A data analysis of Holland housing price
数据分析代写 This is a data analysis on Holland’s housing price. This report will be mainly consisted of two parts: housing data
This is a data analysis on Holland’s housing price. This report will be mainly consisted of two parts: housing data(describing inner information and their impact on housing price) and full_data(describing outer information and their impact on housing price). For each part, we will process as follows:
- dealing with missing values 数据分析代写
- exploratory analysis
- modeling(gradient boosting, support vector regression and neural network) and conclusion
In [1]:
# First, import some necessary librairies
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
%matplotlib inline
import matplotlib.pyplot as plt # Matlab-style plotting
In [2]: data analysis1代写
#Now let’s import and put the train and test datasets in pandas dataframe
full_data = pd.read_excel(‘full_data.xlsx’)
housing = pd.read_excel(‘housing.xls’)
In [3]:
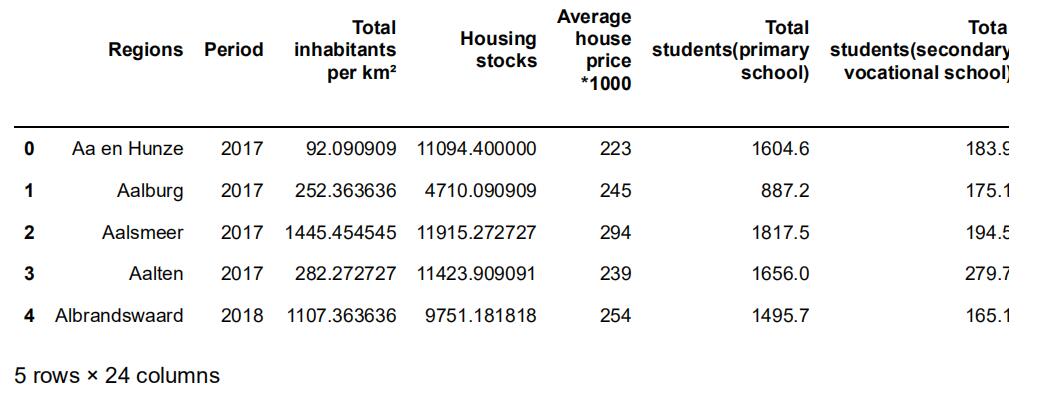
##display the first five rows of the full_data.
full_data.head()
Out[3]:
In [4]:
#display the first five rows of the housing dataset.
housing.head(5)
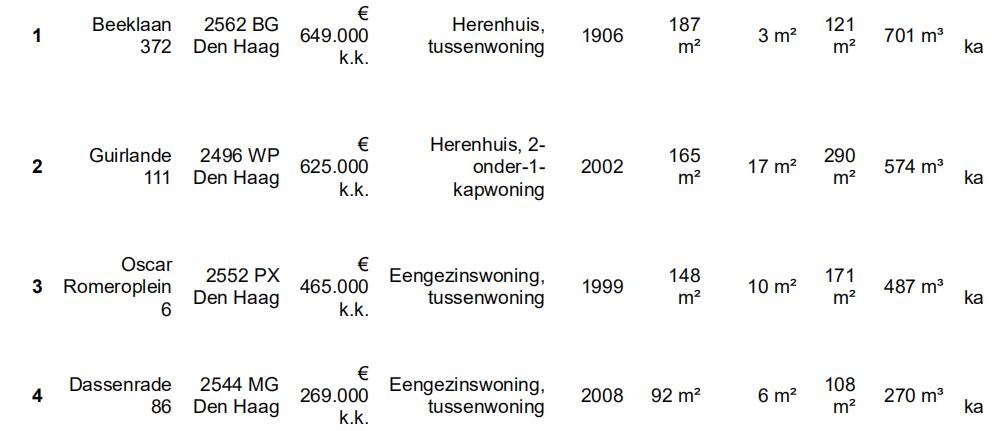
In [5]:
#check the numbers of samples and features
print(“The full_data size before dropping Id feature is : {} “.format(full_data.s
print(“The housing data size before dropping Id feature is : {} “.format(housing.
