假如你手上有一批数据,你大概应用统计学、挖掘算法、可视化要领等技能玩转你的数据,但你没有数据的时候,该怎么玩呢?接下来就带着各人玩玩没有数据环境下的数据阐明。
本文从如下几个目次具体讲授数据阐明的流程:1、数据源的获取;2、数据摸索与清洗;3、模子构建(聚类算法和线性回归);4、模子预测;5、模子评估;
一、数据源的获取正如本文的题目一样,我要阐明的是上海二手房数据,我想看看哪些因素会影响房价?哪些房源可以归为一类?我该如何预测二手房的价值?可我手上没有这样的数据样本,我该如何答复上面的问题呢?
互联网时代,网络信息那么发家,信息量那么复杂,随便找点数据就够喝一壶了。前几期我们已经讲过了如何从互联网中抓取信息,回收Python这个机动而便捷的东西完成爬虫,譬喻:通过Python抓取天猫评论数据利用Python实现豆瓣阅念书籍信息的获取利用Python爬取网页图片
虽然,上海二手房的数据仍然是通过爬虫获取的,爬取的平台来自于链家,页面是这样的: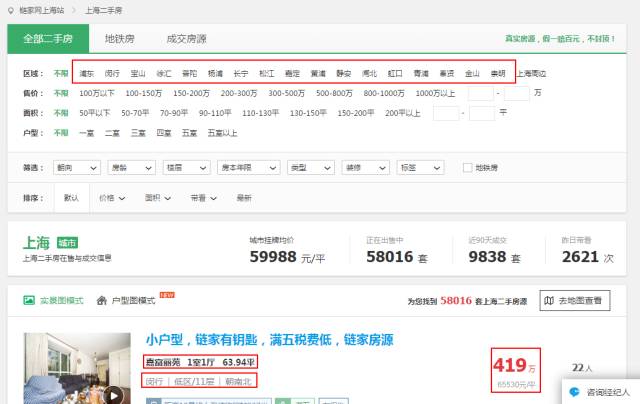
我所需要抓取下来的数据就是红框中的内容,即上海各个区域下每套二手房的小区名称、户型、面积、所属区域、楼层、朝向、售价及单价。先截几张Python爬虫的代码,源代码和数据阐明代码写在文后的链接中,如需下载可以到指定的百度云盘链接中下载。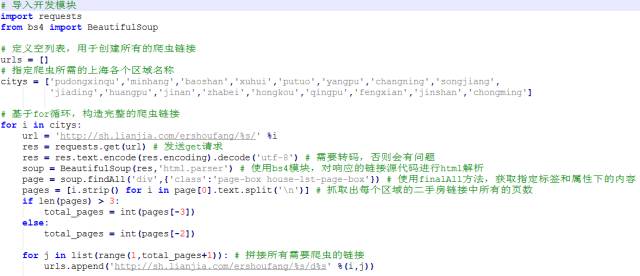
上面图中的代码是结构所有需要爬虫的链接。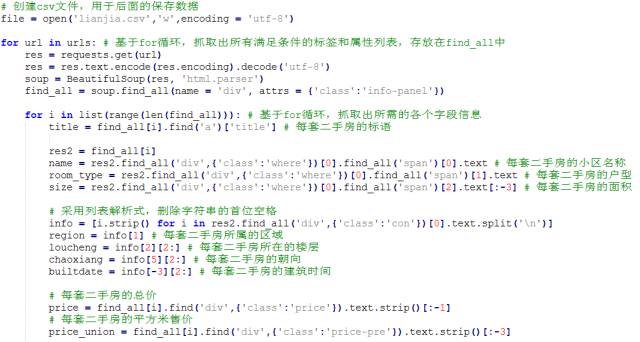
上面图中的代码是爬取指定字段的内容。
趴下来的数据是长这样的(总共28000多套二手房):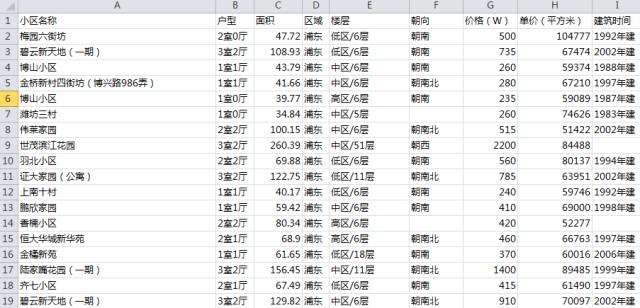
二、数据摸索与清洗(一下均以R语言实现)
当数据抓下来后,凭据老例,需要对数据做一个摸索性阐明,即相识我的数据都长成什么样子。
1、户型漫衍
# 户型漫衍library(ggplot2)type_freq <- data.frame(table(house$户型))# 画图type_p <- ggplot(data = type_freq, mapping = aes(x = reorder(Var1, -Freq),y = Freq)) + geom_bar(stat = ‘identity’, fill = ‘steelblue’) + theme(axis.text.x = element_text(angle = 30, vjust = 0.5)) + xlab(‘户型’) + ylab(‘套数’)
type_p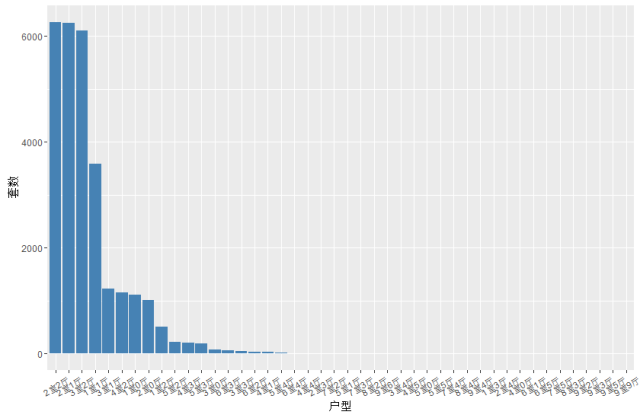
