我们一般提到排序都是指内排序,比如快排、堆排序、归并排序等,所谓的内排序就是把所有待排序的数据外进内存之中,比如,一个数组之中。但是如果文件太大,文件中的所有数据不能一次性的放入内存之中,快排,堆排序,归并排序等内排序就无法工作了。在这种情况下,我们使用外排序。下面我们就来讲解外排序,需要的朋友可以参考学习!
外排序(External sorting)是指能够处理极大量数据的排序算法。通常来说,外排序处理的数据不能一次装入内存,只能放在读写较慢的外存储器(通常是硬盘)上。外排序通常采用的是一种“排序-归并”的策略。在排序阶段,先读入能放在内存中的数据量,将其排序输出到一个临时文件,依此进行,将待排序数据组织为多个有序的临时文件。尔后在归并阶段将这些临时文件组合为一个大的有序文件,
一般来说外排序分为两个步骤:预处理和合并排序。即首先根据内存的大小,将有n个记录的磁盘文件分批读入内存,采用有效的内存排序方法进行排序,将其预处理为若干个有序的子文件,这些有序子文件就是初始顺串,然后采用合并的方法将这些初始顺串逐趟合并成一个有序文件。
预处理阶段最重要的事情就是选择初始顺串。通常使用的方法为置换选择排序,它是堆排序的一种变形,实现思路同STL的partial_sort。步骤如下:
1.初始化堆
(1)从磁盘读入M个记录放到数组RAM中
(2)设置堆末尾标准LAST=M-1
(3)建立最小值堆
2.重复以下步骤知道堆为空
(1)把具有最小关键码值的记录Min也就是根节点送到输出缓冲区
(2)设R是输入缓冲区中的下一条记录,如果R的关键码大于刚刚输出的关键码值Min,则把R放到根节点,否则使用数组中LAST位置的记录代替根节点,并将刚才的R放入到LAST所在位置,LAST=LAST-1;
3.重新排列堆,筛出根节点
如果堆的大小是M,一个顺串的最小长度就是M个记录,因为至少原来在堆中的那些记录将成为顺串的一部分,如果输入时逆序的,那么顺串的长度只能是M,最好情况输入是正序的,有可能一次性就能把整个文件生成一个顺串,由此可见生成顺串的长度是大小不一的,但是每个顺串却是有序的,利用扫雪机模型能够得到平均顺串的长度为2M。
得到顺串之后呢,就开始进行归并了。二路归并的缺点是扫描次数太多,因为如果顺串的个数为m个,那么二路归并的扫描次数就是log(2,m),采用多路归并可以减少扫描次数,一般情况下使用选择树来进行多路归并。选择树有赢者树和败者树2种,赢者树比较直观,但是每次调整需要改动比较大,所以一般情况下都用败者树,所谓败者树就是非叶子节点的值都是两个子结点中的败者对应的值。这句话其实说的比较含糊,真正生成败者树的过程是每次都将败者放在父节点上,同时胜者继续比较,胜者中的败者再放在父节点上,再记录下此时的胜者继续比较……比赛的过程:将新进入树的节点与其父节点进行比赛,将败者存放在父节点,而胜者再与上一级的父节点继续比赛……因此从这个过程也可以看出,其实败者树只会改变一个分支,不会影响到其他,因而重构的代价比较小。
需要归并的趟数就是log(b,m),b为几路归并,m为顺串的个数。产生一个大小为n的顺串时间为O(k+nlogk)。使用最佳归并可以减少输入/输出量。
可以从下面的一个例子来看外排序中的归并是如何进行的?
段都含1000 个记录。然后对它们作如图所示的两两归并,直至得到一个有序文件为止,如下图
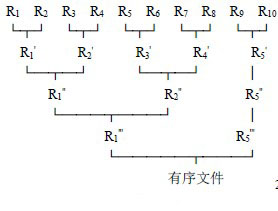
从上图可见,由10 个初始归并段到一个有序文件,共进行了四趟归并,每一趟将两个有序段归并成一个有序段的过程,在外部排序中实现两两归并时,不仅要调用Merge 函数,而且要进行外存的读/写,这是由于我们不可能将两个有序段及归并结果同时放在内存中的缘故。对外存上信息的读/写是以“物理块”为单位。假设在上例中每个物理块可以容纳200 个记录,则每一趟归并需进行50 次“读”和50 次“写”,四趟归并加上内部排序时所需进行的读/写,使得在外排序中总共需进行500 次的读/写。
今天的内容就讲解到这,如果有什么不对之处,欢迎赐教。
外排序指的的是什么?
最后更新 2018-05-16 08:00 星期三 所属:
大数据教程 浏览:764