The full_data size before dropping Id feature is : (381, 24)
The housing data size before dropping Id feature is : (1689, 19)

Part 1: housing data 数据分析代写
Dealing with missing values
From the data above, we obviously find out that some of columns in housing is problematic. For example, Sale price and living area are both strings instead of numerical values. Next, we fix each column one by one.
Sale Price 数据分析代写
In [6]:
# Since our target is Sale Price, nan in Sale Price column is meaningless data
# first drop all rows with nan Sale Price
housing = housing.dropna(subset = [“Sale Price”])
print(housing.shape)
housing.index = range(housing.shape[0])
(1681, 19)
Notice here we delete 8 rows which does not contain Sale Price information
Above we drop seven rows without Sale Price information each price is a stirng, we try to transform string into numerical values 数据分析代写
In [7]:
# fix sale price
def fixsaleprice(input):
ans = ”
for ii in range(len(input)):
if(input[ii].isdigit()):
ans=ans+input[ii]data analysis1代写
return int(ans)
for ii in range(housing.shape[0]):
string = housing.iloc[ii,2]
housing.iloc[ii,2] = fixsaleprice(string)
House type 数据分析代写
Some of house type is missing. I will fill all na with empty strings
In [8]:
housing[“House type”] = housing[“House type”].fillna(“None”)
In [9]:
housing[“House type”] = housing[“House type”].astype(str)
YEAR BUILD 数据分析代写
For “YEAR BUILD”, some values are missing, some are wrong(year 2019 in column “YEAR BUILD”), some are actually strings. We fix them one by one.
In [10]:
for ii in range(housing.shape[0]):
if(housing.iloc[ii,4] == “Na 2011”):
housing.iloc[ii,4] = “2011”
if(housing.iloc[ii,4] == “Voor 1906”):
housing.iloc[ii,4] = “1906”
housing.iloc[ii,4] = float(housing.iloc[ii,4])数据分析代写
In [11]:
# To fill in all nan values in “YEAR BUILD”, replace all nan in “YEAR BUILD” with
median = housing[“YEAR BUILD”].median(skipna = True)
housing[“YEAR BUILD”] = housing[“YEAR BUILD”].fillna(median)
# check whether there is still missing values in this column
print(housing[“YEAR BUILD”].isnull().values.any())
False
In [12]:
# Use 2018 – this column’s value to replace this column
for ii in range(housing.shape[0]):
housing.iloc[ii,4] = (2018 – housing.iloc[ii,4])
Living area 数据分析代写
Note each Living area is strings, I transform of them into numerical values.
In [13]:
for ii in range(housing.shape[0]):
string = housing[“Living area”].iloc[ii]
if(not pd.isnull(string)):
housing[“Living area”].iloc[ii] = int(string[:–2])
median = housing[“Living area”].median(skipna = True)
housing[“Living area”] = housing[“Living area”].fillna(median)
housing[“Living area”].isnull().values.any()数据分析代写
C:\Users\25735\Anaconda3\lib\site-packages\pandas\core\indexing.py:194: Setting WithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stab le/indexing.html#indexing-view-versus-copy (http://pandas.pydata.org/pandas-doc s/stable/indexing.html#indexing-view-versus-copy)
self._setitem_with_indexer(indexer, value)
Out[13]: False
External storage space data analysis1代写
With similar method, I transform “External storage space” into numerical values.
