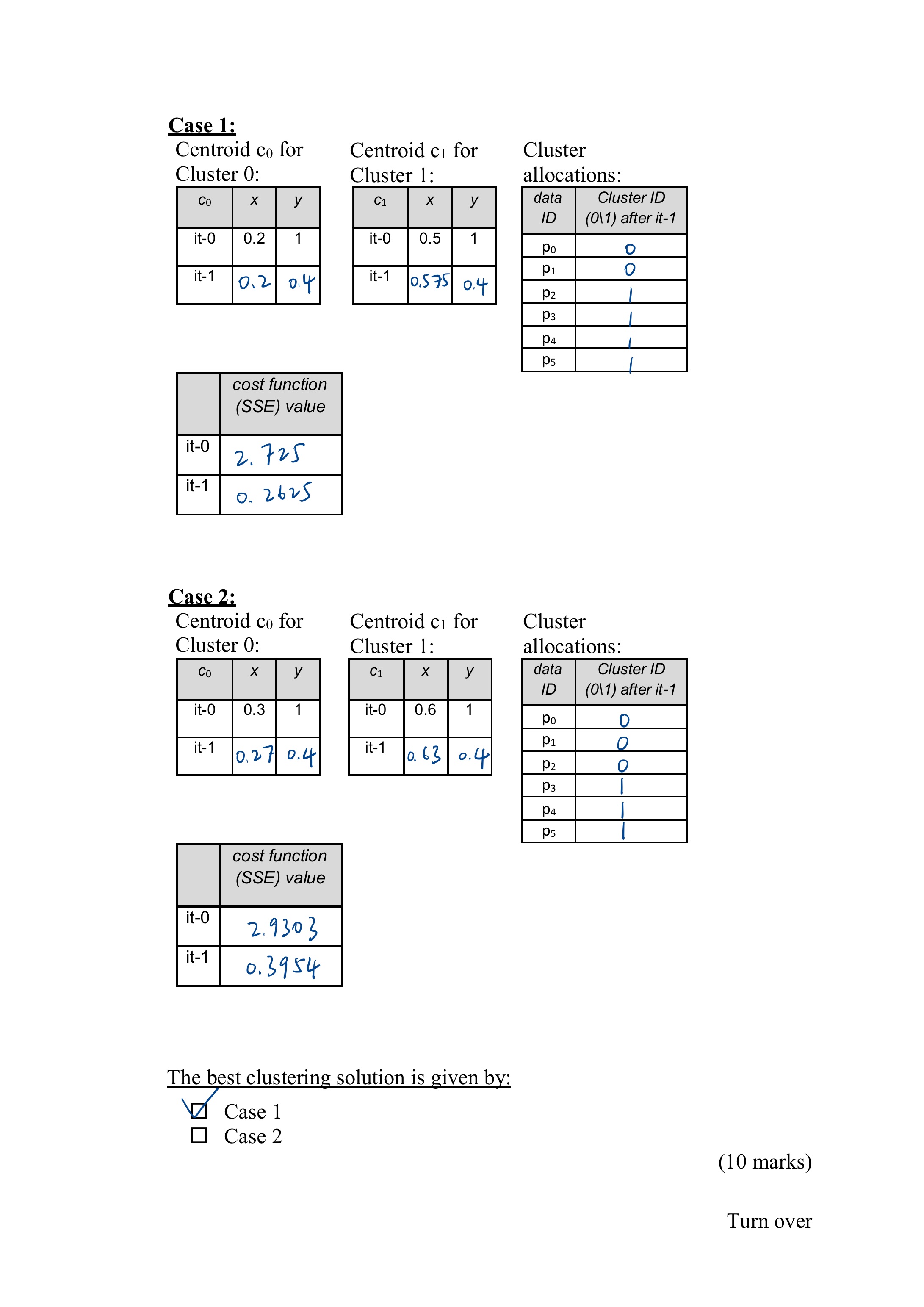
Problem 2
数据科学和算法工具代写 In this part we would compare K means clustering (partitional) and Agglomerative hierarchical clustering (hierarchical).
Part (a)
Cluster analysis is an unsupervised classification that partitions a set of data into meaningful sub-classes or clusters, based on a similarity measure and a clustering algorithm. Within each cluster, the data / objects would be quite similar to each other and show a pattern of natural grouping, i.e. high intra-class similarity. Between groups, the data / objects should be dissimilar, or low inter-class similarity. Cluster analysis is usually applied in tasks whose nature is to discover groupings or hiddensu patterns in data, such as pattern recognition / marketing and so on. There are two typical types of clustering, partitional and hierarchical.
Partitional clustering will assign each data point to a centroid and thus generate some partitions of the data iteratively. The centroids for each partition are usually estimated using the member of that partition. 数据科学和算法工具代写
Hierarchical clustering will generate a set of nested clusters organized as a hierarchical tree that is similar to taxonomy structure. It can be done via agglomerative clustering or divisive clustering. The former approach will start with each point being a cluster of its own, then the algorithm merge closest points until there is only one cluster left. The latter one will start with one cluster containing all data, then split the cluster till each cluster contains one data point only.

Part (b) 数据科学和算法工具代写
In this part we would compare K means clustering (partitional) and Agglomerative hierarchical clustering (hierarchical).
The advantage of K means over agglomerative method is:
Very simple and intuitive to interpret
It’s computationally efficient, so it adapts to new data very easily. For each input of new data, we can simply calculate its distance to all centroids, and pick the closest one as its label. 数据科学和算法工具代写
Its disadvantages are:
We will have to pick the parameter k manually. Too low or too high the k value will generate poor performance and it’s relatively hard to tune.
It doesn’t scale well with high dimensional data, distance based metrics generally converge to similar values when the dimension is high. And k means algorithm based on distance metric would fail.
The agglomerative method’s advantages are:
We don’t have to specify the parameter k.
The dendrogram chart is hierarchical and could help us determine hidden patterns of the data. 数据科学和算法工具代写
The disadvantages are:
It’s more complex to compute than k means, as we will have to check all possible pairs of data points.
It doesn’t adapt to new data easily. We will have to check the connection between new data points and all existing points to decide the clustering.
Part (c) 数据科学和算法工具代写
The filled worksheet is attached below: