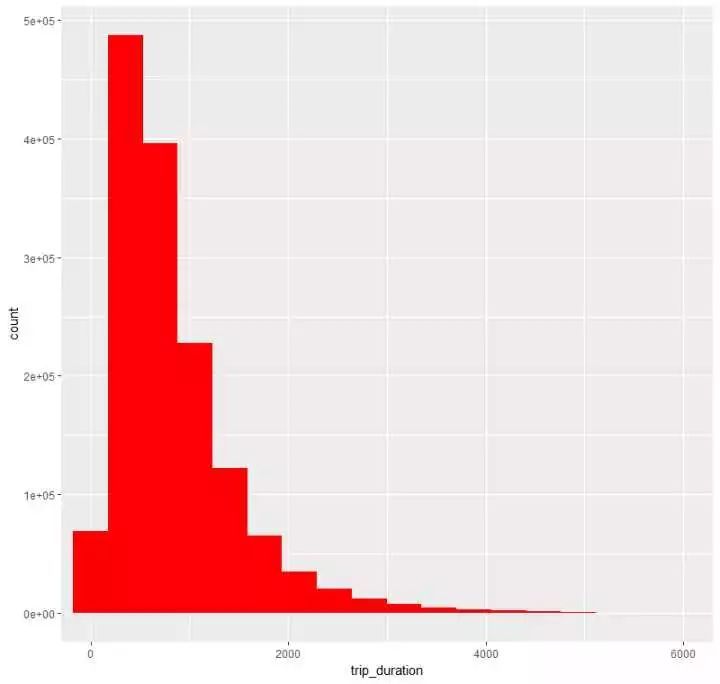 看出,主要的时长照旧会合在1000秒阁下,即15分钟这样,虽然尚有一些时间很是短或则出格长的环境产生
看出,主要的时长照旧会合在1000秒阁下,即15分钟这样,虽然尚有一些时间很是短或则出格长的环境产生
(6)接下来定时间漫衍来视察下打车环境,哪个时段打车多?礼拜几出租车最忙?#看看天天打的数量的漫衍\趋势p7<- train %>% group_by(weekday) %>% count() %>% ggplot(aes(weekday,n,group=1)) + geom_line(size=1.5,color=”lightblue”) + geom_point(size=1.5,shape =17)#看看每月打的数量的漫衍\趋势p8<- train %>% group_by(month) %>% count() %>% ggplot(aes(month,n,group=1)) + geom_line(size=2,color=”lightblue”) + geom_point(size=2,shape =17)
#看看每个时段打的数量的漫衍\趋势p9<- train %>% mutate(hour= hour(pickup_datetime)) %>% group_by(hour) %>% count() %>% ggplot(aes(hour,n)) + geom_line(size=2,color = “lightblue”) + geom_point(size=2,shape=17)p789 <- grid.arrange(p7,p8,p9,ncol=1)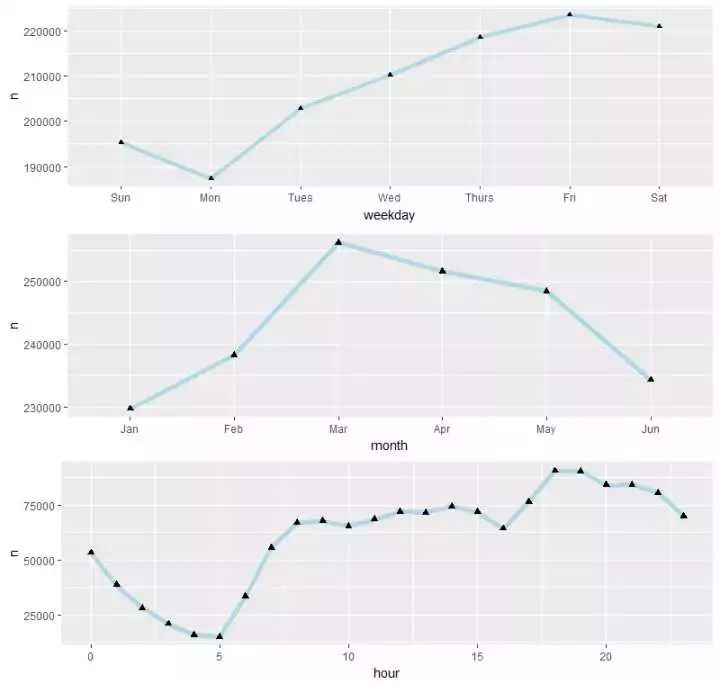 看来(1)NYC的出租车最忙的时间会合在周五、周六(2)3-5月份打的的人最多,和旅游旺季有必然干系吗?(3)对付天天而言,照旧切合我们的日常认识的,0-5点打车的人越来越少,到了晚上,嗯,call a taxi ,get high!
