CS 188
Introduction to Artifificial Intelligence
Practice Final
人工智能考试代写 Q1. Agent Testing Today! It’s testing time! Not only for you, but for our CS188 robots as well! Circle your favorite robot below.
Q1. Agent Testing Today!
It’s testing time! Not only for you, but for our CS188 robots as well! Circle your favorite robot below.

Q2.Search 人工智能考试代写
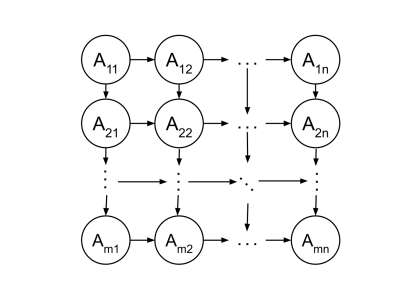
(a)
Considerthe class of directed, m × n grid graphs as illustrated (We assume that m, n > 2.) Each edge has a cost of 1. The start state is A11 at top left and the goal state at Amn is bottom right.
(i)If we run Uniform-Cost graph search (breaking ties randomly), what is the maximum possible size of the fringe? Write your answer in terms of m and n in big-O style, ignoring constants. For example, if you think the answer is m3n3+ 2, write m3n3.
(ii)If we run Depth-First graph search with a stack, what is the maximum possible size of the stack?
(b)
Now answer the same questions for undirected m × n grid graphs (i.e., the links go in both directions between neighboring nodes).
(i) Maximum fringe size for Uniform-Cost graph search?
(ii) Maximum stack size for Depth-First graph search?
(c) 人工智能考试代写
Thefollowing questions are concerned with an undirected grid graph tt and with Manhattan distance d((i, j), (k, l)) = |i − k| + |j − l|. Now the start and goal locations can be anywhere in the graph.
(i) True/False:
Let G+ be a copy of tt with n extra links added with edge cost 1 that connect arbitrary non-adjacent nodes. Then Manhattan distance is an admissible heuristic for finding shortest paths in G+
(ii)True/False:
Let G−be a copy of G with n arbitrarily chosen links deleted, and let h+(s, t) be the exact cost of the shortest path from location s to location t in G+. Then h+( , g) is an admissible heuristic for finding shortest paths in G− when the goal is location g.
(iii)Suppose that K robots are at K different locations (xk, yk) on the complete grid tt, and can move simultaneously. The goal is for them all to meet in one location as soon as possible, subject to the constraint that if two robots meet in the same location en route, they immediately settle down together and cannot move after that. Define dX to be the maximum x separation, i.e., | max{x1, . . . , xK} − min{x1, . . . , xK}|, with dY defifined similarly. Which of the following is the most accurate admissible heuristic for this problem?
□ (Select one only.)
□ |dX/2| + |dY /2|
□ dX + dY
□ |dX/2| + |dY /2| + K/4
□ max{|dX/2|, |dY /2|, K/4}
□ max{|dX/2| + |dY /2|, K/4}
Q3. Pacman’s Treasure Hunt 人工智能考试代写
Pacman is hunting for gold in a linear grid-world with cells A, B, C, D. Cell A contains the gold but the entrance to A is locked. Pacman can pass through if he has a key. The possible states are as follows: Xk means that Pacman is in cell X and has the key; X−k means that Pacman is in cell X and does not have the key. The initial state is always C−k.
In each state Pacman has two possible actions, left and right. These actions are deterministic but do not change the state if Pacman tries to enter cell A without the key or run into a wall (left from cell A or right from cell D). The key is in cell D and entering cell D causes the key to be picked up instantly.
If Pacman tries to enter cell A without the key, he receives a reward of -10, i.e. R(B−k, lef t, B−k) = 10. The “exit” action from cell A receives a reward of 100. All other actions have 0 reward.
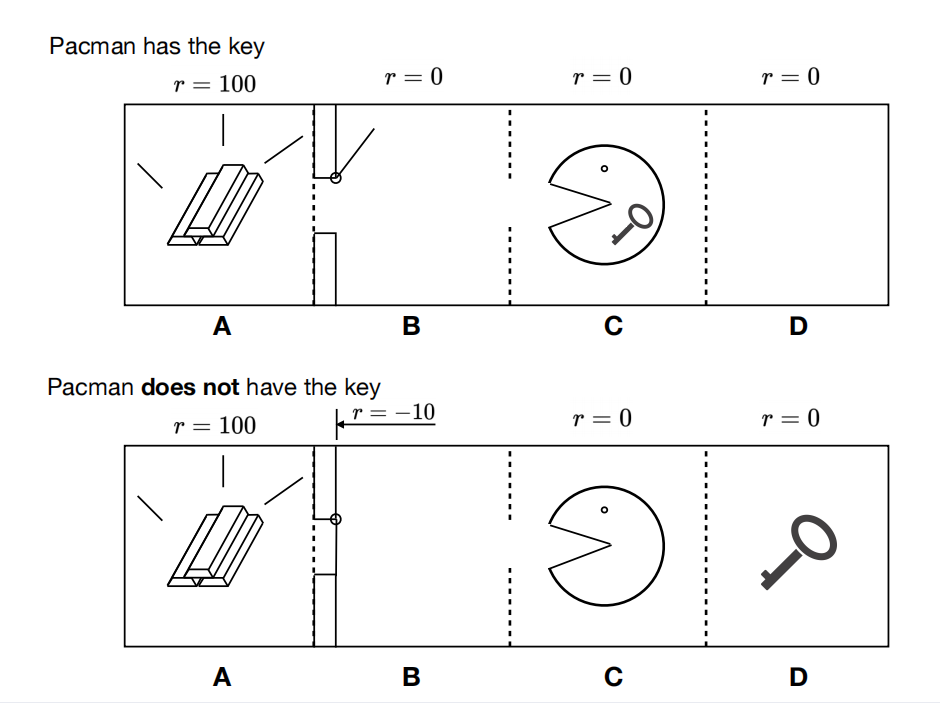
(a)Consider the discount factor γ = 0.1 and the followingpolicy:
| State | Ak | Bk | Ck | Dk | A−k | B−k | C−k | D−k |
| Action | exit | left | left | left | exit | left | right | right |
Fill in V π(B−k) and V π(C−k) for this policy in the table below.
|
State |
Ak |
Bk |
Ck |
Dk |
A−k |
B−k |
C−k |
D−k |
|
V π(s) |
100 |
10 |
1 |
0.1 |
100 |
0 |
(b) 人工智能考试代写
Now, we will redefifine the MDP so that Pacman has a probability β ∈ [0, 1], on each attempt, of crashing through the gate even without the key. So our transition function from B will be modifified as follows:
T (B−k, lef t, A−k) = β and T (B−k, lef t, B−k) = 1 − β.
All other aspects remain the same. The immediate reward for attempting to go through the gate is 10 if Pacman fails to go through the gate, as before, and 0 if Pacman succeeds in crashing through gate. Which of the following are true? (Select one or more choices.)
□ For any fixed γ < 1, there is some value β < 1 such that trying to crash through the gate is better than fetching the key.
□ For any fixed β, there is some value of γ < 1 such that trying to crash through the gate is better than fetching the key.
□ For β = 1/2 , there is some value of γ < 1 such that trying to crash through the gate is better than fetching the key.
□ None of the above
(c)
Thus far we’ve assumed knowledge of the transition function T (s, a, s’). Now let’s assume we donot.
(i) Which of the following can be used to obtain a policy if we don’t know the transitionfunction?
□ Value Iteration followed by Policy Extraction
□ Approximate Q-learning
□ TD learning followed by Policy Extraction
□ Policy Iteration with a learned T (s, a, s’)
(ii)Under which conditions would one benefit from using approximate Q-learning over vanilla Q- learning? (Select oneonly)
□ When the state space is very high-dimensional
□ When the transition function is known
□ When the transition function is unknown
□ When the discount factor is small
(iii)Suppose we choose to use Q-learning (in absence of the transition function) and we obtain the followingobservations:
| st | a | st+1 | reward |
| Ck | left | Bk | 0 |
| Bk | left | Ak | 0 |
| Ak | exit | terminal | 100 |
| B−k | left | B−k | -10 |
What values does the Q-function attain if we initialize the Q-values to 0 and replay the experience in the table exactly two times? Use a learning rate, α, of 0.5 and a discount factor, γ, of 0.1.