In [14]:
for ii in range(housing.shape[0]):
if(not pd.isnull(housing[“External storage space”].iloc[ii])):
housing[“External storage space”].iloc[ii] = int(housing[“External storage
median = housing[“External storage space”].median(skipna=True)
housing[“External storage space”] = housing[“External storage space”].fillna(media
print(housing[“External storage space”].isnull().values.any())
C:\Users\25735\Anaconda3\lib\site-packages\pandas\core\indexing.py:194: Setting WithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame 数据分析代写
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stab le/indexing.html#indexing-view-versus-copy (http://pandas.pydata.org/pandas-doc s/stable/indexing.html#indexing-view-versus-copy)
self._setitem_with_indexer(indexer, value) False
Plot area
In [15]:
for ii in range(housing.shape[0]):
if(not pd.isnull(housing[“Plot area”].iloc[ii])):
housing[“Plot area”].iloc[ii] = fixsaleprice(housing[“Plot area”].iloc[ii
median = housing[“Plot area”].median(skipna=True)
housing[“Plot area”] = housing[“Plot area”].fillna(median)
print(housing[“Plot area”].isnull().values.any())数据分析代写
C:\Users\25735\Anaconda3\lib\site-packages\pandas\core\indexing.py:194: Setting WithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stab le/indexing.html#indexing-view-versus-copy (http://pandas.pydata.org/pandas-doc s/stable/indexing.html#indexing-view-versus-copy)
self._setitem_with_indexer(indexer, value) False
Volume 数据分析代写
In [16]:
for ii in range(housing.shape[0]):
if(not pd.isnull(housing[“Volume”].iloc[ii])):
housing[“Volume”].iloc[ii] = fixsaleprice(housing[“Volume”].iloc[ii][:–2]
median = housing[“Volume”].median(skipna=True)
housing[“Volume”] = housing[“Volume”].fillna(median)
print(housing[“Volume”].isnull().values.any())
C:\Users\25735\Anaconda3\lib\site-packages\pandas\core\indexing.py:194: Setting WithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stab le/indexing.html#indexing-view-versus-copy (http://pandas.pydata.org/pandas-doc s/stable/indexing.html#indexing-view-versus-copy)
self._setitem_with_indexer(indexer, value) False
total rooms数据分析代写
In [17]:
for ii in range(housing.shape[0]):
if(not pd.isnull(housing[“total rooms”].iloc[ii])):
housing[“total rooms”].iloc[ii] = int(housing[“total rooms”].iloc[ii][:–7
median = housing[“total rooms”].median(skipna=True)
housing[“total rooms”] = housing[“total rooms”].fillna(median)
print(housing[“total rooms”].isnull().values.any())
C:\Users\25735\Anaconda3\lib\site-packages\pandas\core\indexing.py:194: Setting WithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stab le/indexing.html#indexing-view-versus-copy (http://pandas.pydata.org/pandas-doc s/stable/indexing.html#indexing-view-versus-copy)
self._setitem_with_indexer(indexer, value) False
sleeprooms
In [18]:
for ii in range(housing.shape[0]):
if(not pd.isnull(housing[“sleeprooms”].iloc[ii])):
housing[“sleeprooms”].iloc[ii] = int(housing[“sleeprooms”].iloc[ii][:–11]
median = housing[“sleeprooms”].median(skipna=True)
housing[“sleeprooms”] = housing[“sleeprooms”].fillna(median)
print(housing[“sleeprooms”].isnull().values.any())
C:\Users\25735\Anaconda3\lib\site-packages\pandas\core\indexing.py:194: Setting WithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame 数据分析代写
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stab le/indexing.html#indexing-view-versus-copy (http://pandas.pydata.org/pandas-doc s/stable/indexing.html#indexing-view-versus-copy)
self._setitem_with_indexer(indexer, value) False
bathrooms 数据分析代写
In [19]:
for ii in range(housing.shape[0]):
if(not pd.isnull(housing[“bathrooms”].iloc[ii])):
housing[“bathrooms”].iloc[ii] = fixsaleprice(housing[“bathrooms”].iloc[ii
housing[“bathrooms”] = housing[“bathrooms”].fillna(0)
housing[“bathrooms”].isnull().values.any()
C:\Users\25735\Anaconda3\lib\site-packages\pandas\core\indexing.py:194: Setting WithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stab le/indexing.html#indexing-view-versus-copy (http://pandas.pydata.org/pandas-doc s/stable/indexing.html#indexing-view-versus-copy)
self._setitem_with_indexer(indexer, value)
Out[19]: False
separate toilet 数据分析代写
In [20]:
for ii in range(housing.shape[0]):
if(not pd.isnull(housing[“separate toilet”].iloc[ii])):
housing[“separate toilet”].iloc[ii] = fixsaleprice(housing[“separate toile
housing[“separate toilet”] = housing[“separate toilet”].fillna(0)
housing[“separate toilet”].isnull().values.any()
C:\Users\25735\Anaconda3\lib\site-packages\pandas\core\indexing.py:194: Setting WithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stab le/indexing.html#indexing-view-versus-copy (http://pandas.pydata.org/pandas-doc s/stable/indexing.html#indexing-view-versus-copy)数据分析代写
self._setitem_with_indexer(indexer, value)
Out[20]: False
Number of floors\n
In [21]:
for ii in range(housing.shape[0]):
if(not pd.isnull(housing[“Number of floors\n”].iloc[ii])):
housing[“Number of floors\n”].iloc[ii] = fixsaleprice(housing[“Number of f
housing[“Number of floors\n”] = housing[“Number of floors\n”].fillna(1)
housing[“Number of floors\n”].isnull().values.any()
C:\Users\25735\Anaconda3\lib\site-packages\pandas\core\indexing.py:194: Setting WithCopyWarning:数据分析代写
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stab le/indexing.html#indexing-view-versus-copy (http://pandas.pydata.org/pandas-doc s/stable/indexing.html#indexing-view-versus-copy)
self._setitem_with_indexer(indexer, value)
Out[21]: False
EERGY LABELn
Energy label are quite hard to understand, so I throw it away.
