下面主要写了数据结构「十种排序算法」,有需要的小伙伴,可以参考一下。文章有有图有真相,你一定可以学会的。课课家教育平台提醒各位:本篇文章纯干货~因此大家一定要认真阅读本篇文章哦!
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
堆排序、快速排序、希尔排序、直接选择排序不是稳定的排序算法,而基数排序、冒泡排序、直接插入排序、折半插入排序、链表插入排序、归并排序是稳定的排序算法。
直接插入排序 T(n) = O(n^2)
直接插入排序「Insertion Sort」的基本思想是:每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子序列中的适当位置,直到全部记录插入完成为止。
设数组为a[0…n-1]:
初始时,a[0]自成1个有序区,无序区为a[1..n-1]。令i=1。
将a[i]并入当前的有序区a[0…i-1]中形成a[0…i]的有序区间。
i++并重复第二步直到i==n-1。排序完成。
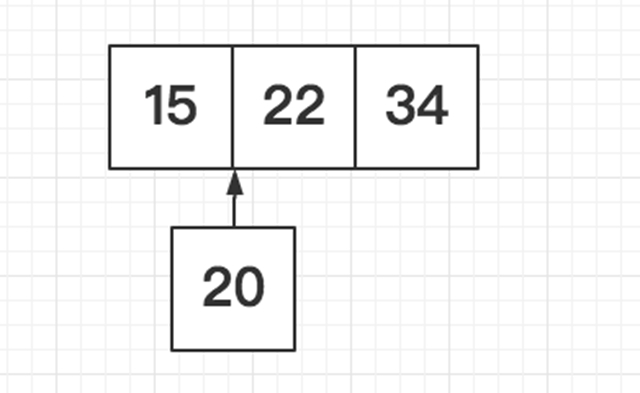
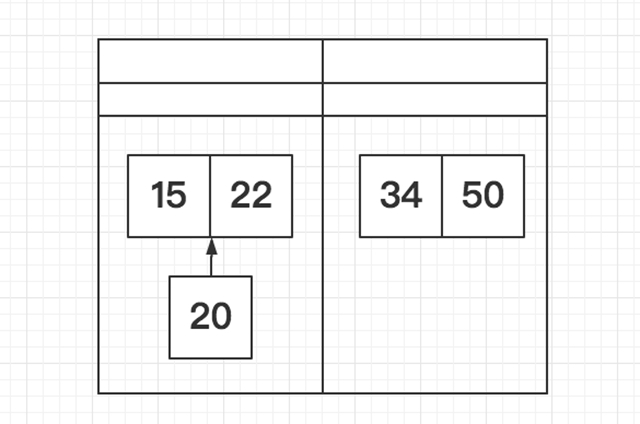
折半插入排序 T(n) = O(n^2)
折半插入排序是对直接插入排序的简单改进,对于折半插入排序而言,当需要插入第i个元素时,它不会逐个进行比较每个元素,而是:
计算0~i-1索引的中间点,也就是用i索引处的元素和(0+i-1)/2索引处的元素进行比较,如果i索引处的元素值大,就直接在(0+i-1)/2~i-1半个范围内进行搜索;反之在0~(0+i-1)/2半个范围内搜索,这就是所谓的折半