(d)
Suppose we want to defifine the (deterministic) transition model using propositional logic instead of a table. States are defifined using proposition symbols be At, Bt, Ct, Dt and Kt, where, e.g., At means that Pacman is in cell A at time t and Kt means that the Pacman has the key. The action symbols are Leftt, Rightt, Exitt.
(i)Which of the following statements are correct formulations of the successor-state axiom for At?
□ At ⇔ (At−1 ⇒ (Leftt−1 ∧ Bt−1 ∧ Kt−1)
□ At ⇔ (At ∧ Leftt) ∨ (Bt−1 ∧ Leftt−1 ∧ Kt−1)
□ At ⇔ (At−1 ∧ Leftt−1) ∨ (Bt−1 ∧ Leftt−1 ∧ Kt−1)
□ At ⇔ (At−1 ∧ Leftt−1) ∨ (Bt ∧ Leftt ∧ Kt)
□ At ⇔ (At−1 ∧ Leftt−1) ∨ (Bt−1 ∧ Leftt−1 ∧ ¬Kt−1)
(ii)Which of the following statements are correct formulations of the successor-state axiom for Kt?
□ Kt⇔ Kt−1∧ (Ct−1 ∨ Rightt-1)
□ Kt ⇔ Kt ∨ (Ct ∧ Rightt)
□ Kt ⇔ Kt−1 ∨ (Ct−1 ∧ Rightt-1)
□ Kt ⇔ Kt−1 ∨Dt−1
Q4. Inexpensive Elimination 人工智能考试代写
In this problem, we will be using the Bayes Net below. Assume all random variables are binary-valued.
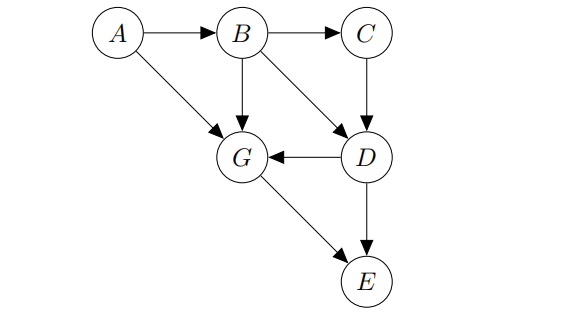
(a)
Consider using Variable Elimination to get P(C, G|D = d).
What is the factor generated if B is the fifirst variable to be eliminated? Comma-separate all variables in the resulting factor, e.g., f(A, B, C), without conditioned and unconditioned variables. Alphabetically order variables in your answer. E.g., P(A) before P(B), and P(A|B) before P(A|C).
f (____) = ∑b ____________________
(b)
Suppose we want to find the optimal ordering for variable elimination such that we have the smallest sum of factor sizes. Recall that all random variables in the graph are binary-valued (that means if there are two factors,one over two variables and another over three variables, the sum of factor sizes is 4+8=12).
In order to pick this ordering, we consider using A* Tree Search. Our state space graph consists of states which represent the variables we have eliminated so far, and does not take into account the order which they are eliminated. For example, eliminating B is a transition from the start state to state B, then eliminating A will result in state AB. Similarly, eliminating A is a transition from the start
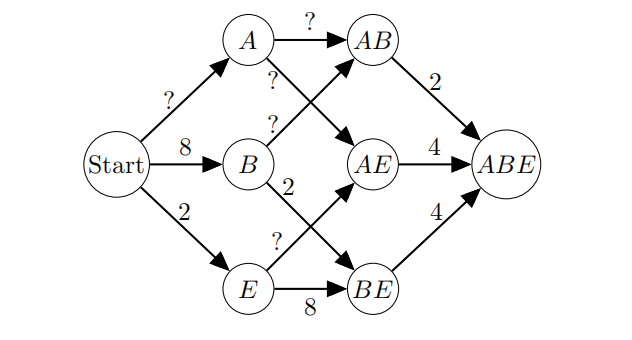
(i) Yes/No:
As the graph is defifined, we have assumed that difffferent elimination orderings of the same subset of random variables will always produce the same fifinal set of factors. Does this hold for all graphs?
(ii) For this part, we consider possible heuristics h(s), for a generic Bayes Net which has N variables left to eliminate at state s. Each remaining variable has domain size D.