In [22]:housing = housing.drop([“Energy label”],axis = 1)
Heating type数据分析代写
In [23]:
housing[“Heating type”] = housing[“Heating type”].fillna(“None”)
housing[“Heating type”].isnull().values.any()
Out[23]: False
Ownership situation
In [24]:
housing[“Ownership situation”] = housing[“Ownership situation”].fillna(“None”)
housing[“Ownership situation”].isnull().values.any()
Out[24]: False
Backyard 数据分析代写
In [25]:
for ii in range(housing.shape[0]):
if(not pd.isnull(housing[“Backyard”].iloc[ii])):
if(not housing[“Backyard”].iloc[ii].isdigit()):
housing[“Backyard”].iloc[ii] = 0
C:\Users\25735\Anaconda3\lib\site-packages\pandas\core\indexing.py:194: Setting WithCopyWarning:数据分析代写
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stab le/indexing.html#indexing-view-versus-copy (http://pandas.pydata.org/pandas-doc s/stable/indexing.html#indexing-view-versus-copy)
self._setitem_with_indexer(indexer, value)
Out[25]: False
Barn storage
In [26]:housing[“Barn storage”] = housing[“Barn storage”].fillna(“None”)
Adres, Postcode数据分析代写
In [27]:housing = housing.drop([“Adres”,”Postcode”], axis = 1)
In [28]:
# check whether there is still missing values
housing.isnull().values.any()数据分析代写
Out[28]: False
In [29]:
# transform Sale Price into by using log transformation, because we are more conce
train_label = np.log(housing[“Sale Price”].astype(int))
In [30]:
# Use one-hot encoding to encode categorical features
train_data = pd.concat([housing[[‘YEAR BUILD’, ‘Living area’, ‘External storage s
In [31]:
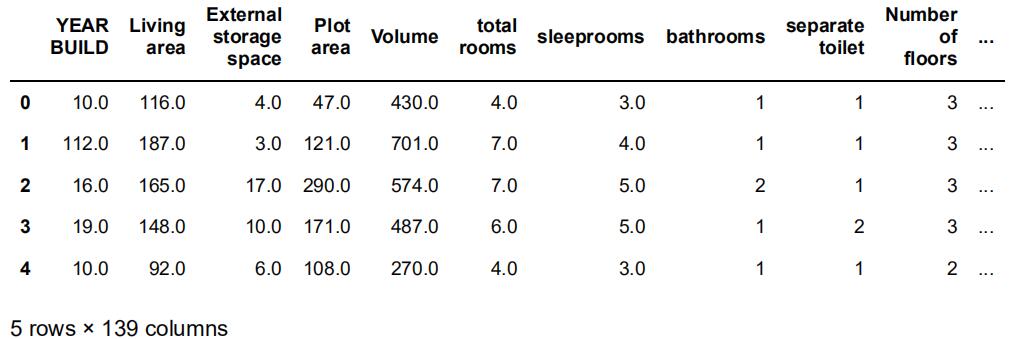
# have a look at training data数据分析代写
train_data.head()
Out[31]:
Exploratory data analysis
correlation heat map between numerical values
In [32]:
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style=”white”)
train = housing[[‘Sale Price’,‘YEAR BUILD’, ‘Living area’, ‘External storage space
train[“Sale Price”] = train[“Sale Price”].astype(“int”)数据分析代写
# Compute the correlation matrix
corr = train.corr()
# Generate a mask for the upper triangle
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 9))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={“shrink”: .5})数据分析代写
