
BUFN 650 – Problem Set 1
问题集代写 Important: Please submit your homework using Canvas. Your submission needs to in- clude two files: a PDF (or Word) document
Due on Tuesday, November 26 at 11:59 pm
Important: Please submit your homework using Canvas. Your submission needs to in- clude two files: a PDF (or Word) document with all your responses AND a copy of your Python notebook (.ipynb Jupyter notebook file). To produce the latter, please click File → Download .ipynb in Google Colab, then save and upload the file on Canvas.问题集代写
Each student has to submit his/her individual assignment and show all work. Legibly handwritten and scanned submissions are allowed, but they need to be submitted as a single document. Please do not submit photographs of pages in separate files.
到期时间为11月26日,星期二,晚上11:59
重要提示:请使用“画布”提交作业。您的提交需要包括两个文件:一个包含所有回复的PDF(或Word)文档,以及一个Python笔记本的副本(.ipynb Jupyter笔记本文件)。要生成后者,请单击文件→在Google Colab中下载.ipynb,然后在Canvas上保存并上传文件。
每个学生必须提交他/她的个人作业并展示所有作业。允许进行清晰的手写和扫描提交,但需要将它们作为单个文档提交。请不要在单独的文件中提交页面的照片。

Part I: Short-answer questions (80 points) 问题集代写
Please provide a concise answer for each of the questions below. Usually one or two short sentences should suffice. Do not write novels.
1.(12 points) For each of parts (a) through (d),
indicate whether we would generally expectthe performance of a flexible statistical learning method to be better or worse than an inflexible method. Justify your answer.问题集代写
(a)The sample size n is extremely large, and the number of predictors p is
(b)Thenumber of predictors p is extremely large, and the number of observations n is small.问题集代写
(c)The relationship between the predictors and response is highlynon-linear.
(d)The variance of the error terms, i.e. σ2= var(ε), is extremely
2.(9points) Explain whether each scenario is a classification or regression problem, 问题集代写
and indicate whether we are most interested in inference or Finally, provide n and p.
(a)We collect a set of data on the top 500 firms in the US. For each firm werecord profit, number of employees, industry and the CEO We are interested in understanding which factors affect CEO salary.
(b)Weare considering launching a new product and wish to know whether it will be a success or a We collect data on 20 similar products that were previously launched. For each product we have recorded whether it was a success or failure, price charged for the product, marketing budget, competition price, and ten other variables.问题集代写
(c)Weare interested in predicting the % change in the USD/Euro exchange rate in relation to the weekly changes in the world stock Hence we collect weekly data for all of 2019. For each week we record the % change in the USD/Euro, the % change in the US market, the % change in the British market, and the % change in the German market.
第一部分:简答题(80分)
请为以下每个问题提供简明的答案。通常,一两个简短的句子就足够了。不要写小说。
1.(12分)对于(a)到(d)的每个部分,表明我们通常期望灵活的统计学习方法的性能好于或不灵活的学习方法。证明你的答案。
(a)样本量n非常大,预测变量p的数量很少。
(b)预测变量的数量p非常大,观测值的数量n
是小。
(c)预测变量与响应之间的关系是高度非线性的。
(d)误差项的方差即σ2= var(ε)非常大。
2.(9分)说明每种情况是分类问题还是回归问题,并指出我们对推理还是预测最感兴趣。最后,提供n和p。
(a)我们收集了有关美国前500家公司的一组数据。我们为每家公司记录利润,员工人数,行业和首席执行官薪水。我们有兴趣了解哪些因素会影响首席执行官的薪水。
(b)我们正在考虑推出新产品,并希望知道它是成功还是失败。我们收集了先前发布的20种类似产品的数据。对于每种产品,我们都记录了它是成功还是失败,产品收取的价格,营销预算,竞争价格以及其他十个变量。
(c)我们有兴趣预测美元/欧元汇率相对于世界股票市场每周变化的百分比变化。因此,我们收集了2019年全年的每周数据。每周记录美元/欧元的变化百分比,美国市场的变化百分比,英国市场的变化百分比和德国市场的变化百分比。
3.(12points) I collect a set of data (n = 100 observations) containing a single predictor
and a quantitative I then fit a linear regression model to the data, as well as a separate cubic regression, i.e.,问题集代写
Y = β0 + β1X + β2X2 + β3X3 + s.