Let the set E be the costs of edges from state s (e.g. for s = A, E is the costs of edges from A to AE, and A to AB). Which of the following would be admissible heuristics?
□ min E
□ 2 min E
□ max E
□ max (E)/N
□ N ∗ D
□ None are admissible
(c)
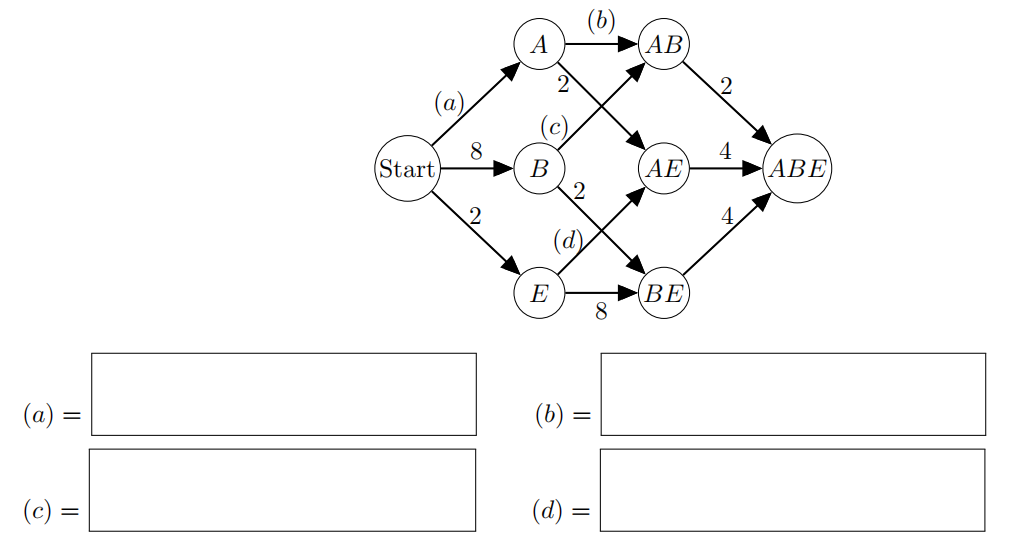
Now let’s consider A* tree search on our Bayes Net for the query P(C, G|D = d), where d is observed evidence.
Fill in the edge weights (a) − (d) to complete the graph.
Q5. Sampling 人工智能考试代写
Variables H, F, D, E and W denote the event of being health conscious, having free time, following a healthy diet, exercising and having a normal body weight, respectively. If an event does occur, we denote it with a +, otherwise −, e.g., +e denotes an exercising and −e denotes not exercising.
- A person is health conscious with probability 0.8.
- A person has free time with probability 0.4.
- If someone is health conscious, they will follow a healthy diet with probability 0.9.
- If someone is health conscious and has free time, then they will exercise with probability 0.9.
- If someone is health conscious, but does not have free time, they will exercise with probability 0.4.
- If someone is not health conscious, but they do have free time, they will exercise with probability 0.3.
- If someone is neither health conscious, nor they have free time, then they will exercise with probability 0.1.
- If someone follows both a healthy diet and exercises, they will have a normal body weight with probability 0.9.
- If someone only follows a healthy diet and does not exercise, or vice versa, they will have a normal body weight with probability 0.5.
- If someone neither exercises nor has a healthy diet, they will have a normal body weight with probability 0.2.

(b)
Suppose we want to estimate the probability of a person being normal body weight given that they exercise (i.e. P(+w| + e)), and we want to use likelihood weighting.
(i) We observe the following sample: (−w, −d, +e, +f, −h). What is our estimate of P(+w| + e) given this one sample? Express your answer in decimal notation rounded to the second decimal point, or express it as a fraction simplifified to the lowest terms.
(ii) Now, suppose that we observe another sample: (+w, +d, +e, +f, +h). What is our new estimate for P(+w|+e)? Express your answer in decimal notation rounded to the second decimal point, or express it as a fraction simplifified to the lowest terms.
(iii) True/False:
After 10 iterations, both rejection sampling and likelihood weighting would typically compute equally accurate probability estimates. Each sample counts as an iteration, and rejecting a sample counts as an iteration.