看来(1)NYC的出租车最忙的时间会合在周五、周六(2)3-5月份打的的人最多,和旅游旺季有必然干系吗?(3)对付天天而言,照旧切合我们的日常认识的,0-5点打车的人越来越少,到了晚上,嗯,call a taxi ,get high!
(7)看看旅程间隔\速度的漫衍,组合p10 <- train %>% ggplot(aes(distance)) + geom_histogram(bins = 4000,fill=”red”) +coord_cartesian(x=c(0,30))p11 <- train %>% ggplot(aes(speed)) + geom_histogram(bins = 3000,fill=”orange”) +coord_cartesian(x=c(0,100))p1011 <- grid.arrange(p10,p11,ncol=1)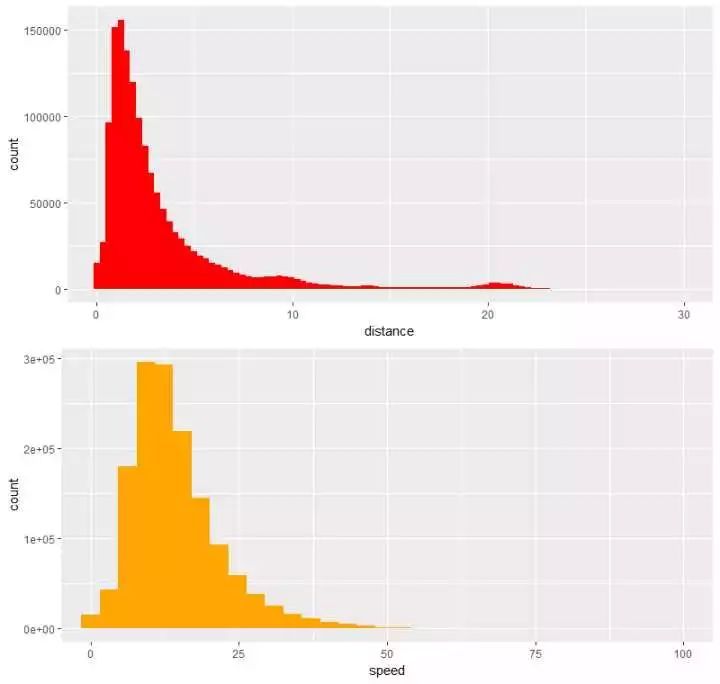 发明:(1)主要的旅程间隔会合在1-3公里这个范畴内(2)行驶的速度会合在13-15km/h,我的天!这么堵?第三部门 数据可视化展示(组合字段)接下来,试着组合一些字段举办可视化的展示,看看还能得出什么信息(1)看一下7个weekday差异时段的打车环境、6个月每个时段的打车环境,组合一下p12 <-train %>% group_by(weekday,hour) %>% count() %>% ggplot(aes(hour,n,color=weekday)) + geom_line(size=2) + scale_color_brewer(palette = “Set1”)p13 <- train %>% group_by(month,hour) %>% count() %>% ggplot(aes(hour,n,color=month)) + geom_line(size=2) + scale_color_brewer(palette = “Set2”)p1213 <- grid.arrange(p12,p13,nrow=2)