(a)Supposethat the true relationship between X and Y is linear, e.
Y = β0 + β1X + s.
Consider the training residual sum of squares (RSS) for the linear regression, and also the training RSS for the cubic regression. Would we expect one to be lower than the other, would we expect them to be the same, or is there not enough information to tell? Justify your answer.
(b)Answer(a) using test rather than training 问题集代写
(c)Suppose that the true relationship between X and Y is not linear, but we don’t knowhow far it is from Consider the training RSS for the linear regression, and also the training RSS for the cubic regression. Would we expect one to be lower than the other, would we expect them to be the same, or is there not enough information to tell? Justify your answer.
(d)Answer(c) using test rather than training
3.(12分)我收集了一组数据(n = 100个观察值),其中包含一个预测变量和一个定量响应。然后,我将线性回归模型拟合到数据,以及单独的三次回归,即
Y =β0+β1X+β2X2+β3X3+ s。
(a)假设X和Y之间的真实关系是线性的,即
Y =β0+β1X+ s。
考虑线性回归的训练残差平方和(RSS),以及三次回归的训练RSS。我们是否期望一个比另一个更低,或者我们希望它们相同,或者没有足够的信息可以告诉我们?证明你的答案。
(b)回答(a)使用测试而不是训练RSS。
(c)假设X和Y之间的真实关系不是线性的,但我们不知道它与线性的距离有多远。考虑针对线性回归的训练RSS,以及针对三次回归的训练RSS。我们是否期望一个比另一个更低,或者我们希望它们相同,或者没有足够的信息可以告诉我们?证明你的答案。
(d)回答(c)使用测试而不是训练RSS。
4.(6 points) Consider the k-foldcross-validation.问题集代写
(a)Briefly explain how k-fold cross-validation is
(b)Whatare the advantages and disadvantages of k-fold cross-validation relative to the validation set approach?问题集代写
5.(3points) Suppose that we use some statistical learning method to make a prediction for the response Y for a particular value of the predictor X. Carefully describe how we might estimate the standard deviation of our
6.(11points) We perform best subset,
forward stepwise, and backward stepwise selection on a single data For each approach, we obtain p + 1 models, containing 0, 1, 2, …, p predictors. Explain your answers:问题集代写
(a)Which of the three models with k predictors has the smallest trainingRSS?
(b)Whichof the three models with k predictors has the smallest test RSS?
(c)True or False (no explanation necessary; 1 pointeach):
i.Thepredictors in the k-variable model identified by forward stepwise are a subset of the predictors in the (k + 1)-variable model identified by forward stepwise
ii.Thepredictors in the k-variable model identified by backward stepwise are a subset of the predictors in the (k + 1)-variable model identified by backward stepwise 问题集代写
iii.Thepredictors in the k-variable model identified by backward stepwise are a subset of the predictors in the (k + 1)-variable model identified by forward stepwise
iv.Thepredictors in the k-variable model identified by forward stepwise are a subset of the predictors in the (k + 1)-variable model identified by backward stepwise
v.Thepredictors in the k-variable model identified by best subset are a subset of the predictors in the (k +1)-variable model identified by best subset
4.(6分)考虑k倍交叉验证。
简要说明如何执行k折交叉验证。
(b)与验证集方法相比,k折交叉验证有哪些优缺点?
5.(3分)假设我们使用某种统计学习方法对预测变量X的特定值对响应Y进行预测。仔细描述我们如何估计预测的标准偏差。
6.(11分)我们在单个数据集上执行最佳子集,向前逐步选择和向后逐步选择。对于每种方法,我们获得p + 1个模型,其中包含0、1、2,…,p个预测变量。说明您的答案:
(a)在三个预测因子为k的模型中,哪个模型的RSS最小?
(b)在三个预测因子为k的模型中,哪个模型的RSS最小?
