欢迎各位阅读本篇,数据:在计算机系统中,各种字母、数字符号的组合、语音、图形、图像等统称为数据,数据经过加工后就成为信息。本篇文章讲述了当今数据对于我们的重要性。
一种新的大宗商品正在一个利润丰厚、增长迅猛的行业中酝酿,反垄断监管者也开始着手限制那些有能力控制这种商品的人。如果是在一个世纪前,这种商品就是石油。而现在,引发巨头们争相抢夺的变成了数据,也就是数字时代的石油。
包括 Alphabet(谷歌母公司)、亚马逊、苹果、Facebook 和微软在内的科技巨头似乎都势不可挡。他们是当今世界上市值最高的五大公司,他们的利润都在飙升,他们 2017 年第一季度共计实现净利润逾 250 亿美元。全美超过一半的在线开支都被亚马逊吸走,谷歌和 Facebook 去年几乎攫取了美国数字广告营收的全部增量。

如此强大的垄断地位引发了人们的警惕,很多人呼吁分拆这些公司,就像 20 世纪初对标准石油公司的分拆一样。本刊之前曾经反驳过这种激进观点。仅仅因为拥有庞大的规模并不构成犯罪。巨头的成功给消费者也带来了利益。没有几个人希望失去谷歌搜索引擎、亚马逊当日送达服务或者 Facebook 的 Newsfeed 信息流。
如果套用标准的反垄断程序,这些公司似乎也没有达到警戒线。这些公司非但没有剥削消费者,反而提供免费的服务(用户实际上是用自己的数据来换取服务)。考虑到数量庞大的线下竞争对手,他们的市场份额似乎也不足为惧。而 Snapchat 等新兴企业的崛起也表明,新一代公司也可以掀起一些波澜。
但我们仍有理由感到担忧。互联网公司对数据的控制使之掌握了巨大的权力。在数字经济中,石油时代沿袭下来的传统竞争思维似乎已经过时。需要采用新的思维模式。
数量与质量兼得
究竟出现了哪些变化?智能手机和互联网催生了海量数据,不仅无处不在,而且价值大幅提升。无论是跑步、看电视还是堵在车流中慢慢前行,几乎所有的活动都会留下数字足迹——从而贡献更多的原始数据以供分析。随着手表和汽车等更多设备接入互联网,数据量只会有增无减:有的人估计,无人驾驶汽车每秒将会产生 100GB 的数据。与此同时,人工智能技术也可以从数据中挖掘更多价值。
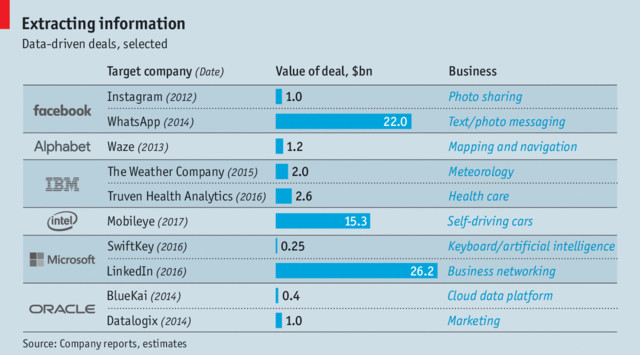
部分数据驱动的交易
算法可以预测消费者何时有意购物,飞机何时需要维护,某人何时生病。通用电气和西门子等工业巨头也都纷纷定位为数据公司。
海量的数据变化改变了竞争的特性。科技巨头始终受益于网络效应:注册 Facebook 的用户越多,就越能吸引其他人注册。而这些数据又会构成额外的网络效应。通过收集更多的数据,企业便可改进自家产品,从而吸引更多用户,甚至生成更多数据。
特斯拉收集的无人驾驶汽车数据越多,就越能改进无人驾驶——第一季度销量只有 2.5 万辆的特斯拉却能超过销量 230 万辆的通用汽车,一定程度上就源于此。海量数据可以充当企业的护城河。
数据也可以成为抵抗竞争对手的方式。在科技行业,人们之所以对竞争怀有期望,是因为某个车库里的创业公司可能击败老牌企业,也有可能出现意料之外的技术变革。但在数据时代,这两种可能性都大幅降低。
巨头的监控系统覆盖整个经济:谷歌可以看到人们搜索什么,Facebook 知道你在分享什么,亚马逊对你的购物习惯了如指掌。他们拥有应用商店、操作系统,还向创业公司出租计算资源。他们拥有“上帝之眼”,可以监控自己的市场和其他市场。他们能够看到哪些新产品和新服务受到追捧,因而能够及时模仿,甚至直接收购,避免遭遇更大的威胁。
很多人都认为,Facebook 在 2014 年斥资 220 亿美元收购员工总数不到 60 人的 Whatsapp,是为了消灭潜在竞争对手。通过竞争门槛和预警系统的恰当融合,便可借助数据有效遏制竞争。
