在众多学习中,文章也许不起眼,但是重要的下面我们就来讲解一下!!
微软宣布了新的 Azure 数据湖(Azure Data Lake)服务,该服务被用于云分析,包括了一个超大规模信息库;一个在 Yarn上建立的新的的分析服务,该服务允许数据开发者和数据科学家分析全部的数据;还有 HDInsight,一个全面管理 Hadoop、Spark、Storm 和 Hbase 的服务。Azure 数据湖分析包括 U-SQL,这个语言综合了 SQL 的优点与你自己所写代码的表现能力。U-SQL 的可扩展分布式查询功能让你可以有效地分析存储器或关联存储器(比如 AzureSQL 数据库(Azure SQL Database))内的数据。这篇博文中,我将会概述 U-SQL 的开发目标、我们的一些灵感和这个语言背后的设计理念,同时我会向你展示一些用于说明这个语言几个主要方面的例子。

为什么我们需要 U-SQL?
如果你分析了的大数据分析的特点,就会很容易的产生一些有关易用性的需求,一个功能强大的语言应该:
可以处理任何类型的数据。例如从安全日志中分析僵尸网络(BotNet)攻击模式,通过机器学习来提取图像和视频中的特征,这种语言需要允许你操作任何类型的数据。
使用自定义的代码很容易地表现复杂的(经常是表现某公司自营业务的)算法。举例来说,基础的查询语言通常不易表达自定义的过程,从用户定义的函数到他们自定义的输入输出格式都是如此。
对任何尺度的数据进行有效的缩放,你无须再关心扩展拓扑(scale-out topology)、管道代码或特定分布式基础设施的限制。
现有的大数据语言该如何处理这些需求?
基于 SQL 的语言(例如 Hive 等)提供声明性的方式,原生支持扩容,并行执行以及优化。这个特性使得其简单易用,被开发人员广泛使用;其功能强大,适用于很多标准的分析及仓储类型。不过他们的扩展模型和对非结构化数据及文件的支持经常只是些附属功能,不容易使用。比如,即使您只想快速浏览一下文件或者远程数据,您也需要在查询之前先创建编目对象,将其系统化。这点严重降低了语言的敏捷性。虽然基于 SQL 的语言通常有一些扩展点来定制格式,定义函数以及聚合,但是他们的构建,集成和维护相当复杂,各种编程语言的支持也差别很大。
用基于编程语言的方式来处理大数据,这样方式可以简单方便地添加定制化代码。但是,程序员通常需要另外编写代码来处理扩容和性能,并且难以管理执行拓扑和工作流。比如不同执行阶段的并发或者架构扩容。这样的代码不仅难写,而且不易优化性能。有些框架支持声明式组件,例如集成语言查询,或者嵌入式 SQL 支持。但是 SQL 可能会被当做字符串处理,没有辅助工具。并且可扩展性集成较差,由于程序性代码并不考虑副作用,所以较难优化,而且不能重用。
综合考虑基于 SQL 的语言以及程序语言,我们设计出了 U-SQL,他用 C# 编写,具备声明性 SQL 语言原生的可扩展性,又对其进一步扩展。集各种范式于一身,集结构化,非结构化,远程数据处理于一身,集声明式以及定制化命令编程于一身,集语言扩展能力于一身。
U-SQL 构建在微软的 SCOP 经验以及其他语言例如 T-SQL,ANSI SQL 以及 Hive 的基础之上。例如,我们对 SQL 和编程语言的集成,执行以及对 U-SQL 框架的优化都基于 SCOPE,这使得每天可以运行成千上万个作业。我们也会对调整系统元数据(数据库,表等等),SQL 语法,T-SQL,ANSI SQL 等 SQL Server 用户所熟悉的语言语义等支持,是的他们可以协同通过。 我们使用C#数据类型即表达式支持,这样您可以在 SELECT 里无缝潜入 C# 谓词及表达式,从而植入业务逻辑。最后,通过对 Hive 以及其他大数据语言数据模式,处理需求等研究,将其集成到我们的框架里。
简言之,基于现有语言和经验的 U-SQL 语言,有利于您简单地处理复杂问题。
展示 U-SQL!oracle数据库教程