(c)是非题(无需解释;各1分):
i。通过逐步逐步确定的k变量模型中的预测变量是通过逐步逐步选择确定的(k +1)变量模型中的预测变量的子集。
ii。通过向后逐步选择确定的k变量模型中的预测变量是通过向后逐步选择确定的(k +1)变量模型中的预测变量的子集。
iii。后向逐步确定的k变量模型中的预测变量是前向逐步选择确定的(k +1)变量模型中的预测变量的子集。
iv。k变量中的预测变量由正向逐步选择确定的模型是(k + 1)变量模型中由向后逐步选择确定的预测子的子集。
v。由最佳子集标识的k变量模型中的预测变量是由最佳子集选择标识的(k +1)变量模型中的预测变量的子集
7.(12points) The lasso, relative to least squares, is:问题集代写
(a)Moreflexible and hence will give improved prediction accuracy when its increase in bias is less than its decrease in
(b)Moreflexible and hence will give improved prediction accuracy when its increase in variance is less than its decrease in 问题集代写
(c)Lessflexible and hence will give improved prediction accuracy when its increase in bias is less than its decrease in
(d)Lessflexible and hence will give improved prediction accuracy when its increase in variance is less than its decrease in
8.(15 points) Suppose we estimate the regression coefficients in a linear regression model byminimizing
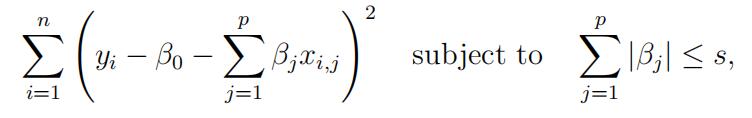
for a particular value of s. For parts (a) through (e), indicate which of i. through v. is correct. Justify your answer.
(a)As we increase s from 0, the training RSSwill:
i.Increaseinitially, and then eventually start decreasing in an inverted U 问题集代写
ii.Decrease initially, and then eventually start increasing in a U
iii.Steadily
iv.Steadily
v.Remain
(b)Repeat (a) for test
(c)Repeat (a) for
(d)Repeat (a) for (squared)
(e)Repeat (a) for the irreducible
7.(12分)相对于最小二乘,套索为:
(a)更灵活,因此,当其偏差的增加小于其方差的减小时,将提供改进的预测精度。
(b)更灵活,因此当方差的增加小于偏差的减少时,预测精度将得到改善。
(c)灵活性较差,因此当其偏差的增加小于其方差的减小时,将提供改进的预测精度。
(d)灵活性较差,因此当方差的增加量小于偏差的减少量时,将提供更好的预测精度。
8.(15分)假设我们通过最小化来估计线性回归模型中的回归系数
Part II: Predict the number of applications received by colleges (120 points)问题集代写
This exercise relates to the College data set, which can be found in the file College. It contains a number of variables for 777 different universities and colleges in the US. The variables are
- Private: Public/privateindicator
- Apps:Number of applications received
- Accept: Number of applicantsaccepted
- Enroll: Number of new students enrolled
- Top10perc: New students from top10
- Top25perc: New students from top25
- Undergrad: Number of full-timeundergraduates
- Undergrad: Number of part-timeundergraduates 问题集代写
- Outstate: Out-of-statetuition
- Board: Room and boardcosts
- Books: Estimated bookcosts
- Personal: Estimated personalspending
- PhD: Percent of faculty withD.s
- Terminal: Percent of faculty with terminaldegree
- F.Ratio: Student/facultyratio
- alumni: Percent of alumni whodonate
- Expend: Instructional expenditure perstudent
- Rate: Graduationrate
Before reading the data into Python, it can be viewed in Excel or a text editor.
第二部分:预测大学收到的申请数量(120分)
此练习与College数据集有关,可以在文件College中找到该数据集。它包含美国777所不同大学的许多变量。变量是
•私人:公共/私人指示器
•应用程序:收到的应用程序数量
•接受:被录取的申请人数
•入学人数:新入学人数
•Top10perc:来自前10名的新生
•Top25perc:排名前25位的新生
•F.Undergrad:全日制本科生人数
•P.Undergrad:非全日制本科生人数
•州外:州外学费
•Room.Board:食宿费用
•书籍:估计书籍费用
•个人:估计个人支出
•博士学位:拥有博士学位的教师比例
•终端:具有最终学位的教师比例
•S.F。比率:师生比例
•perc.alumni:捐赠的校友百分比
•支出:每位学生的教学支出
•Grad.Rate:毕业率
在将数据读入Python之前,可以在Excel或文本编辑器中对其进行查看。
1.(20 points) Exploring thedata:问题集代写
(a)Use the read csv(’http://faculty.marshall.usc.edu/gareth-james/ISL/College.csv’)function to read the data into Python. Call the loaded data college. Look at the data using the college.head() function. You should notice that the first column
is just the name of each university. We don’t really want Python to treat this as data. However, it may be handy to have these names for later. Set is as an index by passing an index col=0 parameter to the read csv() call above. Alternatively, you may use the college.set index() command. In the future, you can extract college names using college.index.问题集代写
(b)Usethe describe() function to produce a numerical summary of the vari- ables in the data set.
