在数据挖掘软件中有五大开源软件,个中weka在海内的利用率较高,而rapidminer却较少看到。就连进修资料也少之又少,只在youtube上能看到一些解说视频。以下的内容就是照葫芦画瓢弄出来的。
文本挖掘(text mining)有时也被称为文字探勘、文本数据挖掘等,大抵相当于文字阐明,一般指文本处理惩罚进程中发生高质量的信息。高质量的信息凡是通过度类和预测来发生,如模式识别。
文本挖掘凡是要将文本举办断字预处理惩罚,然后操作空间向量模子将文本转换为数值数据,让进修器举办进修。中文的文本挖掘天生就较量悲凉,因为中文不象英文那样天然断字。并且中文语料库很少有免费的,要本身去处理惩罚语料那真是工程量浩荡。因此只有转而求其次,操作网上已有的英文免费文本库中的新闻稿件举办文本挖掘尝试。算是做一个rapidminer的操练。
此次任务是对从两种新闻来历中抽取文本,阐明其特征词汇,成立分类模子,然后按照模子来检测分类的结果。
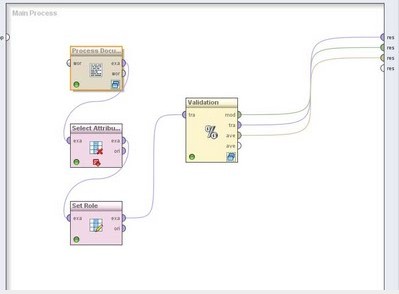
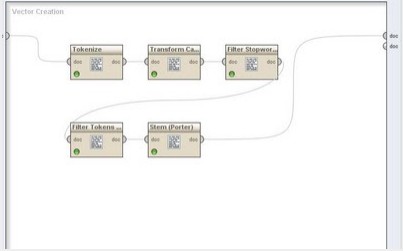
首先打开rapidminer,新建一个流程。从左侧opertors里找出process Document拖入主窗口,在右侧参数栏text directories中写入文本储存路径和种别。双击进入子流程,再从opertors里找出断词算子(Tokenize)以及各过滤算子举办子流程毗连。
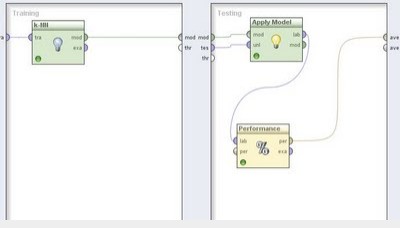
举办下一步数据处理惩罚,去除缺失值并指定方针变量,最后要害是将validation算子拖入主窗口,以举办建模和评价进程。双击举办validation子流程,左边框是举办模子练习,这里选用K近邻要领,右边框是模子评价,拖入apply model和performance算子。
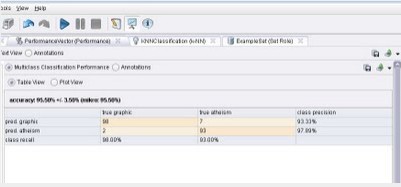
点击运行按钮,然后就可以看到功效。分类精确率为95.5%,照旧相当不错的。