我们假设我已经下载了所有我的 Twitter 历史记录,包括:我推送的,转发的,提到的。并且作为一个 CSV 文件上传到我的 Azure Data Lake Store。
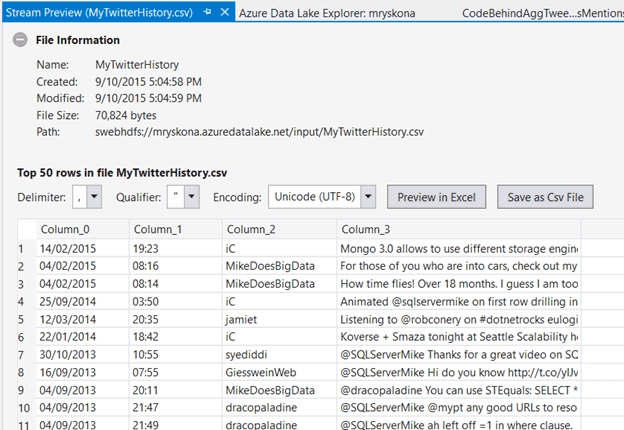
在这里例子里,我知道我想要处理数据的结构,第一步我只想分组查询出每个作者的推送数据的数量:
上面的 U-SQL 脚本显示了三个使用 U-SQL 处理数据的主要步骤:
#p#分页标题#e#
注意 U-SQL 的 SQL 关键字和 C# 的语法表达式的区别是使用大写来提供语法区别,可能两者是一样的,但是如果大写就是 U-SQL 的关键字,他们的文字一样但是可能有不同的意义。
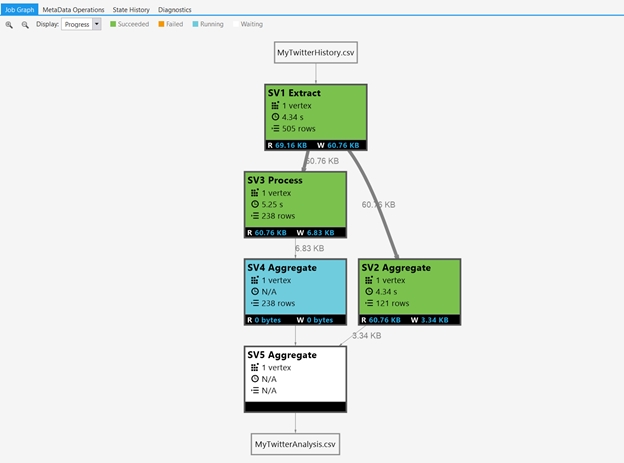
还要注意每个表达式分配了一个变量 (@t , @res)。允许 U-SQL 通过一步步的表达式(增量表达式流),递增的转换和编译数据,增量表达式是使用函数式 lambda 表达式组成(与 Pig 语言类似)。执行框架,并且编译所有的表达式为一个的表达式。这个表达式可以是全局最优化,所以扩展的方式不可能是逐行执行表达式。下面的图标通过向你显示图表的方式,显示在这篇博文中的下一个查询:
 oracle视频教程
oracle视频教程
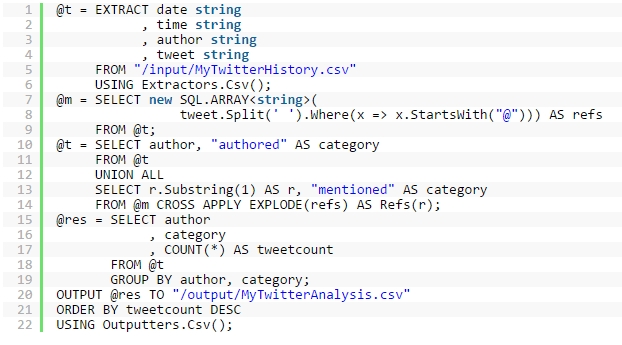
回到我们的例子,我现在想要添加额外的信息:关于推文中提及的人,并且扩展我的聚合去返回在我的 tweet 网中出现的频率,还有他们的推文中提及我的频率。因为我可以使用 C# 去操作数据,所以我可以使用 C#LINQ 表达式扩展一个 ARRAY。这时我把得到的数组使用 EXPLODE 传入数据集,并且使用 CROSS APPLY 操作应用 EXPLODE 到每条数据。我使用 UNION 操作联合作者,但是需要使用@重新给变量赋值。
经李克强总理签批,2015年9月,国务院印发《促进大数据发展行动纲要》(以下简称《纲要》),系统部署大数据发展工作。
《纲要》明确,推动大数据发展和应用,在未来5至10年打造精准治理、多方协作的社会治理新模式,建立运行平稳、安全高效的经济运行新机制,构建以人为本、惠及全民的民生服务新体系,开启大众创业、万众创新的创新驱动新格局,培育高端智能、新兴繁荣的产业发展新生态。
《纲要》部署三方面主要任务。一要加快政府数据开放共享,推动资源整合,提升治理能力。大力推动政府部门数据共享,稳步推动公共数据资源开放,统筹规划大数据基础设施建设,支持宏观调控科学化,推动政府治理精准化,推进商事服务便捷化,促进安全保障高效化,加快民生服务普惠化。二要推动产业创新发展,培育新兴业态,助力经济转型。发展大数据在工业、新兴产业、农业农村等行业领域应用,推动大数据发展与科研创新有机结合,推进基础研究和核心技术攻关,形成大数据产品体系,完善大数据产业链。三要强化安全保障,提高管理水平,促进健康发展。健全大数据安全保障体系,强化安全支撑。[8]
oracle视频
2015年9月18日贵州省启动我国首个大数据综合试验区的建设工作,力争通过3至5年的努力,将贵州大数据综合试验区建设成为全国数据汇聚应用新高地、综合治理示范区、产业发展聚集区、创业创新首选地、政策创新先行区。
围绕这一目标,贵州省将重点构建“三大体系”,重点打造“七大平台”,实施“十大工程”。
“三大体系”是指构建先行先试的政策法规体系、跨界融合的产业生态体系、防控一体的安全保障体系;“七大平台”则是指打造大数据示范平台、大数据集聚平台、大数据应用平台、大数据交易平台、大数据金融服务平台、大数据交流合作平台和大数据创业创新平台;“十大工程”即实施数据资源汇聚工程、政府数据共享开放工程、综合治理示范提升工程、大数据便民惠民工程、大数据三大业态培育工程、传统产业改造升级工程、信息基础设施提升工程、人才培养引进工程、大数据安全保障工程和大数据区域试点统筹发展工程。
这里使用另外一个C#表达式(这里我使用了substring从第一位开始取数据-翻译认为应该是排除@符的意思) .