(c)Import the seaborn package and alias it as sns. Use the pairplot() function toproduce a scatterplot matrix of the first five columns or variables of the data. Recall that you can reference the first five columns using college.iloc[,:5].
(d)Use the boxplot(x=college[’Private’], y=college[’Outstate’]) function to pro- duceside-by-side boxplots of Outstate versus Private (two plots side-by-side; one for each Yes/No value of Private).问题集代写
(e)Createa new qualitative variable, called Elite, by binning the Top10perc We are going to divide universities into two groups based on whether or not the proportion of students coming from the top 10% of their high school classes exceeds 50%.
Use the sum() function to see how many elite universities there are. Now use the
sns.boxplot() function to produce side-by-side boxplots of Outstate versus Elite. (f) Use the college.hist() function to produce some histograms for a few of the quan-
titative variables. You may find parameters bins=20,figsize=(15,10) useful.问题集代写
(g) Continue exploring the data, and provide a brief summary of what you discover.
1.(20分)探索数据:
(a)使用pd.read csv(’http://faculty.marshall.usc.edu/gareth-james/ISL/College.csv’)函数将数据读取到Python中。致电加载的数据学院。使用college.head()函数查看数据。您应该注意到第一列
只是每所大学的名字。我们真的不希望Python将其视为数据。但是,稍后使用这些名称可能会很方便。通过将index col = 0参数传递到上面的read csv()调用,将Set用作索引。或者,您可以使用college.set index()命令。将来,您可以使用college.index提取大学名称。
(b)使用college.describe()函数生成数据集中变量的数字摘要。
(c)导入seaborn软件包并将其别名为sns。使用sns.pairplot()函数生成前五列或数据变量的散点图矩阵。回想一下,您可以使用college.iloc [,:5]引用前五列。
(d)使用sns.boxplot(x = college [‘Private’],y = college [‘Outstate’])函数来制作Outstate与Private的并排箱线图(两个并排图;每个“专用”的“是/否”值各一个)。
(e)通过对Top10perc变量进行装箱,创建一个名为Elite的新定性变量。我们将根据高中班级排名前10%的学生所占比例是否超过50%,将大学分为两组。
使用sum()函数可以查看有多少所精英大学。现在使用
sns.boxplot()函数可生成Outstate与Elite的并排Boxplot。 (f)使用college.hist()函数生成一些直方图,
称谓变量。您可能会发现bins = 20,figsize =(15,10)参数很有用。
(g)继续探索数据,并提供您发现的简短摘要。
2.(100 points) Now, let’s predict the number of applications received (variable Apps) using the other variables in the College dataset:问题集代写
(a)(5points) Replace any text variables with numeric You may use
pd.get dummies(college, drop first=True) to achieve this.
(b)(5 points) Construct response y (Apps) and predictors X (the rest of variables). You are worried that non-linearities in X could be important and decide toadd
all second-order terms to your predictors (i.e., x1, x2, x1x2, x2, x2 etc.). Add these
terms to your X. Hint: you can use PolynomialFeatures().fit transform(X) func- tion from sklearn.preprocessing package. If you did everything correctly, the set of variables in X should now be expanded from 18 to 190 features (all second-order terms, including interactions and a vector of ones).
(c)(5 points) Split the data set into a training set and a test set. Never use the test setfor anything but reporting the test error when asked
(d)(5 points) Standardize all explanatory variables (subtract their time-series means and divide by standard deviation). Verify that all variables now have zeromean and unitary standard 问题集代写
(e)(10 points) Fit a linear model using least squares on the training set, and report the test error obtained. Warning: if you used PolynomialFeatures().fit transform(X) anda vector of ones was added to predictors, set fit intercept=False.