发明:(1)主要的旅程间隔会合在1-3公里这个范畴内(2)行驶的速度会合在13-15km/h,我的天!这么堵?第三部门 数据可视化展示(组合字段)接下来,试着组合一些字段举办可视化的展示,看看还能得出什么信息(1)看一下7个weekday差异时段的打车环境、6个月每个时段的打车环境,组合一下p12 <-train %>% group_by(weekday,hour) %>% count() %>% ggplot(aes(hour,n,color=weekday)) + geom_line(size=2) + scale_color_brewer(palette = “Set1”)p13 <- train %>% group_by(month,hour) %>% count() %>% ggplot(aes(hour,n,color=month)) + geom_line(size=2) + scale_color_brewer(palette = “Set2”)p1213 <- grid.arrange(p12,p13,nrow=2)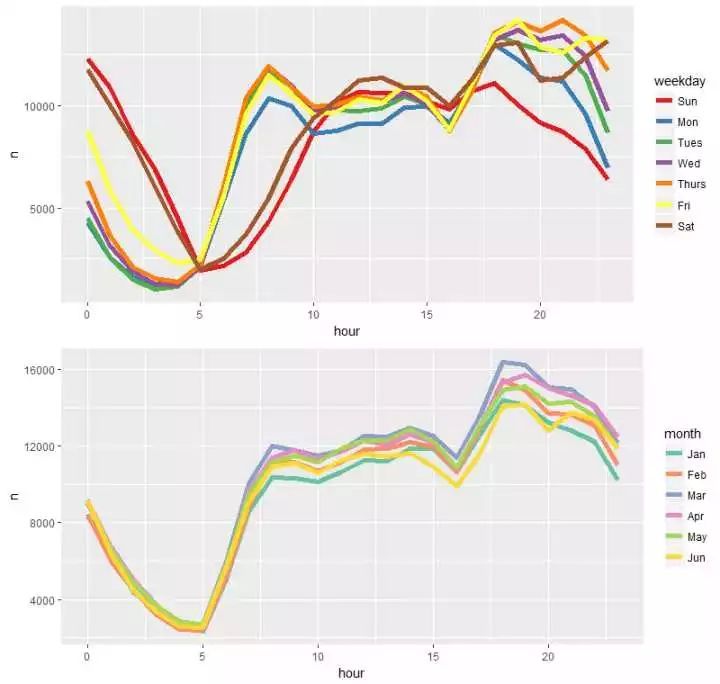 看出:(1)周六、周日破晓,打车的环境会比其他事情日多不少,而周日深夜时段打车的数量是一周7天中最少的,收收心,第二天上班?(2)正常事情日,早上打的的数量明明要比周末来的多,切合出行纪律(3)第二张图,除了看出3月份打车环境比其它月份来的多,除此并没有其它大的区别
看出:(1)周六、周日破晓,打车的环境会比其他事情日多不少,而周日深夜时段打车的数量是一周7天中最少的,收收心,第二天上班?(2)正常事情日,早上打的的数量明明要比周末来的多,切合出行纪律(3)第二张图,除了看出3月份打车环境比其它月份来的多,除此并没有其它大的区别