(c) 人工智能考试代写
Suppose we now want to use Gibbs sampling to estimate P(+w| + e)
(i) We start with the sample (+w, +d, +e, +h, +f), and we want to resample the variable W. What is the probability of sampling (−w, +d, +e, +h, +f)? Express your answer in decimal notation rounded to the second decimal point, or express it as a fraction simplifified to the lowest terms.
(ii) Suppose we observe the following sequence of samples via Gibbs sampling:
(+w, +d, +e, +h, +f),(−w, +d, +e, +h, +f),(−w, −d, +e, +h, +f),(−w, −d, +e, −h, +f)
What is your estimate of P(+w| + e) given these samples?
(iii) While estimating P(+w| + e), the following is a possible sequence of sample that can be obtained via Gibbs sampling:
(+w, +d, +e, +h, +f),(−w, +d, +e, +h, +f),(−w, −d, +e, +h, +f),(−w, −d, +e, −h, +f),(−w, −d, −e, −h, +f)
Q6.Partying Particle #No Filter(ing)

Algorithm 1 outlines the particle fifiltering algorithm discussed in lecture. The variable x represents a list of N particles, while w is a list of N weights for those particles.
(a)
Here, we consider the unweighted particles in x as approximating a distribution.
(i) After executing line 4, which distribution do the particles x represent?
□ P (Xt+1|E1:t)
□ P (X1:t+1|E1:t)
□ P (Xt+1|E1:t+1)
□ None
(ii) After executing line 6, which distribution do the particles x represent?
□ P (Xt+1|Xt, E1:t+1)
□ P (X1:t+1|E1:t+1)
□ P (Xt+1|E1:t+1)
□ None
(b) 人工智能考试代写
The particle fifiltering algorithm should return a sample-based approximation to the true posterior distribution P (XT E1:T ). The algorithm is consistent if and only if the approximation converges to the true distribution as N → ∞. In this question, we present several modififications to Algorithm 1. For each modifification, indicate if the algorithm is still consistent or not consistent, and if it is consistent, indicate whether you expect it to be more accurate in general in terms of its estimate of P(XT E1:T ) (i.e., you would expect the estimated distribution to be closer to the true one) or less accurate. Assume unlimited computational resources and arbitrary precision arithmetic.
(i)
We modify line 6 to sample 1 or 2N − 1 particles with equal probability p = 0.5 for each time step (as opposed to a fixed number of particles N). You can assume that P(Et+1 Xt+1) > 0 for all observations and states. This algorithm is:
□ Consistent and More Accurate
□ Consistent and Less Accurate
□ Not Consistent
(ii) Replace lines 4–6 as follows:
4‘ : Compute a tabular representation of P(Xt = s E1:t) based on the proportion of particles in state s.
5‘ : Use the forward algorithm to calculate P(Xt+1 E1:t+1) exactly from the tabular representation.
6‘ : Set x to be a sample of N particles from P(Xt+1 E1:t+1).
This algorithm is:
□ Consistent and More Accurate
□ Consistent and Less Accurate
□ Not consistent
(iii) 人工智能考试代写
At the start of the algorithm, we initialize each entry in w to 1s. Keep line 4, but replace lines 5 and 6 with the following multiplicative update:
5‘ : For i = 1, . . . , N do
6‘ wi wi P (Et+1 Xt+1 = xi).
Finally, only at the end of the T iterations, we resample x according to the cumulative weights w just like in line 6, producing a list of particle positions. This algorithm is:
□ Consistent and More Accurate
□ Consistent and Less Accurate
□ Not Consistent
(c)
Suppose that instead of particle fifiltering we run the following algorithm on the Bayes net with T time steps corresponding to the HMM:
1.Fix all the evidence variables E1:T and initialize each Xt to a random value xt.
2.For i = 1, . . . , N do
- Choose a variable Xt uniformly at random fromX1, . . . , XT .
- Resample Xt according to the distribution P(Xt|Xt−1 = xt−1, Xt+1 = xt+1, Et = et).
- Record the value of XT as a sample.
Finally, estimate P(XT = s|E1:T = e1:T ) by the proportion of samples with XT = s. This algorithm is:
□ Consistent
□ Not Consistent
Q7. Double Decisions and VPI 人工智能考试代写
In both parts of this problem, you are given a decision network with two decision nodes: D1 and D2. Your total utility is the sum of two subparts: Utotal = U1 + U2, where U1 only depends on decision D1 and U2 only depends on decision D2.