(f)(15 points) Fit a ridge regression model on the training set, with λ chosen by cross-validation. Cross-validation should be performed using only the training set portionof the data in (a). Plot cross-validated MSE as a function of λ. Plot paths of coefficients as a function of λ. Report the test error obtained. Hint: I showed how to perform many of these steps in class in the Chapter 6.ipynb
(g)(15points) Repeat (f) using lasso
You will likely receive convergence warnings or experience slowness. Use the original characteristics (with no second- order terms) if you do. Report the number of non-zero coefficients.
(h)(15points) Repeat (f) using random Recall that random forests and regres- sion trees allow for interactions and non-linearities in X by design. Therefore, use the original set of characteristics here (with no second-order terms). Experiment with the max depth parameter.问题集代写
(i)(15 points) Fit an elastic net model on the training set, with λ chosen by cross- validation.Use the original Report the test error obtained. Hint: Use ElasticNetCV() estimator from sklearn.linear model to cross-validate and fit a model. You can read more here. Elastic net needs to cross-validate two param- eters. You can do this automatically by adding l1 ratio=np.linspace(.05, 1, 20) as a parameter.
(j)(10points) Comment on the results How accurately can we predict the number of college applications received? Is there much difference among the test errors resulting from these five approaches?
2.(100分)现在,让我们使用College数据集中的其他变量来预测收到的申请数(变量Apps):
(a)(5分)用数字虚拟变量替换所有文本变量。您可以使用
pd.get假人(学院,首先掉落= True)来实现这一目标。
(b)(5分)构造响应y(应用程序)和预测变量X(其余变量)。您担心X中的非线性可能很重要,因此决定添加
预测变量的所有二阶项(即x1,x2,x1x2,x2,x2等)。添加这些
1 2
提示:可以使用sklearn.preprocessing包中的PolynomialFeatures()。fit transform(X)函数。如果您正确完成了所有操作,则X中的变量集现在应该从18个要素扩展到190个要素(所有二阶项,包括交互作用和矢量的项)。
(c)(5分)将数据集分为训练集和测试集。除非在以下要求时报告测试错误,否则切勿将测试仪用于任何其他用途。
(d)(5分)标准化所有解释变量(减去它们的时间序列平均值并除以标准差)。验证所有变量现在均具有零均值和单一标准偏差。
(e)(10分)在训练集上使用最小二乘法拟合线性模型,并报告获得的测试误差。警告:如果您使用了PolynomialFeatures()。fit transform(X),并且向预测变量添加了1的向量,请设置fit拦截= False。
(f)(15分)在训练集上拟合岭回归模型,并通过交叉验证选择λ。交叉验证应仅使用(a)中数据的训练集部分进行。绘制交叉验证的MSE作为λ的函数。绘制作为λ的函数的系数的路径。报告获得的测试错误。提示:我在第6章ipynb笔记本中展示了如何在课堂上执行许多这些步骤。
(g)(15分)使用套索回归法重复(f)。您可能会收到收敛警告或运行缓慢。如果这样做,请使用原始特征(无二阶条件)。报告非零系数的数量。
(h)(15分)使用随机森林重复(f)。回想一下,通过设计,随机森林和回归树允许X中的交互作用和非线性。因此,请在此处使用原始特征集(不包含二阶项)。试验最大深度参数。
(i)(15分)在训练集上拟合一个弹性网模型,通过交叉验证选择λ。使用原始特征。报告获得的测试错误。提示:使用sklearn.linear模型中的ElasticNetCV()估计器对模型进行交叉验证和拟合。你可以在这里阅读更多。弹性网需要交叉验证两个参数。您可以通过添加l1 ratio = np.linspace(.05,1,20)作为参数来自动执行此操作。
(j)(10分)评论所获得的结果。我们如何准确地预测收到的大学申请数量?这五种方法导致的测试错误之间有很大差异吗?

其他代写:web代写 program代写 cs作业代写 analysis代写 app代写 essay代写 assembly代写 Haskell代写 homework代写 Programming代写 Task代写 考试助攻 web代写 finance代写 Exercise代写