我们发明只有少数几种的户型数量较量多,其余的都很是少,明明属于长尾漫衍范例(严重偏态),所以,思量将1000套一下的户型统统归为一类。
# 把低于一千套的房型配置为其他type <- c(‘2室2厅’,’2室1厅’,’3室2厅’,’1室1厅’,’3室1厅’,’4室2厅’,’1室0厅’,’2室0厅’)house$type.new <- ifelse(house$户型 %in% type, house$户型,’其他’)type_freq <- data.frame(table(house$type.new))# 画图type_p <- ggplot(data = type_freq, mapping = aes(x = reorder(Var1, -Freq),y = Freq)) + geom_bar(stat = ‘identity’, fill = ‘steelblue’) + theme(axis.text.x = element_text(angle = 30, vjust = 0.5)) + xlab(‘户型’) + ylab(‘套数’)
type_p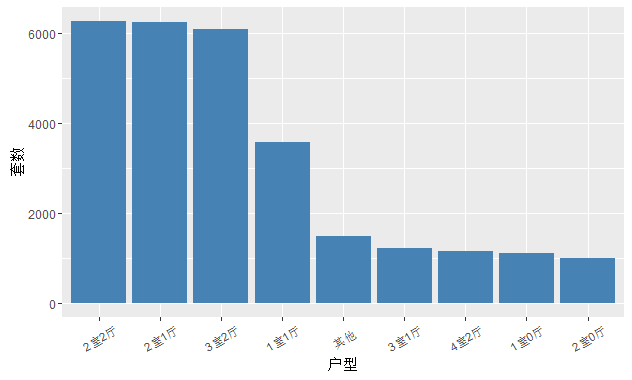
2、二手房的面积和房价的漫衍
# 面积的正态性检讨norm.test(house$面积)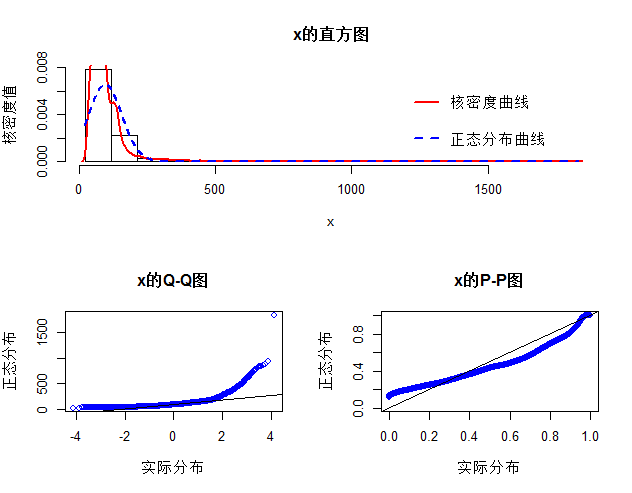
# 房价的正态性检讨norm.test(house$价值.W.)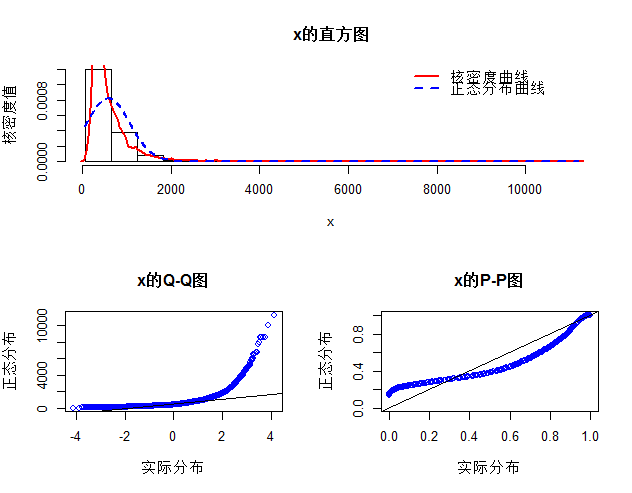
上面的norm.test函数是我自界说的函数,函数代码也在下文的链接中,可自行下载。从上图可知,二手房的面积和价值均不满意正态漫衍,那么就不能直接对这样的数据举办方差阐明或构建线性回归模子,因为这两种统计要领,都要求正态性漫衍的前提假设,后头我们会将讲授如那里理惩罚这样的问题。
3、二手房的楼层漫衍原始数据中关于楼层这一变量,总共有151种程度,如地上5层、低区/6层、中区/11层、高区/40层等,我们以为有须要将这151种程度配置为低区、中区和高区三种程度,这样做有助于后头建模的需要。