在半个范围内搜索时,按照1的方法不断地进行折半搜索,这样就可以将搜索范围缩小到1/2、1/4、1/8…,从而快速的确定插入位置
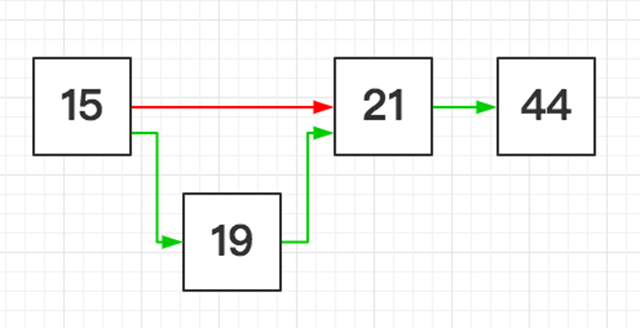
链表插入排序 T(n) = O(n^2)
链表插入排序的基本思想是:假设前 n-1个节点有序,取最后节点,沿链表依次查找比较,直到合适位置,修改「本节点」和「待插入节点」的指针。
沿头节点遍历链表,比较此节点、待插入节点、后继节点的大小关系,直到:此节点 < 待插入节点 < 后继节点。
令「此节点」指向「待插入节点」,「待插入节点」指向「后继节点」。
Shell 排序(希尔排序) T(n) = O(n^1.5)
数据结构的运算
重要意义
一般认为,一个数据结构是由数据元素依据某种逻辑联系组织起来的。对数据元素间逻辑关系的描述称为数据的逻辑结构;数据必须在计算机内存储,数据的存储结构是数据结构的实现形式,是其在计算机内的表示;此外讨论一个数据结构必须同时讨论在该类数据上执行的运算才有意义。一个逻辑数据结构可以有多种存储结构,且各种存储结构影响数据处理的效率。在许多类型的程序的设计中,数据结构的选择是一个基本的设计考虑因素。许多大型系统的构造经验表明,系统实现的困难程度和系统构造的质量都严重的依赖于是否选择了最优的数据结构。许多时候,确定了数据结构后,算法就容易得到了。有些时候事情也会反过来,我们根据特定算法来选择数据结构与之适应。不论哪种情况,选择合适的数据结构都是非常重要的。选择了数据结构,算法也随之确定,是数据而不是算法是系统构造的关键因素。这种洞见导致了许多种软件设计方法和程序设计语言的出现,面向对象的程序设计语言就是其中之一。
