ECON 4403
线性代数代写 Calculate the mean and variance and correlation. Are these close to their theoreticalvalues? Are these values change as you adjust rho .
Winter 2019
Assignment 3
It’s due on February 28 (midnight) by email. You can submit it individually or as a team (maximum 3 members).线性代数代写
- You can onlyuse linear algebra. You cannot use any function or command (ex- cept for var(), mean() ) from relevant libraries in the software that you use in your estimations (i.e. lm() in R is NOT allowed)
- You can only use R, Python, C++, or NotStata!
- What you submit must be your own
- I need ONLY your rmd file (or the source code in C++), nothingelse!
- The solutions will be provided later only for R andC++.

This assignment has 3 parts:线性代数代写
- BigAndy: OLS estimations, F-tests, Hypothesis Testing, linear restrictions, Confi- dence
- California Test Scores:
- Simulation with corelated errors following an AR(1)
Sources: Your ECON 3303 notes and the relevant sections in the textbook. The data for part A is on Brightspace. The following link will give you information you need in Part
- http://rpubs.com/wsundstrom/home.The data file and instruction on the file that we use in Section B can be found on this webpage.
A. Big Andy’s Burger Chain 线性代数代写
Big Andy is a burger chain. The management would like to make some changes in their current marketing policy. But before implementing it, they need to make sure that their new strategy would work. They usually spend more in advertisement to increase their revenue. Now, they would like to use their pricing, instead. First, they want to know the price elasticity of their sales. For example, if they reduce their price by $0.40 per burger how would their revenue be affected? If the price elasticity would allow, they would like to cut their advertisement expenses by $0.8 thousand per chain. If they do it with the price reduction, would their revenue still rise? The management has collected data, (andy.csv – sales($000) and advert($000)), and you are in charge of analyzing it!
- 1.Estimate the model:
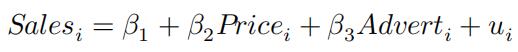
线性代数代写 (again, do not use lm()).
- Findthe price and advertisement elasticities by transforming the model (do not calculate them manually). Why these elasticities are different than the one when sales is 71 and price is $5 (now you can calculate them manually)?
- Whatis the optimal price for Andy Burger to maximize the revenue? What’s the total sales at this price. What’s the price elasticity at this revenue maximizing price?
- What are the confidence intervals for both elasticities? Are the elasticities statisti- cally significant? Test if the elasticity of sales in terms of advertisement is less than2.
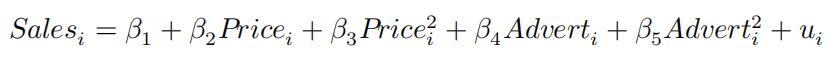 Would you go with , in-
Would you go with , in-
stead? Is it better than the restricted model in (1)? Explain.linear algebra1代写
- Usethe updated second model to suggest an optimal (Each dollar spent on ads should create at least $1 sales)
- Now we will test the policy suggested earlier. But first, calculate the totalchange
in sales if price goes down 0.4 cents and advert goes up 0.8 thousand dollars. Use
the estimates of the restricted model in (1).