# 把楼层分为低区、中区和高区三种house$floow <- ifelse(substring(house$楼层,1,2) %in% c(‘低区’,’中区’,’高区’), substring(house$楼层,1,2),’低区’)
# 各楼层范例百分比漫衍percent <- paste(round(prop.table(table(house$floow))*100,2),’%’,sep = ”)df <- data.frame(table(house$floow))df <- cbind(df, percent)df
可见,三种楼层的漫衍概略相当,最多的为高区,占了36.1%。
4、上海各地域二手房的均价# 上海各区房价均价avg_price <- aggregate(house$单价.平方米., by = list(house$区域), mean)#画图p <- ggplot(data = avg_price, mapping = aes(x = reorder(Group.1, -x), y = x, group = 1)) + geom_area(fill = ‘lightgreen’) + geom_line(colour = ‘steelblue’, size = 2) + geom_point() + xlab(”) + ylab(‘均价’)p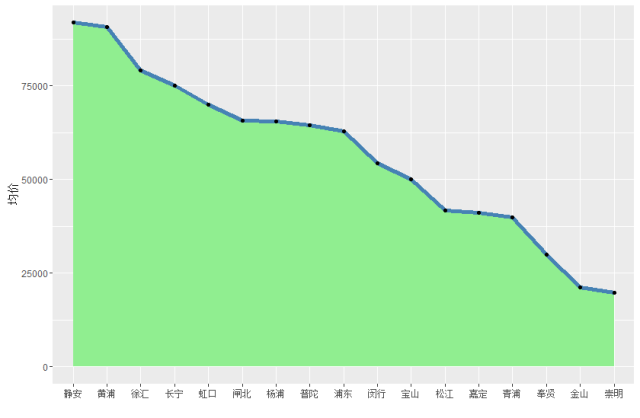
很明明,上海二手房价值较高的三个地域为:静安、黄埔和徐汇,均价都在7.5W以上,价值较低的三个地域为:崇明、金山和奉贤。
5、衡宇修建时间缺失严重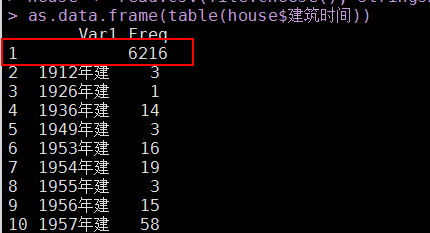
修建时间这个变量有6216个缺失,占了总样本的22%。固然缺失严重,但我也不能简朴粗暴的把该变量扔掉,所以思量到按各个区域分组,实现众数替补法。这里构建了两个自界说函数:
library(Hmisc)# 自界说众数函数stat.mode <- function(x, rm.na = TRUE){ if (rm.na == TRUE){ y = x[!is.na(x)] } res = names(table(y))[which.max(table(y))] return(res)}