C:\Users\25735\Anaconda3\lib\site-packages\ipykernel_launcher.py:7: SettingWith CopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stab le/indexing.html#indexing-view-versus-copy (http://pandas.pydata.org/pandas-doc s/stable/indexing.html#indexing-view-versus-copy)数据分析代写
import sys
Out[32]: <matplotlib.axes._subplots.AxesSubplot at 0x23cf1e39be0>
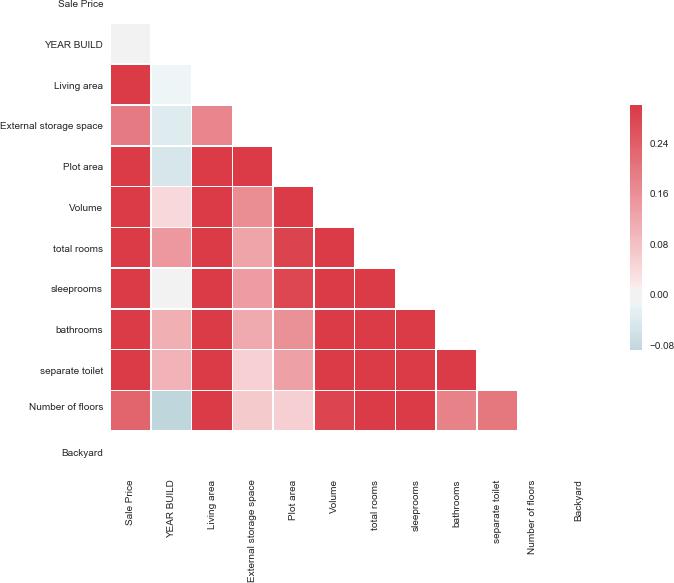
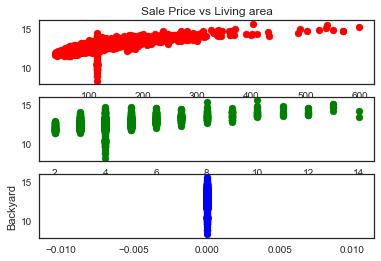
To visualize correlation better, I choose three features to and use scatterplot to see the trend.
In [35]:
%matplotlib inline
plt.subplot(3,1,1)
plt.scatter(train_data[“Living area”],train_label,c=‘r’)
plt.title(‘Sale Price vs Living area’)数据分析代写
plt.xlabel(‘Living area’)
plt.subplot(3,1,2)
plt.scatter(train_data[“total rooms”],train_label,c=‘g’)
plt.xlabel(‘total rooms’)数据分析代写
plt.subplot(3,1,3)
plt.scatter(train_data[“Backyard”],train_label,c=‘b’)
plt.ylabel(“Backyard”)
plt.show()
Modeling
In [36]:
from sklearn.model_selection import KFold, cross_val_score, train_test_split
from sklearn.metrics import mean_squared_error
import xgboost as xgb
Define a cross validation strategy
I use the cross_val_score function of Sklearn. However this function has not a shuffle attribut, I add then one line of code, in order to shuffle the dataset prior to cross-validation数据分析代写
In [37]:
#Validation function
n_folds = 5
def rmsle_cv(model):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train_data.va
rmse= np.sqrt(–cross_val_score(model, train_data.values, train_label, scoring=
return(rmse)
XGBoost
In [38]:
model_xgb = xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200, 数据分析代写
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =7, nthread = –1)
Let’s see how these base models perform on the data by evaluating the cross-validation rmsle error
In [39]:
score = rmsle_cv(model_xgb)
print(“Xgboost score: {:.4f} ({:.4f})\n”.format(score.mean(), score.std()))
Xgboost score: 0.2939 (0.0385)
In [40]:
model_xgb.fit(train_data,train_label)数据分析代写
Out[40]: XGBRegressor(base_score=0.5, booster=’gbtree’, colsample_bylevel=1, colsample_bytree=0.4603, gamma=0.0468, learning_rate=0.05, max_delta_step=0, max_depth=3, min_child_weight=1.7817, missing=None, n_estimators=2200, n_jobs=1, nthread=-1, objective=’reg:linear’, random_state=7, reg_alpha=0.464, reg_lambda=0.8571, scale_pos_weight=1, seed=None, silent=1, subsample=0.5213)