(a) Consider the following decision network:
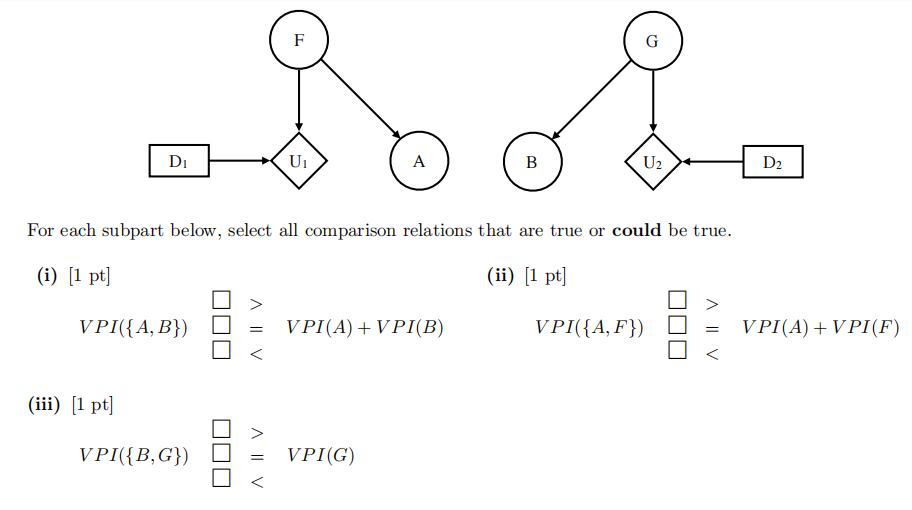
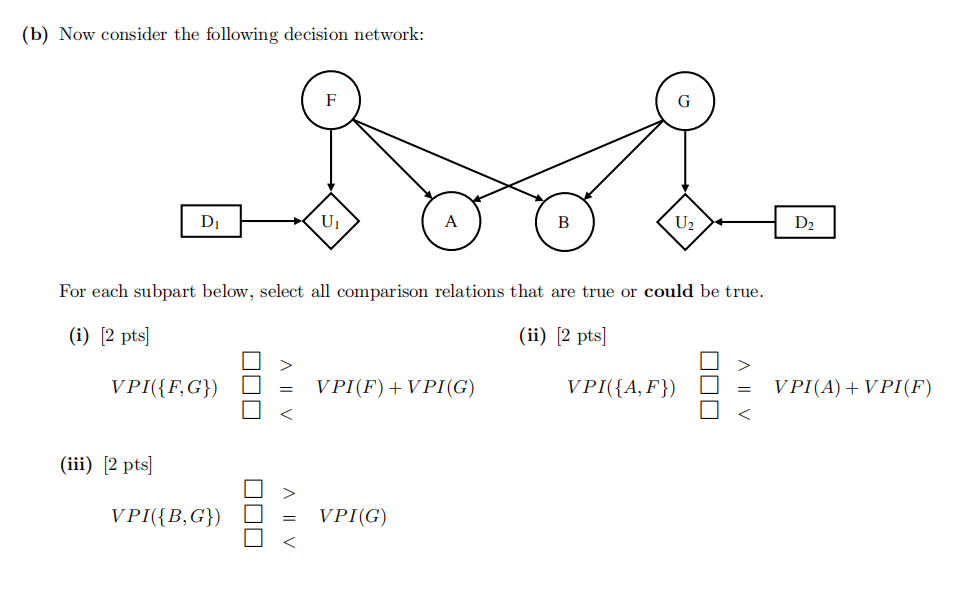
(c) Select all statements that are true. For the fifirst two statements, consider the decision network above.
□ If A, B are independent, then V P I(B) = 0
□ If A, B are guaranteed to be dependent, then V P I(B) > 0
□ In general, Gibbs Sampling can estimate the probabilities used when calculating VPI
□ In general, Particle Filtering can estimate the probabilities used when calculating VPI

更多代写:haskhell程序代写 Econfinal quiz代考 英国宏观经济代考 History代写essay Informative Speech代写 数学考试代考