# 自界说函数,实现分组替补my.impute <- function(data, category.col = NULL, miss.col = NULL, method = stat.mode){ impute.data = NULL for(i in as.character(unique(data[,category.col]))){ sub.data = subset(data, data[,category.col] == i) sub.data[,miss.col] = impute(sub.data[,miss.col], method) impute.data = c(impute.data, sub.data[,miss.col]) } data[,miss.col] = impute.data return(data)}
# 将修建时间中空缺字符串转换为缺失值house$修建时间[house$修建时间 == ”] <- NA#分组替补缺失值,并对数据集举办变量筛选final_house <- subset(my.impute(house, ‘区域’, ‘修建时间’),select = c(type.new,floow,面积,价值.W.,单价.平方米.,修建时间))#构建新字段,即修建时间与当前2016年的时长final_house <- transform(final_house, builtdate2now = 2016-as.integer(substring(as.character(修建时间),1,4)))#删除原始的修建时间这一字段final_house <- subset(final_house, select = -修建时间)
最终完成的清洁数据集如下: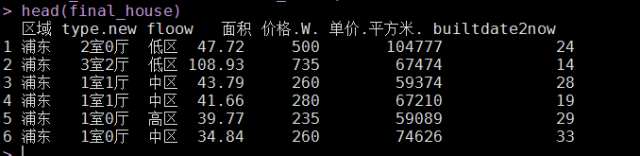
接下来就可以针对这样的清洁数据集,作进一步的阐明,如聚类、线性回归等。
三、模子构建这么多的屋子,我该如何把它们分分类呢?即应该把哪些房源归为一类?这就要用到聚类算法了,我们就利用简朴而快捷的k-means算法实现聚类的事情。但聚类前,我需要掂量一下我该聚为几类?按照聚类原则:组内差距要小,组间差距要大。我们绘制差异类簇下的组内离差平方和图,聚类进程中,我们选择面积、房价和单价三个数值型变量:
tot.wssplot <- function(data, nc, seed=1234){ #假设分为一组时的总的离差平方和 tot.wss <- (nrow(data)-1)*sum(apply(data,2,var)) for (i in 2:nc){ #必需指定随机种子数 set.seed(seed) tot.wss[i] <- kmeans(data, centers=i, iter.max = 100)$tot.withinss } plot(1:nc, tot.wss, type=”b”, xlab=”Number of Clusters”, ylab=”Within groups sum of squares”,col = ‘blue’, lwd = 2, main = ‘Choose best Clusters’)}