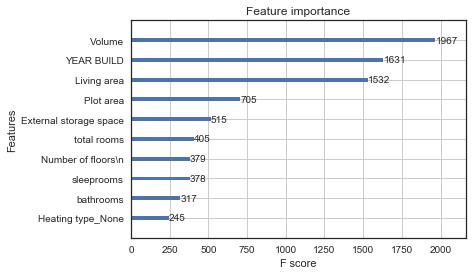
Now plot importance of 10 most important features
In [41]:
Out[41]: <matplotlib.axes._subplots.AxesSubplot at 0x23cf4826b38>
xgb.plot_importance(model_xgb,max_num_features = 10)
support vectore regression 数据分析代写
In [42]:
from sklearn import svm
model_svr = svm.SVR()
score = rmsle_cv(model_svr)
print(“rmse of support vector regression is {}, standard error is {}”.format(score
rmse of support vector regression is 0.5403059119987044, standard error is 0.09 083728321588952
neural network
In [44]:
from keras import Sequential
model = Sequential()
from keras.layers import Dense
model.add(Dense(units=16, activation=‘relu’, input_dim=139))
model.add(Dense(units=16, activation=‘linear’, input_dim=16))数据分析代写
model.add(Dense(units=1, activation=‘relu’, input_dim=16))
model.compile(loss=‘mean_squared_error’, optimizer=‘sgd’, metrics=[‘accuracy’])
model.fit(x=train_data,y=train_label,validation_split=0.1,epochs = 5,batch_size =
Train on 1512 samples, validate on 169 samples Epoch 1/5
1512/1512 [==============================] – 0s 209us/step – loss: nan – acc:
0.0000e+00 – val_loss: nan – val_acc: 0.0000e+00 Epoch 2/5
1512/1512 [==============================] – 0s 96us/step – loss: nan – acc: 0.
0000e+00 – val_loss: nan – val_acc: 0.0000e+00 Epoch 3/5数据分析代写
1512/1512 [==============================] – 0s 100us/step – loss: nan – acc:
0.0000e+00 – val_loss: nan – val_acc: 0.0000e+00 Epoch 4/5
1512/1512 [==============================] – 0s 119us/step – loss: nan – acc:
0.0000e+00 – val_loss: nan – val_acc: 0.0000e+00 Epoch 5/5
1512/1512 [==============================] – 0s 161us/step – loss: nan – acc:
0.0000e+00 – val_loss: nan – val_acc: 0.0000e+00
Out[44]: <keras.callbacks.History at 0x23cf9080e48>数据分析代写
With so limited data, it’s hard to train a neural network
Final conclusion
Among three models, XGBoost performs best, the most important several features are “Volume”,”YEAR BUILD”,”Living area”,”Plot area”,”External storage space”,”total rooms”.
Part 2: full data数据分析代写
Missing values
I think region is unnecessary for our analysis, so I choose to drop it.