(2)按搭客数目分组,看看观光时长的漫衍p14<- train %>% ggplot(aes(passenger_count,trip_duration,color=passenger_count)) + geom_boxplot() + scale_y_log10() + theme(legend.position = “null”)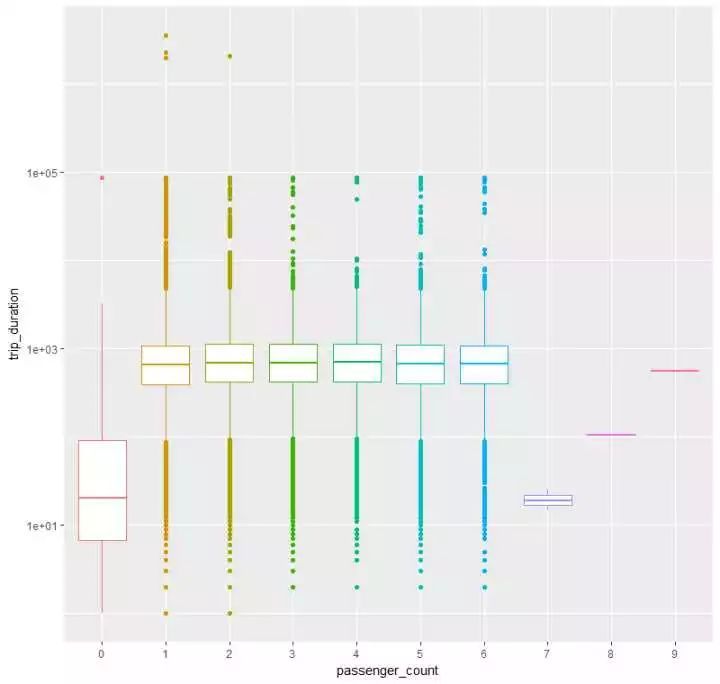 撤除数据量很小的0、7、8、9几个种别外,仿佛,并看不出什么…看来并不会因为搭客数量的几多而影响时长
撤除数据量很小的0、7、8、9几个种别外,仿佛,并看不出什么…看来并不会因为搭客数量的几多而影响时长
(3)看看是否第一时间储存记录和vendor_id的干系p14 <- train %>%ggplot(aes(vendor_id,fill=store_and_fwd_flag)) + geom_bar(position = “dodge”)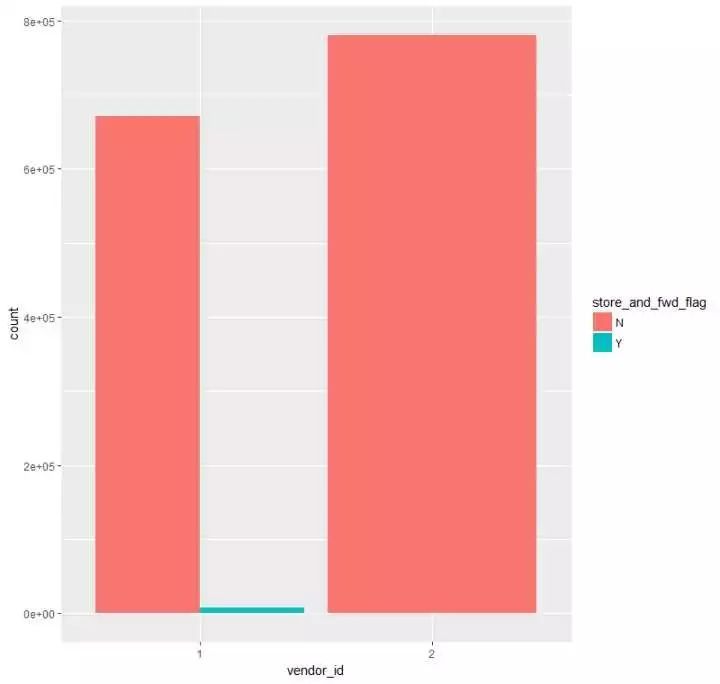 可以看出,vendor_id为2的环境下,是没有store and forward trip的环境的
可以看出,vendor_id为2的环境下,是没有store and forward trip的环境的
总述这是在kaggle上进修后的第一篇实践输出,也参考了不少其它大神的代码和思路,主要是对R中dplyr、lubirdate、ggplot2包实战利用举办操练记录。深深感受到本身的缺陷与不敷,不能举办更深入系统的数据阐明。但愿认识更多进修数据阐明的伴侣,接待留言,感激点赞。最后,路漫漫其修远兮,泛泛心!
接待插手本站果真乐趣群贸易智能与数据阐明群乐趣范畴包罗各类让数据发生代价的步伐,实际应用案例分享与接头,阐明东西,ETL东西,数据客栈,数据挖掘东西,报表系统等全方位常识QQ群:81035754