# 绘制差异聚类数目下的组内离差平方和standrad <- data.frame(scale(final_house[,c(‘面积’,’价值.W.’,’单价.平方米.’)]))myplot <- tot.wssplot(standrad, nc = 15)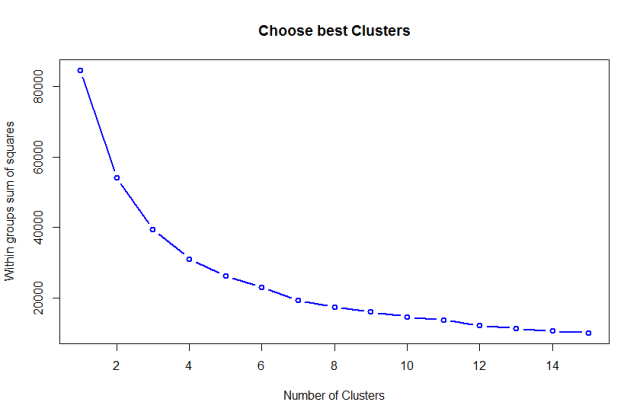
当把所有样本看成一类时,离差平方和到达较大,跟着聚类数量的增加,组内离差平方和会逐渐低落,直到极度环境,每一个样本作为一类,此时组内离差平方和为0。从上图看,聚类数量在5次以上,组内离差平方低落很是迟钝,可以把拐点看成5,即聚为5类。
# 将样本数据聚为5类set.seed(1234)clust <- kmeans(x = standrad, centers = 5, iter.max = 100)table(clust$cluster)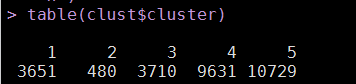
# 凭据聚类的功效,查察种种中的区域漫衍table(final_house$区域,clust$cluster)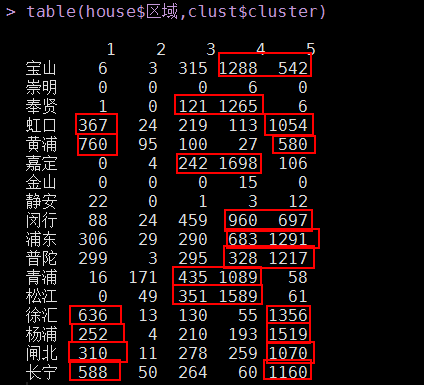
# 各户型的平均面积aggregate(final_house$面积, list(final_house$type.new), mean)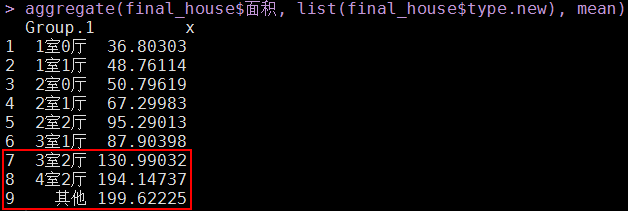
# 按聚类功效,较量种种中屋子的平均面积、平均价值僻静均单价aggregate(final_house[,3:5], list(clust$cluster), mean)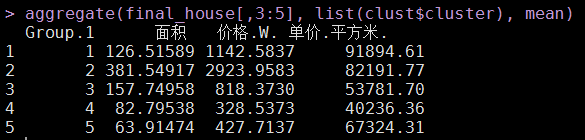
从平均程度来看,我概略可以将28000多套房源合成为如下几种说法:
a、大户型(3室2厅、4室2厅),属于第2类。平均面积都在130平以上,这种大户型的房源主要漫衍在青浦、黄埔、松江等地(详细可从种种中的区域漫衍图可知)。
b、地段型(房价高),属于第1类。典范的区域有黄埔、徐汇、长宁、浦东等地(详细可从种种中的区域漫衍图可知)。