改变反垄断思维
正是因为数据具备这些特性,才使得以往的反垄断措施效果降低。把谷歌分拆成 5 家公司不会阻止网络效应的扩张:假以时日,其中的一家公司仍会再次主导市场。因而需要辅以激进的思维——随着新的方法逐渐明确,两种想法逐渐进入人们的视野。
#p#分页标题#e#
第一种的关键在于,反垄断官员需要从工业化时代过渡到 21 世纪。例如,他们以往在评估并购交易时,都会根据规模来判断是否介入,但现在需要通过企业的数据资产来评估交易影响。交易价格也会成为一个信号,帮助其判断老牌企业是否在通过收购排除威胁。
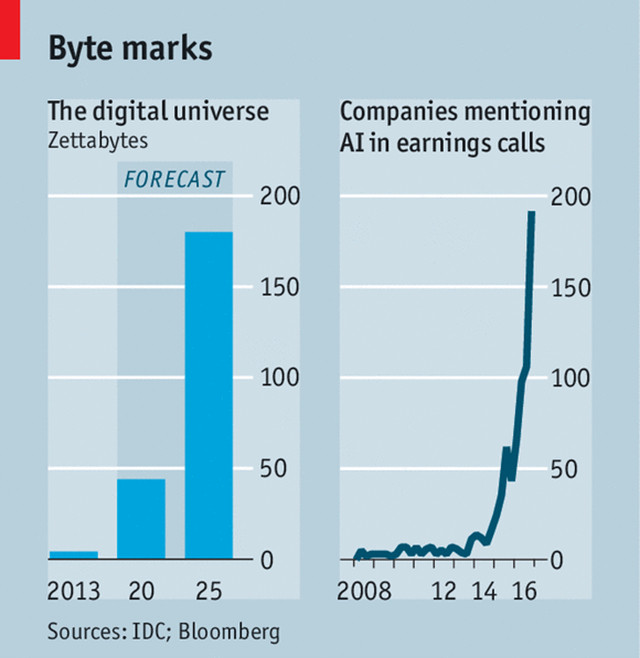
数字宇宙-在财报电话会议上提到“人工智能”的公司数量
例如,Facebook 愿意花这么高的价钱购买没有任何收入的 WhatsApp,就应该引起警惕。反垄断官员还应该在分析市场动态时更加重视数据,例如,可以使用模拟器来寻找串谋定价算法,从而最大程度地促进竞争。
第二种则是降低在线服务提供商对数据的控制权,让数据提供者掌握更大的控制权。提升透明度可以带来一定的帮助:可以强迫企业向消费者披露他们所拥有的数据,以及他们借此获取的收入。
政府可以鼓励企业开发新型服务,甚至开放更多的政府数据库,把数字经济的关键组成部分当做公共基础设施来对待,就像印度的数字身份系统 Aadhaar 一样。还可以在用户许可的情况下强制分享某些数据——欧洲就在金融服务领域采取了这种方式,要求银行向第三方开放用户数据。
在信息时代开展反垄断并非易事,而且还会引发新的风险:例如,分享的数据越多,隐私威胁就越大。但如果政府不希望数据经济被少数巨头垄断,就必须尽快采取行动。
知识分享:
数据仓库的层次
数据库的基本结构分三个层次,反映了观察数据库的三种不同角度。
(1)物理数据层。它是数据库的最内层,是物理存贮设备上实际存储的数据的集合。这些数据是原始数据,是用户加工的对象,由内部模式描述的指令操作处理的位串、字符和字组成。
(2)概念数据层。它是数据库的中间一层,是数据库的整体逻辑表示。指出了每个数据的逻辑定义及数据间的逻辑联系,是存贮记录的集合。它所涉及的是数据库所有对象的逻辑关系,而不是它们的物理情况,是数据库管理员概念下的数据库。
(3)逻辑数据层。它是用户所看到和使用的数据库,表示了一个或一些特定用户使用的数据集合,即逻辑记录的集合。
数据库的特点
数据库不同层次之间的联系是通过映射进行转换的。数据库具有以下主要特点:
(1)实现数据共享。数据共享包含所有用户可同时存取数据库中的数据,也包括用户可以用各种方式通过接口使用数据库,并提供数据共享。
(2)减少数据的冗余度。同文件系统相比,由于数据库实现了数据共享,从而避免了用户各自建立应用文件。减少了大量重复数据,减少了数据冗余,维护了数据的一致性。
(3)数据的独立性。数据的独立性包括数据库中数据库的逻辑结构和应用程序相互独立,也包括数据物理结构的变化不影响数据的逻辑结构。
(4)数据实现集中控制。文件管理方式中,数据处于一种分散的状态,不同的用户或同一用户在不同处理中其文件之间毫无关系。利用数据库可对数据进行集中控制和管理,并通过数据模型表示各种数据的组织以及数据间的联系。
(5)数据一致性和可维护性,以确保数据的安全性和可靠性。主要包括:①安全性控制:以防止数据丢失、错误更新和越权使用;②完整性控制:保证数据的正确性、有效性和相容性;③并发控制:使在同一时间周期内,允许对数据实现多路存取,又能防止用户之间的不正常交互作用;④故障的发现和恢复:由数据库管理系统提供一套方法,可及时发现故障和修复故障,从而防止数据被破坏。