In [45]:
full_data = full_data.drop([“Regions”],axis = 1)
For “Period”, I choose to use 2018 to minus this column
In [46]:
full_data[“Period”] = 2018 – full_data[“Period”]数据分析代写
For the rest of the data, since missing values are so limited and missing values probably means no cars or limited road length in kms, I choose to fill in 0s
In [47]:
full_data = full_data.fillna(0)数据分析代写
Exploratory data analysis
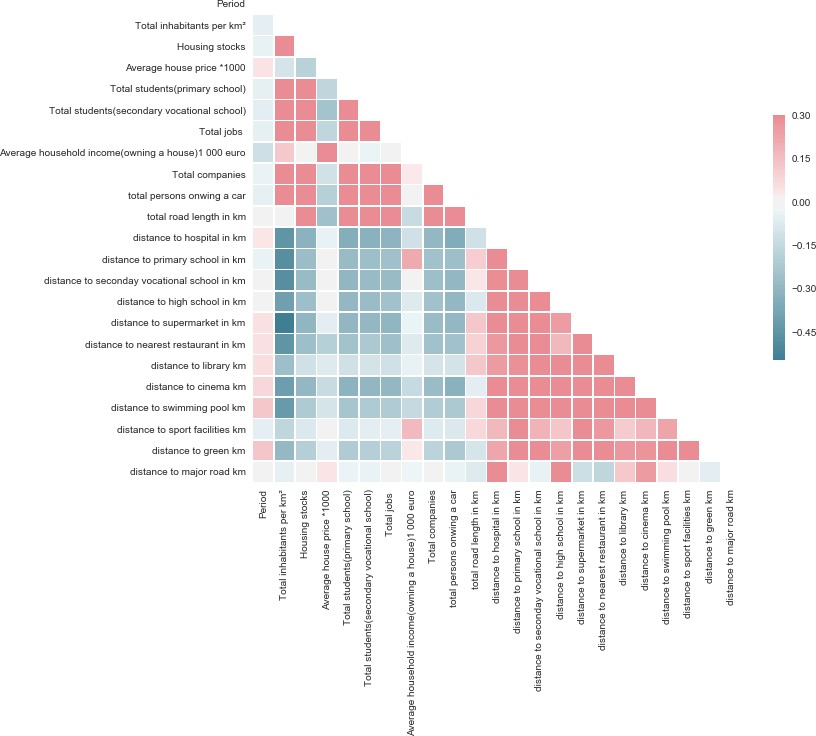
correlation heatmap
In [48]:
sns.set(style=”white”)
train = full_data
# Compute the correlation matrix
corr = train.corr()
# Generate a mask for the upper triangle
mask = np.zeros_like(corr, dtype=np.bool)数据分析代写
mask[np.triu_indices_from(mask)] = True
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11, 9))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={“shrink”: .5})
Out[48]: <matplotlib.axes._subplots.AxesSubplot at 0x23cf9687ba8>
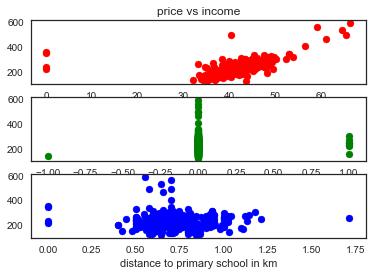
scatterplot with respect to highly correlated variables
In [49]:
%matplotlib inline
plt.subplot(3,1,1)
plt.scatter(full_data[“Average household income(owning a house)1 000 euro”],full_d
plt.title(‘price vs income’)
plt.xlabel(‘income’)数据分析代写
plt.subplot(3,1,2)
plt.scatter(full_data[“Period”],full_data[“Average house price *1000”],c=‘g’)
plt.xlabel(‘Period’)
plt.subplot(3,1,3)
plt.scatter(full_data[“distance to primary school in km”],full_data[“Average house
plt.xlabel(“distance to primary school in km”)数据分析代写
plt.show()
Modeling 数据分析代写
XGBoost
In [50]:
model_xgb = xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =7, nthread = –1)数据分析代写
set up cross validation function
In [51]:
#Validation function
n_folds = 5
def rmsle_cv(model):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(full_data.dro
rmse= np.sqrt(–cross_val_score(model, full_data.drop([“Average house price *10
return(rmse)数据分析代写
In [52]:
score = rmsle_cv(model_xgb)
print(“Xgboost score: {:.4f} ({:.4f})\n”.format(score.mean(), score.std()))
Xgboost score: 0.1370 (0.0258)
Here, we find out the error is actually smaller than that of housing data.