c、公共蜗居型(面积小、价值适中、房源多),属于第4和5类。典范的区域有宝山、虹口、闵行、浦东、普陀、杨浦等地。
d、彷徨型(大户型与地段型之间的房源),属于第3类。典范的区域有奉贤、嘉定、青浦、松江等地。这些地域也是未来迅速崛起的处所。
# 绘制面积与单价的散点图,并按聚类举办分别p <- ggplot(data = final_house[,3:5], mapping = aes(x = 面积,y = 单价.平方米., color = factor(clust$cluster)))p <- p + geom_point(pch = 20, size = 3)p + scale_colour_manual(values = c(“red”,”blue”, “green”, “black”, “orange”))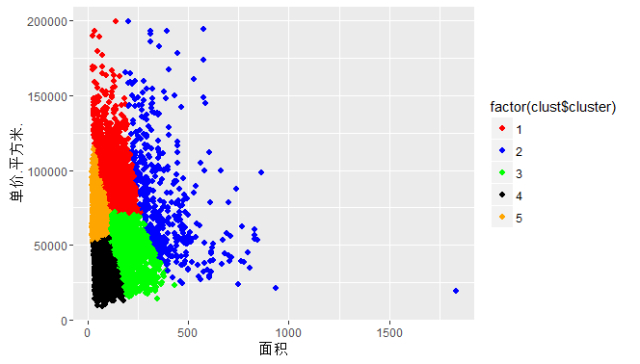
接下来我想借助于已有的数据(房价、面积、单价、楼层、户型、修建时长、聚类程度)构建线性回归方程,用于房价因素的判定及预测。由于数据中有离散变量,如户型、楼层等,这些变量入模的话需要对其举办哑变量处理惩罚。
# 结构楼层和聚类功效的哑变量# 将几个离散变量转换为因子,目标便于下面一次性处理惩罚哑变量final_house$cluster <- factor(clust$cluster)final_house$floow <- factor(final_house$floow)final_house$type.new <- factor(final_house$type.new)# 筛选出所有因子型变量factors <- names(final_house)[sapply(final_house, class) == ‘factor’]# 将因子型变量转换成公式formula的右半边形式formula <- f <- as.formula(paste(‘~’, paste(factors, collapse = ‘+’)))dummy <- dummyVars(formula = formula, data = final_house)pred <- predict(dummy, newdata = final_house)head(pred)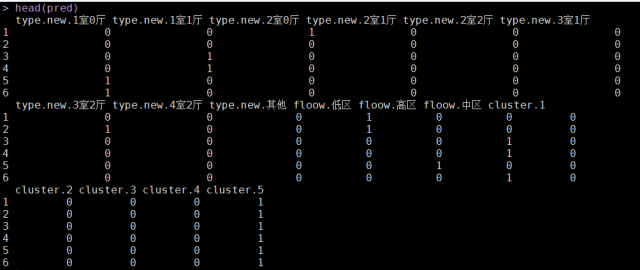
# 将哑变量规整到final_house数据会合final_house2 <- cbind(final_house,pred)# 