selenium的安装及利用先容Selenium是一个用于测试网页应用的开源软件。它提供了欣赏器中的点击,转动,滑动,及文字输入等驱动措施。这样,操作Selenium即可以通过剧本措施来替代人工举办测试一个开拓软件的各类成果。
在处理惩罚爬虫任务中,常常碰着需要输入文字,举办下拉菜单选择,以及鼠标点击等情景。这个时候,selenium就派上大用场了。
下面,我们先先容一下Selenium的利用情况设置,接着先容如何通过R的拓展包Rwebdriver来利用Selenium,最后,展示一个爬虫案例应用。
安装设置安装jre:下载地点:http://www.Java.com/en/download/manual.jsp#win设置jre情况变量http://jingyan.baidu.com/article/09ea3ede2b5f86c0aede39b9.htmlhttp://blog.sciencenet.cn/blog-830496-778851.html下载selenium,并放至指定位置下载地点:http://www.seleniumhq.org/download/
启动selenium打开呼吁提示符进入selenium地址路径启动seleniumcd “C:\Program Files (x86)\Rwebdriver”java -jar selenium-server-standalone-2.49.0.jar
### selenium接口函数先容
『Automated Data Collection with R』一书的作者开拓了R包Rwebdriver,用于毗连启用selenium。
该R包重要的函数如下:
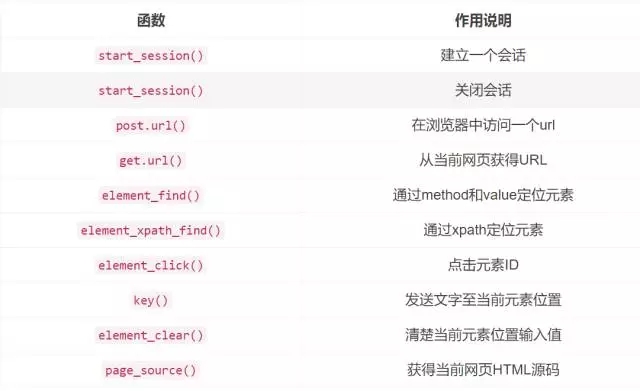
更多细节请参考:
-『Automated Data Collection with R』第9章P253-P259Selenium with Python http://selenium-python.readthedocs.io/
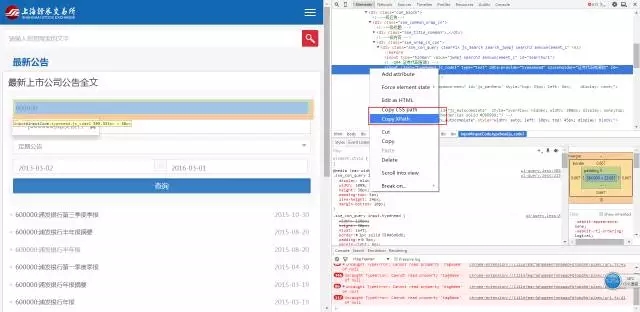
网页开拓东西的利用先容(手动演示)
XML提取器相关函数的利用
xpathSApply(doc,path,fun = NULL)可传入的fun如下:

案例演示——爬取上海证券生意业务所上市公司通告信息#### packages we need ###### ———————————————————————– ##require(stringr)require(XML)require(RCurl)library(Rwebdriver)
# set pathsetwd(“ListedCompanyAnnouncement”)# base urlBaseUrl<-“http://www.sse.com.cn/disclosure/listedinfo/announcement/”
#start a sessionquit_session()start_session(root = “http://localhost:4444/wd/hub/”,browser = “firefox”)
# post Base Urlpost.url(url = BaseUrl)
# get xpathStockCodeField<-element_xpath_find(value = ‘//*[@id=”inputCode”]’)ClassificationField<-element_xpath_find(value = ‘/html/body/div[7]/div[2]/div[2]/div[2]/div/div/div/div/div[2]/div[1]/div[3]/div/button’)StartDateField<-element_xpath_find(value = ‘//*[@id=”start_date”]’)EndDateField<-element_xpath_find(value = ‘//*[@id=”end_date”]’)SearchField<-element_xpath_find(value = ‘//*[@id=”btnQuery”]’)
# fill stock codeStockCode<-“600000”
element_click(StockCodeField)keys(StockCode)
Sys.sleep(2)
#fill classification field element_click(ClassificationField)
# get announcement xpathRegularAnnouncement<-element_xpath_find(value = ‘/html/body/div[7]/div[2]/div[2]/div[2]/div/div/div/div/div[2]/div[1]/div[3]/div/div/ul/li[2]’)Sys.sleep(2)element_click(RegularAnnouncement)
# #fill start and end date # element_click(StartDateField)
# today’s xpathEndToday<-element_xpath_find(value = ‘/html/body/div[13]/div[3]/table/tfoot/tr/th’)Sys.sleep(2)element_click(EndDateField)Sys.sleep(2)element_click(EndToday)
#click searchelement_click(SearchField)
#######################################得到所有文件的link ##all_links<-character()
#首页链接pageSource<-page_source()parsedSourcePage<-htmlParse(pageSource, encoding = ‘utf-8’)
pdf_links<-‘//*[@id=”panel-1″]/div[1]/dl/dd/em/a’
all_links<-c(all_links,xpathSApply(doc = parsedSourcePage,path = pdf_links, xmlGetAttr,”href”))
###############################遍历所有link,下载文件for(i in 1:length(all_links)){ Sys.sleep(1) if(!file.exists(paste0(“file/”,basename(all_links[i])))){ download.file(url = all_links[i],destfile = paste0(“file/”,basename(all_links[i])),mode = ‘wb’) }}
参考文献『Automated Data Collection with R』
黄耀鹏,统计硕士生,R User,喜欢汗青八卦。博客:http://yphuang.github.io/
接待插手本站果真乐趣群贸易智能与数据阐明群乐趣范畴包罗各类让数据发生代价的步伐,实际应用案例分享与接头,阐明东西,ETL东西,数据客栈,数据挖掘东西,报表系统等全方位常识QQ群:81035754
