欢迎各位阅读本篇,从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分。大数据必然无法用单台的计算机进行处理,必须采用分布式架构。
这里的大数据道场是以HDP sandbox 为基础的,安装好了virtual box,导入了sandbox镜像之后,启动虚拟机,来看看我们的大数据道场吧。
访问方式
通过SSH的终端访问是不二之选
ssh [email protected] -p 2222
输入用户名/密码后就可以进入我们的道场主机了,命令交互与在一台ubantu Linux 主机上没什么不同。
如果不喜欢ssh,或者是windows的用户,也可以使用WEB Shell。 在浏览器中输入:
http://127.0.0.1:4200
如下图所示,与SSH 没有什么大的区别。
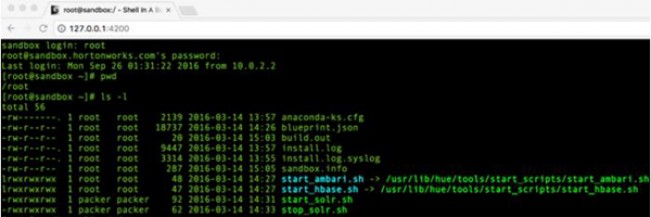
当然了,还可以从VM 的终端登录,按fn + alt +f5进入即可。
文件传输
在本机和sandbox 之间主要是通过SCP进行的。
本地文件复制到sandbox 中:
scp -P 2222 ~/Downloads/x.y.z [email protected]:/root
andbox 文件复制到本地:
scp -P 2222 [email protected]:/sandbox-dir-path/xyz /localpath
还可以通过虚拟机的共享目录实现,甚至在sandbox 上搭一个ftp server。
道场中的基础设施
Hadoop 发布版中比较有名的是CDH和HDP,两者的主要区别是CDH 通过Cloudera和hue 来管理集群及节点中的组件,而HDP是通过Ambri 完成的。
一般的,通过访问 http://127.0.0.1:8080 就可以通过Ambri 来浏览和管理。但是为了管理服务,需要以管理员的身份登录ambri。Sandbox 2.4 中需要通过执行脚本来重置ambri的管理员密码。
Abel-Mac-Pro:~ abel$ ssh [email protected] -p 2222 [email protected]'s password: Last login: Mon Sep 26 01:47:03 2016 [root@sandbox ~]# ambari-admin-password-reset Please set the password for admin: Please retype the password for admin: The admin password has been set. Restarting ambari-server to make the password change effective... Using Python /usr/bin/python2 Restarting ambari-server Using python /usr/bin/python2 Stopping ambari-server Ambari Server stopped Using python /usr/bin/python2 Starting ambari-server Ambari Server running with administrator privileges. Organizing resource files at /var/lib/ambari-server/resources... Server PID at: /var/run/ambari-server/ambari-server.pid Server out at: /var/log/ambari-server/ambari-server.out Server log at: /var/log/ambari-server/ambari-server.log Waiting for server start.................... Ambari Server 'start' completed successfully. [root@sandbox ~]#
现在,就可以用ambri的admin帐号登录,看看道场中的基础设施了。
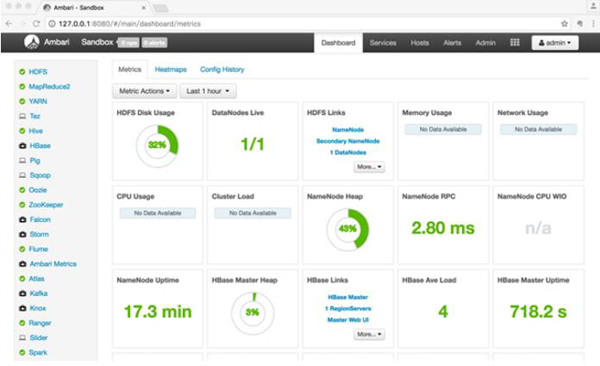
HDFS
HDFS 是Hadoop集群中数据存储的头等公民。数据在集群数据节点中自动复制。
MapReduce2
众所周知,mapreduce分为两个阶段,Map阶段:首先将输入数据进行分片,然后对每一片数据执行Mapper程序,计算出每个词的个数,之后对计算结果进行分组,每一组由一个Reducer程序进行处理,到此Map阶段完成。
Reduce阶段:每个Reduce程序从Map的结果中拉取自己要处理的分组(叫做Shuffling过程),进行汇总和排序(桶排序),对排序后的结果运行Reducer程序,最后所有的Reducer结果进行规约写入HDFS。
MapReduce2 是运行在YARN上的。
YARN
YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度。YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。
Tez
Tez是Apache最新的支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。Tez并不直接面向最终用户——事实上它允许开发者为最终用户构建性能更快、扩展性更好的应用程序。Tez产生的主要原因是绕开MapReduce所施加的限制。
Hive
Hive以类SQL方式简单而又强大地从HDFS中查询数据. 在用java写了10行代码的MapReduce地方,在Hive中, 只需要一条 SQL 查询语句.
HBase
#p#分页标题#e#
Hbase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”,是Google Bigtable的开源实现,利用Hadoop HDFS作为其文件存储系统。
Pig
Pig是一种数据流语言和运行环境,用于检索非常大的数据集。为大型数据集的处理提供了一个更高层次的抽象。Pig包括两部分:一是用于描述数据流的语言,称为Pig Latin;二是用于运行Pig Latin程序的执行环境。Pig 适合于使用 Hadoop 和 MapReduce 平台来查询大型半结构化数据集。通过允许对分布式数据集进行类似 SQL 的查询,Pig 可以简化 Hadoop 的使用。
Sqoop
Sqoop是一个从结构化数据库传说大量数据到HDFS. 使用它,既可以从一个外部的关系型数据库将数据导入到HDFS, Hive, 或者 HBase, 也可以Hadoop 集群导出到一个关系型数据库或者数据仓库.