B. California Test Scores
Please read the “claiforniatestscores.docx” to understand the data. You will build and run your own model that predicts “educational achievements” and its determinants among 5th grade students. This educational outcome can be defined many different ways but for this dataset we can use test scores (pick one or use an average test score). A simpler model is always better. The model that you will build should make sense so thateach explanatory variable should be justified as to why you have to include each of them in your model.线性代数代写
- Build your model and give a short explanation how your model(s) is justified. In building a model, we usually start with a couple of alternative models. Similar to the models in Part A, these alternatives are defined by “extended” and “nested” models,or type of functions1. Explain your reasoning why you have 2-3 models and why you rank them 1st, 2nd, and 3rd “best” (if you have). You need mathematical expressions of each model with a proper notation. Search Google to see how you insert math equations into
- Estimateyour 1st (unrestricted) and 2nd (restricted) models with linear algebra and lm() separately. Check if the results are the same. Interpret the results. Which model seems to have a better explanatory power? (Look at R2, apply an F-test)
- Now you are going to examine most influential factors in achieving higher test scores.Normalized your variables and estimate “Beta” coefficients. Interpret the results.线性代数代写
- Nowwe are going to test the multicollinearity in your Before running some diagnostics, do you have any sign of multicollinearity in your estimations?
- Rememberwe talked about “simple (or gross) correlation” “higher-order partial correlation coefficients”. Now read Section 6.5 (5th ed. Poor Data, Collinearity, and Insignificance) in your textbook (or other books).
Steps:
- We will first calculate VCM(X), which is a (k x k) and symmetric matrix. Howwould you get VCM(X)? Compare it with the results obtained from cov(X) in R. (Note that VCM(X) reports only variance-covariances)
- Manually calculate a partial correlation with X2 and X3 by running an “auxiliaryregression” (see the textbook and your notes) holding other Xs fixed.
- Nowuse a package (search Google about “partial correlation in R”. Here is a simple instruction https://youtube.com/watch?v=8Mxg_eDPCCA
1 , Remember from ECON 3303, these are called lin- lin, lin-log, log-lin, and log-log. Moreover, the model could be nonlinear in variables and you may need to add nonlinear extensions to the function (x and x2, for example).线性代数代写
and this https://rdrr.io/cran/corpcor/man/cor2pcor.html) to calculate cor- relation matrix from VCM(X). Compare the partial and simple correlations between X2 and X3.
- Now calculate VIFs for your model. Google again to find a package to run it. The VIF of X2 with multiple Xs is the R2 of this auxiliary regression. Check if the R2you calculated in 5(b) is close to the VIF? Check if high VIFs are related to higher VCM(betahat).
- Finally,adjust your model, for those with high VIFs and see you can find
C. Simulation with correlated errors following an AR(1) scheme 线性代数代写
We will create 5000 samples with our DGM defined in below. Each of these sam- ples will have 500 observations. In this assignment we have fixed (non-stochastic) x’s. Therefore, we will create x’s out of the loop to fix their values for repeated samples and then we use DGM to create y’s within a loop for each sample.
DGM
1.Createa vector of 1000 1’s and assign it to x1.
2.Createa vector with 1000 random integers between 0 and 100 and assign it to x2.
3.Createa vector with 1000 random 0s and 1s and assign it to
4.Createa vector with 1000 random numbers drawn from a uniform distribution min=1, max=50, and assign it to x4
5.Createa vector with 1000 random numbers drawn from a normal distribution (mean = 2, sd = 1.25) and assign it to x5.线性代数代写
6.Create a coefficient vector with your choice of For example, beta = (12, -0.7, 34, -0.17, 5.4).
7.For the followingDGM,
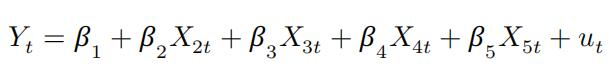
you need to have a vector of 1000 random “errors” drawn from a “Gaussian” distribution (Call it � . The errors in this model follow AR(1), Here is the loop (inside the sampling loop) for this in R:
u <- rep(rnorm(1,0,1), n)
for(j in 1:(n-1)){u[j+1] <- u[j]*rho + rnorm(1,0,1)}
If you have a better line of code, let us know!
- Run it only for one sample (you can increase or decrease the samplesize)
a.Plot it with different rho’s and see the difference when rho is 1.linear algebra1代写
b.Calculate the mean and variance and correlation. Are these close to their theoreticalvalues? Are these values change as you adjust rho and/or sam- ple size?
MC Simulation. 线性代数代写
- Create5000 samples (with 500 observations) with your DGM and make sure that your x’s are identical in each of 5000 You will have five sampling distri- butions each of which is for one estimator in beta_hat. Calculate the mean of each of these sampling distributions. Compare them with the population parame-ters. Are they similar as we expect? That is if ?
- Create VCM_uMC (see A2, if you need). Does it looklike
![]()
3.Create VCM_beta_AR1 with VCM_uMC. This gives us “true” variances of
betahats.线性代数代写
4.Now we will ignore AR(1) and estimate it by /span>2I. Calculate /span>2 from the last sample (Sample 5000 – uhat vector in the loop already contains these values, you don’t have to run it anything). With this fifind VCM_betahat_OLS. Are they difffferent than VCM_beta_AR1?
This is not the end of “Autocorrelation”. We’ll test it and see possible solutions next time!

其他代写:java代写 function代写 web代写 编程代写 数学代写 algorithm代写 python代写 java代写 project代写 dataset代写 analysis代写 C++代写 代写CS 金融经济统计代写 essay代写 assembly代写 program代写 作业加急 金融经济统计代写