筛选出需要建模的数据model.data <- subset(final_house2,select = -c(1,2,3,8,17,18,24))# 直接对数据举办线性回归建模fit1 <- lm(价值.W. ~ .,data = model.data)summary(fit1)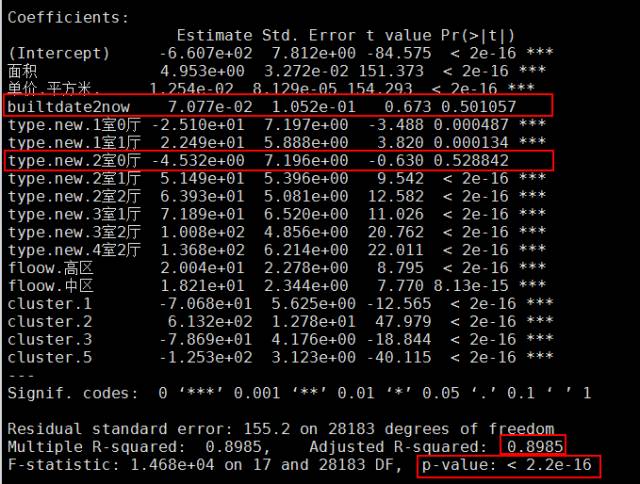
从体看上去还行,只有修建时长和2室0厅的房型参数不显著,其他均在0.01置信程度下显著。不要赞赞自喜,我们说,利用线性回归是有假设前提的,即因变量满意正态或近似于正态漫衍,前面说过,房价明明在样本中是偏态的,并不平从正态漫衍,所以这里利用COX-BOX调动处理惩罚。按照COX-BOX调动的lambda功效,我们针对y变量举办转换,即:
# Cox-Box转换library(car)powerTransform(fit1)
按照功效显示,0.23很是靠近上表中的0值,故思量将二手房的价值举办对数调动。
fit2 <- lm(log(价值.W.) ~ .,data = model.data)summary(fit2)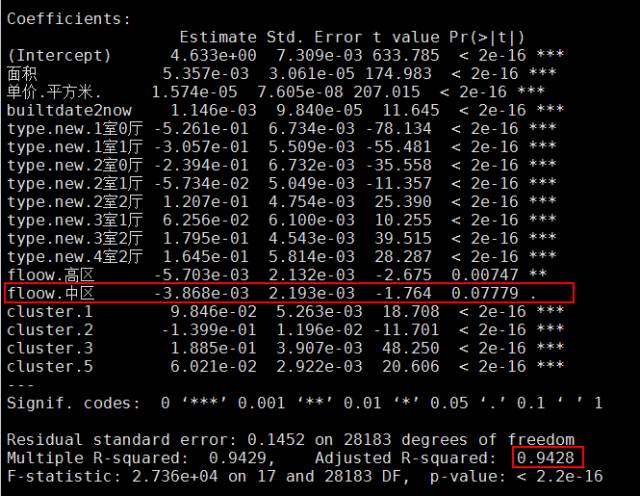
这次的功效就明明比fit1好许多,仅有楼层的中区在0.1置信程度下显著,其余变量均在0.01置信程度下显著,并且调解的R方值也提高到了94.3%,即这些自变量对房价的表明度到达了94.3%。
最后我们再看一下,关于最终模子的诊断功效:
# 利用plot要领完成模子定性的诊断opar <- par(no.readonly = TRUE)par(mfrow = c(2,2))plot(fit2)par(opar)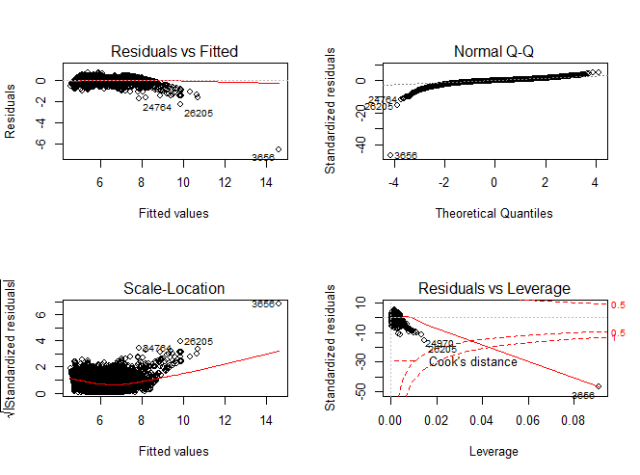
从上图看,根基上满意了线性回归模子的几个假设,即:残差项听从均值为0(左上),尺度差为常数(左下)的正态漫衍漫衍(右上)。基于这样的模子,我们就可以有针对性的预测房价啦~
本日的进修进程就到这里,假如有疑问可以给我留言可能加微信(lsx19890717)详聊。本文中的爬虫代码、R语言剧本和数据均可在如下链接中获取:链接: http://pan.baidu.com/s/1c1BFhXe 暗码: 36dm
接待插手本站果真乐趣群贸易智能与数据阐明群乐趣范畴包罗各类让数据发生代价的步伐,实际应用案例分享与接头,阐明东西,ETL东西,数据客栈,数据挖掘东西,报表系统等全方位常识QQ群:81035754