Oozie
Oozie是一种Java Web应用程序,它运行在Java servlet容器——即Tomcat——中,并使用数据库来存储工作流定义和当前运行的工作流实例,包括实例的状态和变量。Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。
Zookeeper
Zookeeper 分布式服务框架主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
Falcon
Falcon 是一个面向Hadoop的、新的数据处理和管理平台,设计用于数据移动、数据管道协调、生命周期管理和数据发现。它使终端用户可以快速地将他们的数据及其相关的处理和管理任务“上载(onboard)”到Hadoop集群,可以减少应用程序开发和管理人员编写和管理复杂数据管理和处理应用程序的痛苦。
Storm
Storm是一个分布式高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域。
Flume
当查看生成的摄取日志的时候,可以使用Apache Flume; 它是稳定且高可用的,提供了一个简单,灵活和基于流数据的可感知编程模型。基本上,仅通过配置管理不需要写一行代码就可以陪着一个数据流水线。
Ambri Metrics
Ambari Metrics System 简称为 AMS,它主要为系统管理员提供了集群性能的监察功能。Metrics 一般分为 Cluster、Host 以及 Service 三个层级。Cluster 和 Host 级主要负责监察集群机器相关的性能,而 Service 级别则负责 Host Component 的性能。
Atlas
Atlas 是一个可伸缩和可扩展的核心功能治理服务。企业可以利用它高效的管理 Hadoop 以及整个企业数据生态的集成。核心功能包括:数据分类、集中审计、搜索、安全和策略引擎。
Kafka
Apache Kafka 是一个由Linkedin开发的订阅-发布消息的分布式应用。是一个持久化消息的高吞吐量系统 , 支持队列和话题语意, 使用 ZooKeeper形成集群节点。 详情参见kafka.apache.org.
Knox
knox是一个访问hadoop集群的restapi网关,它为所有rest访问提供了一个简单的访问接口点,能完成3A认证(Authentication,Authorization,Auditing)和SSO(单点登录)等。
Ranger
Ranger是一个hadoop集群权限框架,提供操作、监控、管理复杂的数据权限,它提供一个集中的管理机制,管理基于yarn的hadoop生态圈的所有数据权限。
Slider
Slider 是一个 Yarn 应用,它可以用来在 Yarn 上部署并监控分布式应用。Slider 可以在应用运行期随意扩展或者收缩应用。Slider工具是一个Java的命令行应用,它会把信息持久化为JSON文档并存储到HDFS。当集群启动后,我们可以使用命令扩展或者收缩集群。集群也可以被停止或者重启。
Spark
Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架。Spark为我们提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求。Spark则允许程序开发者使用有向无环图(DAG)开发复杂的多步数据管道。而且还支持跨有向无环图的内存数据共享,以便不同的作业可以共同处理同一个数据。
#p#分页标题#e#
Spark运行在现有的Hadoop分布式文件系统基础之上(HDFS)提供额外的增强功能。它支持将Spark应用部署到现存的Hadoop v1集群(with SIMR – Spark-Inside-MapReduce)或Hadoop v2 YARN集群甚至是Apache Mesos之中。
Zeppelin Notebook
Zeppelin提供了web版的类似ipython的notebook,用于做数据分析和可视化。背后可以接入不同的数据处理引擎,包括spark, hive, tajo等,原生支持Scala, java, shell, markdown等。Zeppelin 提供了内置的 Apache Spark 集成。Zeppelin的Spark集成提供了:
自动引入SparkContext 和 SQLContext
从本地文件系统或maven库载入运行时依赖的jar包。更多关于依赖载入器
可取消job 和 展示job进度
HDP Sandbox 默认为我们提供了如此多的组件服务,几乎涵盖了hadoop 生态系统,完了么?没有,还可以用管理员的身份来增加/启动/关闭 服务,例如Accumulo,Mahout,NiFi,Ranger KMS,SmartSense等,甚至可以自定义服务的。
知识分享:
处理流程
数据采集
定义:利用多种轻型数据库来接收发自客户端的数据,并且用户可以通过这些数据库来进行简单的查询和处理工作。
特点和挑战:并发系数高。
使用的产品:MySQL,Oracle,HBase,Redis和 MongoDB等,并且这些产品的特点各不相同。
统计分析
大数据定义:将海量的来自前端的数据快速导入到一个集中的大型分布式数据库 或者分布式存储集群,利用分布式技术来对存储于其内的集中的海量数据 进行普通的查询和分类汇总等,以此满足大多数常见的分析需求。
特点和挑战:导入数据量大,查询涉及的数据量大,查询请求多。
使用的产品:InfoBright,Hadoop(Pig和Hive),YunTable, SAP Hana和Oracle Exadata,除Hadoop以做离线分析为主之外,其他产品可做实时分析。
挖掘数据
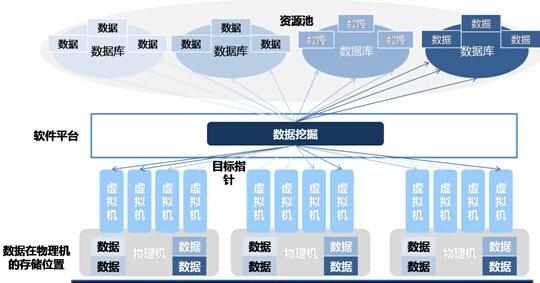
定义:基于前面的查询数据进行数据挖掘,来满足高级别 的数据分析需求。
特点和挑战:算法复杂,并且计算涉及的数据量和计算量都大。
使用的产品:R,Hadoop Mahout
小结:大数据的特色在于对海量数据进行分布式数据挖掘,但它必须依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术。