下一步,我可以使用 Visual Studio 的 Azure 数据湖工具里的代码转换功能将 C# 代码重构成 C# 函数。提交脚本后,系统会将代码自动部署到服务器上。
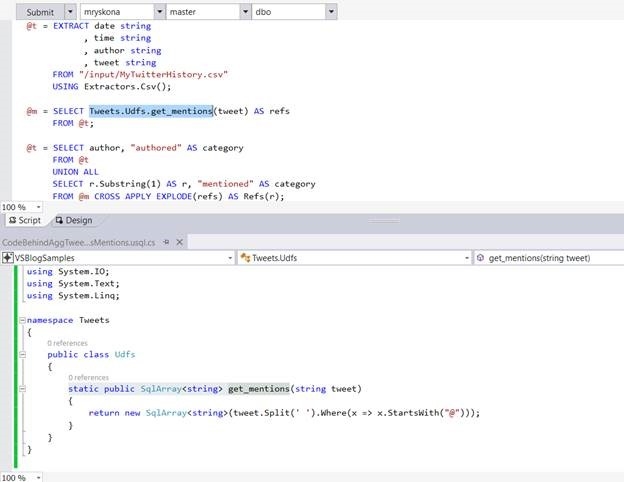
我们也可以在U-SQL元数据目录里部署和注册代码集。这样,我们或者其他人可以不时重用这组脚本。以下例子表示了,在代码集注册为TweetAnalysis之后,如何找到函数。
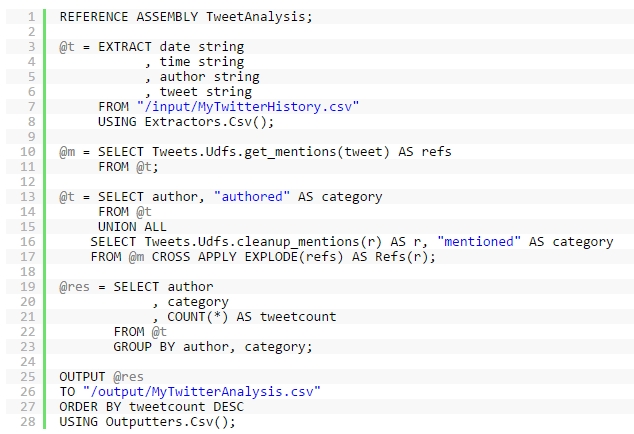
由于之前提到了除了删除@标识符之外,还想要对 mentions 做其他清理工作,所以该代码集还包含了一个 cleanup_mentions 函数,用来在删除@之后做其他处理。Oracle培训
为什么选择U-SQL
#p#分页标题#e#
通过上述介绍,希望您已经窥测到了我们对 U-SQL 的想法,以及 U-SQL 是如何将查询以及大数据处理变得简单的。接下来的几周里,我们会进一步介绍该语言的设计逻辑,并会给出一些示例代码即应用场景,请参见Azure 博客大数据专题。我们会深入探讨一下特性:
U-SQL 将大数据处理变得简单:
不只是 U-SQL – Auzre 数据湖为您的所有数据创建生产力
我们旨在将 Azure 数据湖建立成最有用的集编写,调试和优化各种规模数据功能的强大工具,U-SQL只是其中一个环节。通过对编写与监控 Hive 作业的全面支持, 我们开发了基于 C# 的编码模型,他可以创建用于流处理的 Storm 作业,而且从创建,到执行,支持作业生命周期的每一阶段。Azure 数据湖使得您可以专心于业务逻辑而不是调试分布式环境。我们的目标就是将大数据技术变得更加简单,被更多数人使用:大数据专家,工程师,数据科学家,分析师以及应用开发人员。
更多视频课程文章的课程,可到课课家官网查看。我在等你哟!!