In [54]:
model_xgb.fit(full_data.drop([“Average house price *1000”],axis = 1),full_data[“A
Out[54]: XGBRegressor(base_score=0.5, booster=’gbtree’, colsample_bylevel=1, colsample_bytree=0.4603, gamma=0.0468, learning_rate=0.05, max_delta_step=0, max_depth=3, min_child_weight=1.7817, missing=None, n_estimators=2200, n_jobs=1, nthread=-1, objective=’reg:linear’, random_state=7, reg_alpha=0.464, reg_lambda=0.8571, scale_pos_weight=1, seed=None, silent=1, subsample=0.5213)数据分析代写
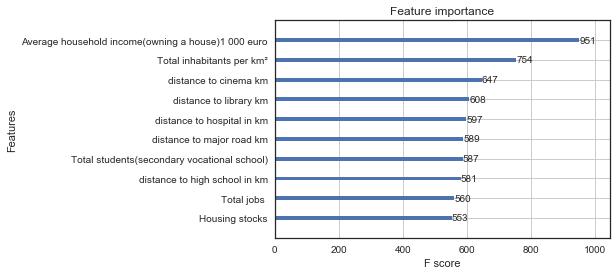
Similarly, we will plot the ten most important features
In [55]:
xgb.plot_importance(model_xgb,max_num_features = 10)
Out[55]: <matplotlib.axes._subplots.AxesSubplot at 0x23cf9669748>
Support vector regression 数据分析代写
In [56]:
from sklearn import svm
model_svr = svm.SVR()
score = rmsle_cv(model_svr)
print(“rmse of support vector regression is {}, standard error is {}”.format(score
rmse of support vector regression is 0.2375679885077536, standard error is 0.02 6084243485418934
Neural Network
In [57]:
from keras import Sequential
model = Sequential()
from keras.layers import Dense
model.add(Dense(units=16, activation=‘relu’, input_dim=22))
model.add(Dense(units=16, activation=‘linear’, input_dim=16))数据分析代写
model.add(Dense(units=1, activation=‘relu’, input_dim=16))
model.compile(loss=‘mean_squared_error’, optimizer=‘sgd’, metrics=[‘accuracy’])
model.fit(x=full_data.drop([“Average house price *1000”],axis = 1), y=full_data[“A
Train on 342 samples, validate on 39 samples Epoch 1/5
342/342 [==============================] – 0s 491us/step – loss: nan – acc: 0.0
000e+00 – val_loss: nan – val_acc: 0.0000e+00 Epoch 2/5数据分析代写
342/342 [==============================] – 0s 79us/step – loss: nan – acc: 0.00
00e+00 – val_loss: nan – val_acc: 0.0000e+00 Epoch 3/5
342/342 [==============================] – 0s 117us/step – loss: nan – acc: 0.0
000e+00 – val_loss: nan – val_acc: 0.0000e+00 Epoch 4/5
342/342 [==============================] – 0s 82us/step – loss: nan – acc: 0.00
00e+00 – val_loss: nan – val_acc: 0.0000e+00 Epoch 5/5数据分析代写
342/342 [==============================] – 0s 85us/step – loss: nan – acc: 0.00
00e+00 – val_loss: nan – val_acc: 0.0000e+00 Out[57]: <keras.callbacks.History at 0x23cf9870668>
Similary, with so little data, it’s really hard to train a neural network.
Conclusion
Again, we find that xgboost performs best among three models. And for full_data, the overall error is smaller than that of housing dataset. I guess that’s because full_data dataset is an average of all house in this area, error is more likely to cancel out each other. Pitersonally, I prefer to use xgboosgt in this scenario, not only because gradient boosing machine product the least error here, but it also
provides an interpretation of the data. For example, for full_data dataset, xgboost reveals that average house income, population and distance to cinema are the three most important factors in affecting housing price. Neural network can not perform well in this scenario, because the number of parameters in neural network is even comparable to number of samples.
其他代写:考试助攻 计算机代写 java代写 algorithm代写 代写CS assembly代写 function代写paper代写 r代写 web代写 数学代写 essay代写 编程代写 report代写 algorithm代写 Data Analysis代写