希尔排序的实质就是分组插入排序,该方法又称缩小增量排序。该方法的基本思想是:
先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序
然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小,1)时,再对全体元素进行一次直接插入排序
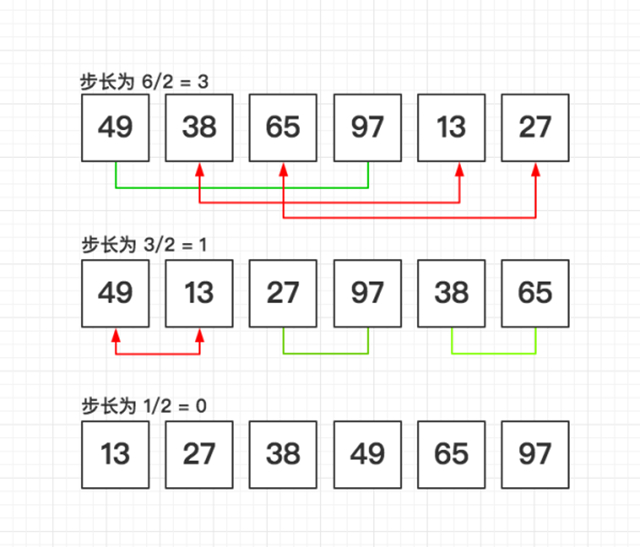
冒泡排序 T(n) = O(n^2)
#p#分页标题#e#
冒泡排序的基本思想是,对相邻的元素进行两两比较,顺序相反则进行交换,这样,每一趟会将最小或最大的元素“浮”到顶端,最终达到完全有序。
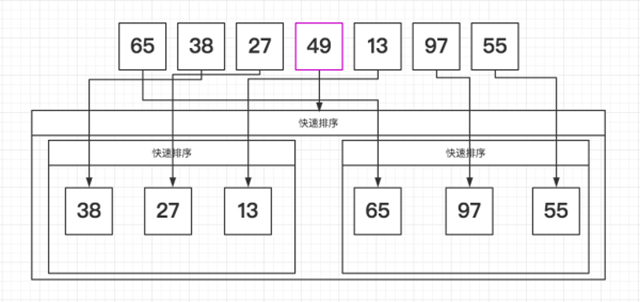
快速排序 范围T(n) = O(n*lg n) ~ O(n^2) | 平均T(n) = O(n*lg n)
快速排序采用了分治(递归)的方法,该方法的基本思想是:
先从数列中取出一个数作为基准数
分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边
再对左右区间重复第二步,直到各区间只有一个数
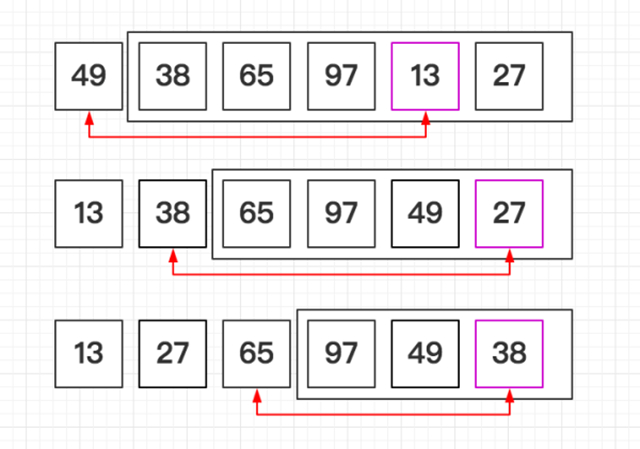
直接选择排序 T(n) = O(n^2)
直接选择排序(Straight Select Sorting) 也是一种简单的排序方法,它的基本思想是:
从R[0]~R[n-1]中选取最小值,与R[0]交换
从R{1}~R[n-1]中选取最小值,与R[1]交换
第i次从R[i-1]~R[n-1]中选取最小值,与R[i-1]交换
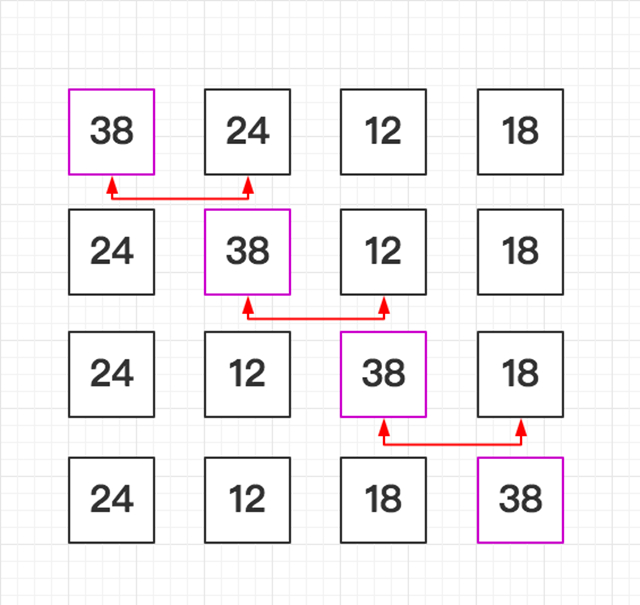
堆选择排序 T(n) = O(n*log2n)
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。堆分为大根堆和小根堆,下图为小根堆:
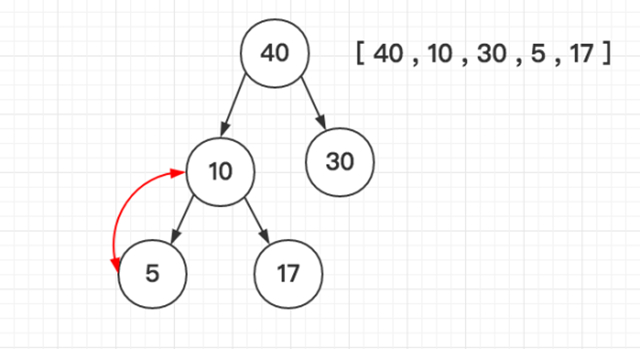
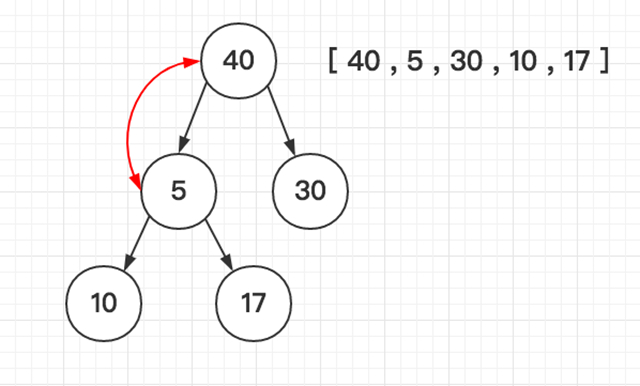
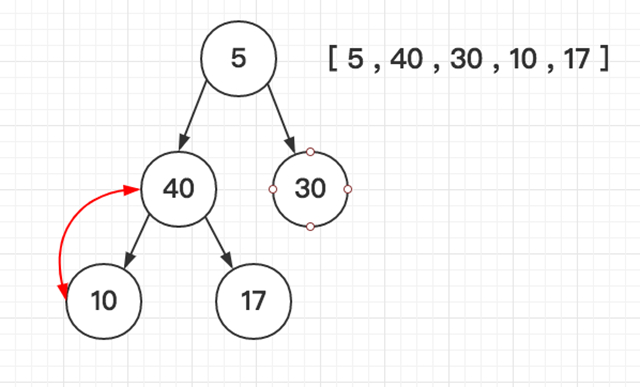
「如图所示依次类推」
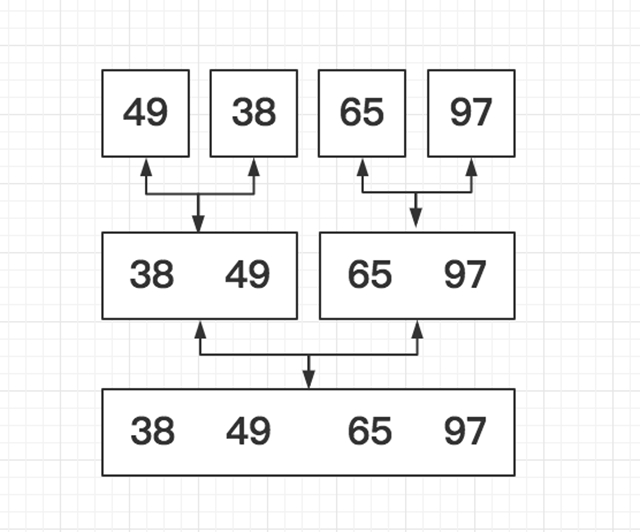
归并排序 T(n) = O(n*log2n)
归并排序是建立在归并操作上的一种有效的排序算法,采用了分治思想。如下图的二路归并:
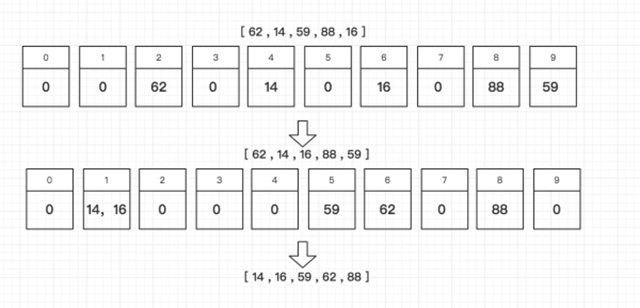
基数排序
基数排序(radix sort)属于「分配式排序」,有点类似 「桶排」。
分配10个桶,桶编号为0-9,以个位数数字为桶编号依次入桶,将桶里的数字顺序取出来
再次入桶,不过这次以十位数的数字为准,进入相应的桶,同一桶内有序
再次取出,排序完成